mirror of
https://github.com/chidiwilliams/buzz.git
synced 2026-03-14 14:45:46 +01:00
987 add localized documentation (#1058)
This commit is contained in:
parent
8ff3f79789
commit
2b974ea1f0
13 changed files with 528 additions and 33 deletions
|
|
@ -5,8 +5,11 @@ sidebar_position: 5
|
|||
|
||||
### 1. Where are the models stored?
|
||||
|
||||
The models are stored in `~/.cache/Buzz` (Linux), `~/Library/Caches/Buzz`
|
||||
(Mac OS) or `%USERPROFILE%\AppData\Local\Buzz\Buzz\Cache` (Windows).
|
||||
The models are stored:
|
||||
|
||||
- Linux: `~/.cache/Buzz`
|
||||
- Mac OS: `~/Library/Caches/Buzz`
|
||||
- Windows: `%USERPROFILE%\AppData\Local\Buzz\Buzz\Cache`
|
||||
|
||||
Paste the location in your file manager to access the models.
|
||||
|
||||
|
|
@ -21,15 +24,16 @@ Buzz also supports using OpenAI API to do speech recognition on a remote server.
|
|||
To transcribe system audio you need to configure virtual audio device and connect output from the applications you want to transcribe to this virtual speaker. After that you can select it as source in the Buzz. See [Usage](https://chidiwilliams.github.io/buzz/docs/usage/live_recording) section for more details.
|
||||
|
||||
Relevant tools:
|
||||
|
||||
- Mac OS - [BlackHole](https://github.com/ExistentialAudio/BlackHole).
|
||||
- Windows - [VB CABLE](https://vb-audio.com/Cable/)
|
||||
- Linux - [PulseAudio Volume Control](https://wiki.ubuntu.com/record_system_sound)
|
||||
|
||||
### 4. What model should I use?
|
||||
|
||||
Model size to use will depend on your hardware and use case. Smaller models will work faster but will have more inaccuracies. Larger models will be more accurate but will require more powerful hardware or longer time to transcribe.
|
||||
Model size to use will depend on your hardware and use case. Smaller models will work faster but will have more inaccuracies. Larger models will be more accurate but will require more powerful hardware or longer time to transcribe.
|
||||
|
||||
When choosing among large models consider the following. "Large" is the first released older model, "Large-V2" is later updated model with better accuracy, for some languages considered the most robust and stable. "Large-V3" is the latest model with the best accuracy in many cases, but some times can hallucinate or invent words that were never in the audio. "Turbo" model tries to get a good balance between speed and accuracy. The only sure way to know what model best suits your needs is to test them all in your language.
|
||||
When choosing among large models consider the following. "Large" is the first released older model, "Large-V2" is later updated model with better accuracy, for some languages considered the most robust and stable. "Large-V3" is the latest model with the best accuracy in many cases, but some times can hallucinate or invent words that were never in the audio. "Turbo" model tries to get a good balance between speed and accuracy. The only sure way to know what model best suits your needs is to test them all in your language.
|
||||
|
||||
### 5. How to get GPU acceleration for faster transcription?
|
||||
|
||||
|
|
@ -61,12 +65,12 @@ If that does not help, check the log file for errors and [report the issue](http
|
|||
|
||||
### 9. Where can I get latest development version?
|
||||
|
||||
Latest development version will have latest bug fixes and most recent features. If you feel a bit adventurous it is recommended to try the latest development version as they needs some testing before they get released to everybody.
|
||||
Latest development version will have latest bug fixes and most recent features. If you feel a bit adventurous it is recommended to try the latest development version as they needs some testing before they get released to everybody.
|
||||
|
||||
Linux users can get the latest version with this command `sudo snap install buzz --edge`
|
||||
- **Linux** users can get the latest version with this command `sudo snap install buzz --edge`
|
||||
|
||||
For other platforms do the following:
|
||||
- Go to the [build section](https://github.com/chidiwilliams/buzz/actions/workflows/ci.yml?query=branch%3Amain)
|
||||
- Click on the link to the latest build
|
||||
- Scroll down to the artifacts section in the build page
|
||||
- Download the installation file. Please note that you need to be logged in the Github to see the download links.
|
||||
- **For other** platforms do the following:
|
||||
1. Go to the [build section](https://github.com/chidiwilliams/buzz/actions/workflows/ci.yml?query=branch%3Amain)
|
||||
2. Click on the link to the latest build
|
||||
3. Scroll down to the artifacts section in the build page
|
||||
4. Download the installation file. Please note that you need to be logged in the Github to see the download links.
|
||||
|
|
|
|||
|
|
@ -9,9 +9,9 @@ Open the Preferences window from the Menu bar, or click `Ctrl/Cmd + ,`.
|
|||
|
||||
### OpenAI API preferences
|
||||
|
||||
**API Key** - key to authenticate your requests to OpenAI API. To get API key from OpenAI see [this article](https://help.openai.com/en/articles/4936850-where-do-i-find-my-openai-api-key).
|
||||
**API Key** - key to authenticate your requests to OpenAI API. To get API key from OpenAI see [this article](https://help.openai.com/en/articles/4936850-where-do-i-find-my-openai-api-key).
|
||||
|
||||
**Base Url** - By default all requests are sent to API provided by OpenAI company. Their api url is `https://api.openai.com/v1/`. Compatible APIs are also provided by other companies. List of available API urls you can find on [discussion page](https://github.com/chidiwilliams/buzz/discussions/827)
|
||||
**Base URL** - By default all requests are sent to API provided by OpenAI company. Their API URL is `https://api.openai.com/v1/`. Compatible APIs are also provided by other companies. List of available API URLs you can find on [discussion page](https://github.com/chidiwilliams/buzz/discussions/827)
|
||||
|
||||
### Default export file name
|
||||
|
||||
|
|
@ -21,34 +21,34 @@ as `Input Filename (transcribed on 19-Sep-2023 20-39-25).txt` by default.
|
|||
|
||||
Available variables:
|
||||
|
||||
| Key | Description | Example |
|
||||
|-------------------|-------------------------------------------|----------------------------------------------------------------|
|
||||
| Key | Description | Example |
|
||||
| ----------------- | ----------------------------------------- | ---------------------------------------------------------------- |
|
||||
| `input_file_name` | File name of the imported file | `audio` (e.g. if the imported file path was `/path/to/audio.wav` |
|
||||
| `task` | Transcription task | `transcribe`, `translate` |
|
||||
| `language` | Language code | `en`, `fr`, `yo`, etc. |
|
||||
| `model_type` | Model type | `Whisper`, `Whisper.cpp`, `Faster Whisper`, etc. |
|
||||
| `model_size` | Model size | `tiny`, `base`, `small`, `medium`, `large`, etc. |
|
||||
| `date_time` | Export time (format: `%d-%b-%Y %H-%M-%S`) | `19-Sep-2023 20-39-25` |
|
||||
| `task` | Transcription task | `transcribe`, `translate` |
|
||||
| `language` | Language code | `en`, `fr`, `yo`, etc. |
|
||||
| `model_type` | Model type | `Whisper`, `Whisper.cpp`, `Faster Whisper`, etc. |
|
||||
| `model_size` | Model size | `tiny`, `base`, `small`, `medium`, `large`, etc. |
|
||||
| `date_time` | Export time (format: `%d-%b-%Y %H-%M-%S`) | `19-Sep-2023 20-39-25` |
|
||||
|
||||
### Live transcript exports
|
||||
|
||||
Live transcription export can be used to integrate Buzz with other applications like OBS Studio.
|
||||
Live transcription export can be used to integrate Buzz with other applications like OBS Studio.
|
||||
When enabled, live text transcripts will be exported to a text file as they get generated and translated.
|
||||
|
||||
If AI translation is enabled for live recordings, the translated text will also be exported to the text file.
|
||||
Filename for the translated text will end with `.translated.txt`.
|
||||
If AI translation is enabled for live recordings, the translated text will also be exported to the text file.
|
||||
Filename for the translated text will end with `.translated.txt`.
|
||||
|
||||
### Live transcription mode
|
||||
|
||||
Three transcription modes are available:
|
||||
|
||||
**Append below** - New sentences will be added below existing with an empty space between them.
|
||||
**Append below** - New sentences will be added below existing with an empty space between them.
|
||||
Last sentence will be at the bottom.
|
||||
|
||||
**Append above** - New sentences will be added above existing with an empty space between them.
|
||||
**Append above** - New sentences will be added above existing with an empty space between them.
|
||||
Last sentence will be at the top.
|
||||
|
||||
**Append and correct** - New sentences will be added at the end of existing transcript without extra spaces between.
|
||||
**Append and correct** - New sentences will be added at the end of existing transcript without extra spaces between.
|
||||
This mode will also try to correct errors at the end of previously transcribed sentences. This mode requires more
|
||||
processing power and more powerful hardware to work.
|
||||
|
||||
|
|
@ -78,17 +78,17 @@ Alternatively you can set environment variables in your OS settings. See [this g
|
|||
|
||||
### Available variables
|
||||
|
||||
**BUZZ_WHISPERCPP_N_THREADS** - Number of threads to use for Whisper.cpp model. Default is `4`.
|
||||
**BUZZ_WHISPERCPP_N_THREADS** - Number of threads to use for Whisper.cpp model. Default is `4`.
|
||||
|
||||
On a laptop with 16 threads setting `BUZZ_WHISPERCPP_N_THREADS=8` leads to some 15% speedup in transcription time.
|
||||
Increasing number of threads even more will lead in slower transcription time as results from parallel threads has to be
|
||||
On a laptop with 16 threads setting `BUZZ_WHISPERCPP_N_THREADS=8` leads to some 15% speedup in transcription time.
|
||||
Increasing number of threads even more will lead in slower transcription time as results from parallel threads has to be
|
||||
combined to produce the final answer.
|
||||
|
||||
**BUZZ_TRANSLATION_API_BASE_URl** - Base URL of OpenAI compatible API to use for translation.
|
||||
**BUZZ_TRANSLATION_API_BASE_URL** - Base URL of OpenAI compatible API to use for translation.
|
||||
|
||||
**BUZZ_TRANSLATION_API_KEY** - Api key of OpenAI compatible API to use for translation.
|
||||
|
||||
**BUZZ_MODEL_ROOT** - Root directory to store model files.
|
||||
**BUZZ_MODEL_ROOT** - Root directory to store model files.
|
||||
Defaults to [user_cache_dir](https://pypi.org/project/platformdirs/).
|
||||
|
||||
**BUZZ_FAVORITE_LANGUAGES** - Coma separated list of supported language codes to show on top of language list.
|
||||
|
|
|
|||
|
|
@ -31,7 +31,22 @@ const config = {
|
|||
// to replace "en" with "zh-Hans".
|
||||
i18n: {
|
||||
defaultLocale: 'en',
|
||||
locales: ['en'],
|
||||
locales: ['en', 'zh'],
|
||||
path: 'i18n',
|
||||
localeConfigs: {
|
||||
en: {
|
||||
label: 'English',
|
||||
direction: 'ltr',
|
||||
htmlLang: 'en-US',
|
||||
path: 'en',
|
||||
},
|
||||
zh: {
|
||||
label: 'Chinese',
|
||||
direction: 'ltr',
|
||||
htmlLang: 'zh-CN',
|
||||
path: 'zh',
|
||||
},
|
||||
},
|
||||
},
|
||||
|
||||
presets: [
|
||||
|
|
@ -70,12 +85,15 @@ const config = {
|
|||
position: 'left',
|
||||
label: 'Docs',
|
||||
},
|
||||
// {to: '/blog', label: 'Blog', position: 'left'},
|
||||
{
|
||||
href: 'https://github.com/chidiwilliams/buzz',
|
||||
label: 'GitHub',
|
||||
position: 'right',
|
||||
},
|
||||
{
|
||||
type: 'localeDropdown',
|
||||
position: 'left',
|
||||
},
|
||||
],
|
||||
},
|
||||
prism: {
|
||||
|
|
|
|||
87
docs/i18n/zh/docusaurus-plugin-content-docs/current/cli.md
Normal file
87
docs/i18n/zh/docusaurus-plugin-content-docs/current/cli.md
Normal file
|
|
@ -0,0 +1,87 @@
|
|||
---
|
||||
title: 命令行界面 (CLI)
|
||||
sidebar_position: 5
|
||||
---
|
||||
|
||||
## 命令
|
||||
|
||||
### `增加`
|
||||
|
||||
启动一个新的转录任务。
|
||||
|
||||
```
|
||||
Usage: buzz add [options] [file url file...]
|
||||
|
||||
Options:
|
||||
-t, --task <task> The task to perform. Allowed: translate,
|
||||
transcribe. Default: transcribe.
|
||||
-m, --model-type <model-type> Model type. Allowed: whisper, whispercpp,
|
||||
huggingface, fasterwhisper, openaiapi. Default:
|
||||
whisper.
|
||||
-s, --model-size <model-size> Model size. Use only when --model-type is
|
||||
whisper, whispercpp, or fasterwhisper. Allowed:
|
||||
tiny, base, small, medium, large. Default:
|
||||
tiny.
|
||||
--hfid <id> Hugging Face model ID. Use only when
|
||||
--model-type is huggingface. Example:
|
||||
"openai/whisper-tiny"
|
||||
-l, --language <code> Language code. Allowed: af (Afrikaans), am
|
||||
(Amharic), ar (Arabic), as (Assamese), az
|
||||
(Azerbaijani), ba (Bashkir), be (Belarusian),
|
||||
bg (Bulgarian), bn (Bengali), bo (Tibetan), br
|
||||
(Breton), bs (Bosnian), ca (Catalan), cs
|
||||
(Czech), cy (Welsh), da (Danish), de (German),
|
||||
el (Greek), en (English), es (Spanish), et
|
||||
(Estonian), eu (Basque), fa (Persian), fi
|
||||
(Finnish), fo (Faroese), fr (French), gl
|
||||
(Galician), gu (Gujarati), ha (Hausa), haw
|
||||
(Hawaiian), he (Hebrew), hi (Hindi), hr
|
||||
(Croatian), ht (Haitian Creole), hu
|
||||
(Hungarian), hy (Armenian), id (Indonesian), is
|
||||
(Icelandic), it (Italian), ja (Japanese), jw
|
||||
(Javanese), ka (Georgian), kk (Kazakh), km
|
||||
(Khmer), kn (Kannada), ko (Korean), la (Latin),
|
||||
lb (Luxembourgish), ln (Lingala), lo (Lao), lt
|
||||
(Lithuanian), lv (Latvian), mg (Malagasy), mi
|
||||
(Maori), mk (Macedonian), ml (Malayalam), mn
|
||||
(Mongolian), mr (Marathi), ms (Malay), mt
|
||||
(Maltese), my (Myanmar), ne (Nepali), nl
|
||||
(Dutch), nn (Nynorsk), no (Norwegian), oc
|
||||
(Occitan), pa (Punjabi), pl (Polish), ps
|
||||
(Pashto), pt (Portuguese), ro (Romanian), ru
|
||||
(Russian), sa (Sanskrit), sd (Sindhi), si
|
||||
(Sinhala), sk (Slovak), sl (Slovenian), sn
|
||||
(Shona), so (Somali), sq (Albanian), sr
|
||||
(Serbian), su (Sundanese), sv (Swedish), sw
|
||||
(Swahili), ta (Tamil), te (Telugu), tg (Tajik),
|
||||
th (Thai), tk (Turkmen), tl (Tagalog), tr
|
||||
(Turkish), tt (Tatar), uk (Ukrainian), ur
|
||||
(Urdu), uz (Uzbek), vi (Vietnamese), yi
|
||||
(Yiddish), yo (Yoruba), zh (Chinese). Leave
|
||||
empty to detect language.
|
||||
-p, --prompt <prompt> Initial prompt.
|
||||
-wt, --word-timestamps Generate word-level timestamps. (available since 1.2.0)
|
||||
--openai-token <token> OpenAI access token. Use only when
|
||||
--model-type is openaiapi. Defaults to your
|
||||
previously saved access token, if one exists.
|
||||
--srt Output result in an SRT file.
|
||||
--vtt Output result in a VTT file.
|
||||
--txt Output result in a TXT file.
|
||||
--hide-gui Hide the main application window. (available since 1.2.0)
|
||||
-h, --help Displays help on commandline options.
|
||||
--help-all Displays help including Qt specific options.
|
||||
-v, --version Displays version information.
|
||||
|
||||
Arguments:
|
||||
files or urls Input file paths or urls. Url import availalbe since 1.2.0.
|
||||
```
|
||||
|
||||
**示例**:
|
||||
|
||||
```shell
|
||||
# 使用 OpenAI Whisper API 将两个 MP3 文件从法语翻译为英语
|
||||
buzz add --task translate --language fr --model-type openaiapi /Users/user/Downloads/1b3b03e4-8db5-ea2c-ace5-b71ff32e3304.mp3 /Users/user/Downloads/koaf9083k1lkpsfdi0.mp3
|
||||
|
||||
# 使用 Whisper.cpp "small" 模型转录一个 MP4 文件,并立即导出为 SRT 和 VTT 文件
|
||||
buzz add --task transcribe --model-type whispercpp --model-size small --prompt "My initial prompt(我的初始提示)" --srt --vtt /Users/user/Downloads/buzz/1b3b03e4-8db5-ea2c-ace5-b71ff32e3304.mp4
|
||||
```
|
||||
94
docs/i18n/zh/docusaurus-plugin-content-docs/current/faq.md
Normal file
94
docs/i18n/zh/docusaurus-plugin-content-docs/current/faq.md
Normal file
|
|
@ -0,0 +1,94 @@
|
|||
---
|
||||
title: 常见问题(FAQ)
|
||||
sidebar_position: 5
|
||||
---
|
||||
|
||||
### 1. 模型存储在哪里?
|
||||
|
||||
模型存储在以下位置:
|
||||
|
||||
- Linux: `~/.cache/Buzz`
|
||||
- Mac OS: `~/Library/Caches/Buzz`
|
||||
- Windows: `%USERPROFILE%\AppData\Local\Buzz\Buzz\Cache`
|
||||
|
||||
将上述路径粘贴到文件管理器中即可访问模型。
|
||||
|
||||
### 2. 如果转录速度太慢,我可以尝试什么?
|
||||
|
||||
语音识别需要大量计算资源,您可以尝试使用较小的 Whisper 模型,或者使用 Whisper.cpp 模型在本地计算机上运行语音识别。如果您的计算机配备了至少 6GB VRAM 的 GPU,可以尝试使用 Faster Whisper 模型。
|
||||
|
||||
Buzz 还支持使用 OpenAI API 在远程服务器上进行语音识别。要使用此功能,您需要在“偏好设置”中设置 OpenAI API 密钥。详情请参见 [偏好设置](https://chidiwilliams.github.io/buzz/docs/preferences) 部分。
|
||||
|
||||
### 3. 如何录制系统音频?
|
||||
|
||||
要转录系统音频,您需要配置虚拟音频设备,并将希望转录的应用程序输出连接到该虚拟扬声器。然后,您可以在 Buzz 中选择该设备作为音源。详情请参见 [使用指南](https://chidiwilliams.github.io/buzz/docs/usage/live_recording) 部分。
|
||||
|
||||
相关工具:
|
||||
|
||||
- Mac OS - [BlackHole](https://github.com/ExistentialAudio/BlackHole)
|
||||
- Windows - [VB CABLE](https://vb-audio.com/Cable/)
|
||||
- Linux - [PulseAudio Volume Control](https://wiki.ubuntu.com/record_system_sound)
|
||||
|
||||
### 4. 我应该使用哪个模型?
|
||||
|
||||
选择模型大小取决于您的硬件和使用场景。较小的模型运行速度更快,但准确性较低;较大的模型更准确,但需要更强的硬件或更长的转录时间。
|
||||
|
||||
在选择大模型时,请参考以下信息:
|
||||
|
||||
- **“Large”** 是最早发布的模型
|
||||
- **“Large-V2”** 是后续改进版,准确率更高,被认为是某些语言中最稳定的选择
|
||||
- **“Large-V3”** 是最新版本,在许多情况下准确性最佳,但有时可能会产生错误的单词
|
||||
- **“Turbo”** 模型在速度和准确性之间取得了良好平衡
|
||||
|
||||
最好的方法是测试所有模型,以找到最适合您语言的选项。
|
||||
|
||||
### 5. 如何使用 GPU 加速以提高转录速度?
|
||||
|
||||
- 在 **Linux** 上,Nvidia GPU 受支持,可直接使用 GPU 加速。如果遇到问题,请安装 [CUDA 12](https://developer.nvidia.com/cuda-downloads)、[cuBLAS](https://developer.nvidia.com/cublas) 和 [cuDNN](https://developer.nvidia.com/cudnn)。
|
||||
- 在 **Windows** 上,请参阅[此说明](https://github.com/chidiwilliams/buzz/blob/main/CONTRIBUTING.md#gpu-support) 以启用 CUDA GPU 支持。
|
||||
- **Faster Whisper** 需要 CUDA 12,使用旧版 CUDA 的计算机将默认使用 CPU。
|
||||
|
||||
### 6. 如何修复 `Unanticipated host error[PaErrorCode-9999]`?
|
||||
|
||||
请检查系统设置,确保没有阻止应用访问麦克风。
|
||||
|
||||
- **Windows** 用户请检查“设置 -> 隐私 -> 麦克风”,确保 Buzz 有权限使用麦克风。
|
||||
- 参考此视频的 [方法 1](https://www.youtube.com/watch?v=eRcCYgOuSYQ)。
|
||||
- **方法 2** 无需卸载防病毒软件,但可以尝试暂时禁用,或检查是否有相关设置阻止 Buzz 访问麦克风。
|
||||
|
||||
### 7. 可以在没有互联网的计算机上使用 Buzz 吗?
|
||||
|
||||
是的,您可以在离线计算机上使用 Buzz,但需要在另一台联网计算机上下载所需模型,并手动将其移动到离线计算机。
|
||||
|
||||
最简单的方法是:
|
||||
|
||||
1. 打开“帮助 -> 偏好设置 -> 模型”
|
||||
2. 下载所需的模型
|
||||
3. 点击“显示文件位置”按钮,打开存储模型的文件夹
|
||||
4. 将该模型文件夹复制到离线计算机的相同位置
|
||||
|
||||
例如,在 Linux 上,模型存储在 `~/.cache/Buzz/models` 目录中。
|
||||
|
||||
### 8. Buzz 崩溃了,怎么办?
|
||||
|
||||
如果模型下载不完整或损坏,Buzz 可能会崩溃。尝试删除已下载的模型文件,然后重新下载。
|
||||
|
||||
如果问题仍然存在,请检查日志文件并[报告问题](https://github.com/chidiwilliams/buzz/issues),以便我们修复。日志文件位置如下:
|
||||
|
||||
- Mac OS: `~/Library/Logs/Buzz`
|
||||
- Windows: `%USERPROFILE%\AppData\Local\Buzz\Buzz\Logs`
|
||||
- Linux: 在终端运行 Buzz 查看相关错误信息。
|
||||
|
||||
### 9. 哪里可以获取最新的开发版本?
|
||||
|
||||
最新的开发版本包含最新的错误修复和新功能。如果您喜欢尝试新功能,可以下载最新的开发版本进行测试。
|
||||
|
||||
- **Linux** 用户可以运行以下命令获取最新版本:
|
||||
```sh
|
||||
sudo snap install buzz --edge
|
||||
```
|
||||
- **其他平台** 请按以下步骤操作:
|
||||
1. 访问 [构建页面](https://github.com/chidiwilliams/buzz/actions/workflows/ci.yml?query=branch%3Amain)
|
||||
2. 点击最新构建的链接
|
||||
3. 在构建页面向下滚动到“Artifacts”部分
|
||||
4. 下载安装文件(请注意,您需要登录 GitHub 才能看到下载链接)
|
||||
28
docs/i18n/zh/docusaurus-plugin-content-docs/current/index.md
Normal file
28
docs/i18n/zh/docusaurus-plugin-content-docs/current/index.md
Normal file
|
|
@ -0,0 +1,28 @@
|
|||
---
|
||||
title: Introduction
|
||||
sidebar_position: 1
|
||||
---
|
||||
|
||||
在您的个人电脑上离线转录和翻译音频。由 OpenAI 的 [Whisper](https://github.com/openai/whisper) 提供支持。
|
||||
|
||||

|
||||
[](https://github.com/chidiwilliams/buzz/actions/workflows/ci.yml)
|
||||
[](https://codecov.io/github/chidiwilliams/buzz)
|
||||

|
||||
[](https://GitHub.com/chidiwilliams/buzz/releases/)
|
||||
|
||||
<blockquote>
|
||||
<p>在 App Store 下载运行的性能更佳。 获得外观更整洁、音频播放、拖放导入、转录编辑、搜索等功能的原生Mac版本。</p>
|
||||
<a href="https://apps.apple.com/cn/app/buzz-captions/id6446018936?mt=12&itsct=apps_box_badge&itscg=30200"><img src="https://toolbox.marketingtools.apple.com/api/badges/download-on-the-mac-app-store/black/zh-cn?size=250x83" alt="在 Mac App Store 下载" /></a>
|
||||
</blockquote>
|
||||
|
||||
## 功能
|
||||
|
||||
- 导入音频和视频文件,并将转录内容导出为 TXT、SRT 和 VTT 格式([演示](https://www.loom.com/share/cf263b099ac3481082bb56d19b7c87fe))
|
||||
- 从电脑麦克风转录和翻译为文本(资源密集型,可能无法实时完成,[演示](https://www.loom.com/share/564b753eb4d44b55b985b8abd26b55f7))
|
||||
- 支持 [Whisper](https://github.com/openai/whisper#available-models-and-languages)、
|
||||
[Whisper.cpp](https://github.com/ggerganov/whisper.cpp)、[Faster Whisper](https://github.com/guillaumekln/faster-whisper)、
|
||||
[Whisper 兼容的 Hugging Face 模型](https://huggingface.co/models?other=whisper) 和
|
||||
[OpenAI Whisper API](https://platform.openai.com/docs/api-reference/introduction)
|
||||
- [命令行界面](#命令行界面)
|
||||
- 支持 Mac、Windows 和 Linux
|
||||
|
|
@ -0,0 +1,51 @@
|
|||
---
|
||||
title: 安装
|
||||
sidebar_position: 2
|
||||
---
|
||||
|
||||
要安装 Buzz,请下载适用于您操作系统的[最新版本](https://github.com/chidiwilliams/buzz/releases/latest)。Buzz 支持 **Mac**(Intel)、**Windows** 和 **Linux** 系统。(对于 Apple Silicon 用户,请参阅 [App Store 版本](https://apps.apple.com/us/app/buzz-captions/id6446018936?mt=12&itsct=apps_box_badge&itscg=30200)。)
|
||||
|
||||
## macOS(Intel,macOS 11.7 及更高版本)
|
||||
|
||||
通过 [brew](https://brew.sh/) 安装:
|
||||
|
||||
```shell
|
||||
brew install --cask buzz
|
||||
```
|
||||
|
||||
或者,下载并运行 `Buzz-x.y.z.dmg` 文件。
|
||||
|
||||
对于 Mac Silicon 用户(以及希望在 Mac Intel 上获得更好体验的用户),
|
||||
请从 App Store 下载 [Buzz Captions](https://apps.apple.com/us/app/buzz-captions/id6446018936?mt=12&itsct=apps_box_badge&itscg=30200)。
|
||||
|
||||
## Windows(Windows 10 及更高版本)
|
||||
|
||||
下载并运行 `Buzz-x.y.z.exe` 文件。
|
||||
|
||||
## Linux
|
||||
|
||||
```shell
|
||||
sudo apt-get install libportaudio2 libcanberra-gtk-module libcanberra-gtk3-module
|
||||
sudo snap install buzz
|
||||
sudo snap connect buzz:audio-record
|
||||
sudo snap connect buzz:password-manager-service
|
||||
sudo snap connect buzz:pulseaudio
|
||||
sudo snap connect buzz:removable-media
|
||||
```
|
||||
|
||||
[](https://snapcraft.io/buzz)
|
||||
|
||||
或者,在 Ubuntu 20.04 及更高版本上,安装依赖项:
|
||||
|
||||
```shell
|
||||
sudo apt-get install libportaudio2
|
||||
```
|
||||
|
||||
然后,下载并解压 `Buzz-x.y.z-unix.tar.gz` 文件。
|
||||
|
||||
## PyPI
|
||||
|
||||
```shell
|
||||
pip install buzz-captions
|
||||
python -m buzz
|
||||
```
|
||||
|
|
@ -0,0 +1,94 @@
|
|||
---
|
||||
title: 偏好设置
|
||||
sidebar_position: 4
|
||||
---
|
||||
|
||||
从菜单栏打开偏好设置窗口,或点击 `Ctrl/Cmd + ,`。
|
||||
|
||||
## 常规偏好设置
|
||||
|
||||
### OpenAI API 偏好设置
|
||||
|
||||
**API 密钥** - 用于验证 OpenAI API 请求的密钥。要获取 OpenAI 的 API 密钥,请参阅 [此文章](https://help.openai.com/en/articles/4936850-where-do-i-find-my-openai-api-key)。
|
||||
|
||||
**基础 URL** - 默认情况下,所有请求都会发送到 OpenAI 公司提供的 API。他们的 API URL 是 `https://api.openai.com/v1/`。其他公司也提供了兼容的 API。你可以在 [讨论页面](https://github.com/chidiwilliams/buzz/discussions/827) 找到可用的 API URL 列表。
|
||||
|
||||
### 默认导出文件名
|
||||
|
||||
设置文件识别的默认导出文件名。例如,值为 `{{ input_file_name }} ({{ task }}d on {{ date_time }})` 时,TXT 导出文件将默认保存为`Input Filename (transcribed on 19-Sep-2023 20-39-25).txt`(输入文件名 (转录于 19-Sep-2023 20-39-25).txt)。
|
||||
|
||||
可用变量:
|
||||
|
||||
| 键 | 描述 | 示例 |
|
||||
| ----------------- | ------------------------------------- | ---------------------------------------------------------- |
|
||||
| `input_file_name` | 导入文件的文件名 | `audio`(例如,如果导入的文件路径是 `/path/to/audio.wav`) |
|
||||
| `task` | 转录任务 | `transcribe`, `translate` |
|
||||
| `language` | 语言代码 | `en`, `fr`, `yo` 等 |
|
||||
| `model_type` | 模型类型 | `Whisper`, `Whisper.cpp`, `Faster Whisper` 等 |
|
||||
| `model_size` | 模型大小 | `tiny`, `base`, `small`, `medium`, `large` 等 |
|
||||
| `date_time` | 导出时间(格式:`%d-%b-%Y %H-%M-%S`) | `19-Sep-2023 20-39-25` |
|
||||
|
||||
### 实时识别导出
|
||||
|
||||
实时识别导出可用于将 Buzz 与其他应用程序(如 OBS Studio)集成。
|
||||
启用后,实时文本识别将在生成和翻译时导出到文本文件。
|
||||
|
||||
如果为实时录音启用了 AI 翻译,翻译后的文本也将导出到文本文件。
|
||||
翻译文本的文件名将以 `.translated.txt` 结尾。
|
||||
|
||||
### 实时识别模式
|
||||
|
||||
有三种转识别式可用:
|
||||
|
||||
**下方追加** - 新句子将在现有内容下方添加,并在它们之间留有空行。最后一句话将位于底部。
|
||||
|
||||
**上方追加** - 新句子将在现有内容上方添加,并在它们之间留有空行。最后一句话将位于顶部。
|
||||
|
||||
**追加并修正** - 新句子将在现有转录内容的末尾添加,中间不留空行。此模式还会尝试修正之前转录句子末尾的错误。此模式需要更多的处理能力和更强大的硬件支持。
|
||||
|
||||
## 高级偏好设置
|
||||
|
||||
为了简化新用户的偏好设置部分,一些更高级的设置可以通过操作系统环境变量进行配置。在启动 Buzz 之前,请在操作系统中设置必要的环境变量,或创建一个脚本来设置它们。
|
||||
|
||||
在 MacOS 和 Linux 上,创建 `run_buzz.sh`,内容如下:
|
||||
|
||||
```bash
|
||||
#!/bin/bash
|
||||
export VARIABLE=value
|
||||
export SOME_OTHER_VARIABLE=some_other_value
|
||||
buzz
|
||||
```
|
||||
|
||||
在 Windows 上,创建 `run_buzz.bat`,内容如下:
|
||||
|
||||
```bat
|
||||
@echo off
|
||||
set VARIABLE=value
|
||||
set SOME_OTHER_VARIABLE=some_other_value
|
||||
"C:\Program Files (x86)\Buzz\Buzz.exe"
|
||||
```
|
||||
|
||||
或者,你可以在操作系统设置中设置环境变量。更多信息请参阅 [此指南](https://phoenixnap.com/kb/windows-set-environment-variable#ftoc-heading-4) 或 [此视频](https://www.youtube.com/watch?v=bEroNNzqlF4)。
|
||||
|
||||
### 可用变量
|
||||
|
||||
**BUZZ_WHISPERCPP_N_THREADS** - Whisper.cpp 模型使用的线程数。默认为 `4`。
|
||||
在具有 16 线程的笔记本电脑上,设置 `BUZZ_WHISPERCPP_N_THREADS=8` 可以使转录时间加快约 15%。
|
||||
进一步增加线程数会导致转录时间变慢,因为并行线程的结果需要合并以生成最终答案。
|
||||
|
||||
**BUZZ_TRANSLATION_API_BASE_URl** - 用于翻译的 OpenAI 兼容 API 的基础 URL。
|
||||
|
||||
**BUZZ_TRANSLATION_API_KEY** - 用于翻译的 OpenAI 兼容 API 的密钥。
|
||||
|
||||
**BUZZ_MODEL_ROOT** - 存储模型文件的根目录。
|
||||
默认为 [user_cache_dir](https://pypi.org/project/platformdirs/)。
|
||||
|
||||
**BUZZ_FAVORITE_LANGUAGES** - 以逗号分隔的支持语言代码列表,显示在语言列表顶部。
|
||||
|
||||
**BUZZ_LOCALE** - Buzz 用户界面使用的语言环境。默认为系统支持的语言环境之一。
|
||||
|
||||
**BUZZ_DOWNLOAD_COOKIEFILE** - 用于下载私有视频或绕过反机器人保护的 [cookiefile](https://github.com/yt-dlp/yt-dlp/wiki/FAQ#how-do-i-pass-cookies-to-yt-dlp) 的位置。
|
||||
|
||||
**BUZZ_FORCE_CPU** - 强制 Buzz 使用 CPU 而不是 GPU,适用于旧 GPU 较慢或 GPU 有问题的设置。示例用法:`BUZZ_FORCE_CPU=true`。自 `1.2.1` 版本起可用。
|
||||
|
||||
**BUZZ_MERGE_REGROUP_RULE** - 合并带有单词级时间戳的转录时使用的自定义重新分组规则。更多可用选项的信息请参阅 [stable-ts 仓库](https://github.com/jianfch/stable-ts?tab=readme-ov-file#regrouping-methods)。自 `1.3.0` 版本起可用。
|
||||
|
|
@ -0,0 +1,22 @@
|
|||
---
|
||||
title: File Import
|
||||
---
|
||||
|
||||
To import a file:
|
||||
|
||||
- Click Import Media File on the File menu (or the '+' icon on the toolbar, or **Command/Ctrl + O**).
|
||||
- Choose an audio or video file.
|
||||
- Select a task, language, and the model settings.
|
||||
- Click Run.
|
||||
- When the transcription status shows 'Completed', double-click on the row (or select the row and click the '⤢' icon) to
|
||||
open the transcription.
|
||||
|
||||
| Field | Options | Default | Description |
|
||||
|--------------------|---------------------|---------|----------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| Export As | "TXT", "SRT", "VTT" | "TXT" | Export file format |
|
||||
| Word-Level Timings | Off / On | Off | If checked, the transcription will generate a separate subtitle line for each word in the audio. Enabled only when "Export As" is set to "SRT" or "VTT". |
|
||||
| Extract speech | Off / On | Off | If checked, speech will be extracted to a separate audio tack to improve accuracy. Available since 1.3.0. |
|
||||
|
||||
(See the [Live Recording section](#live-recording) for more information about the task, language, and quality settings.)
|
||||
|
||||
[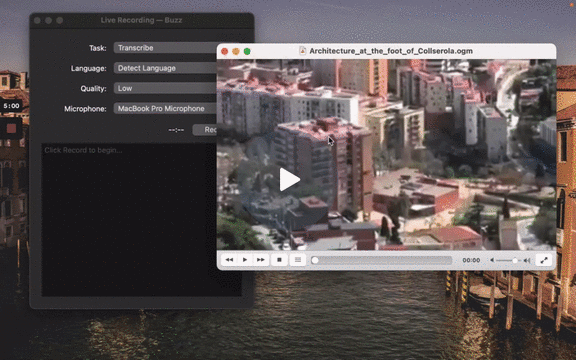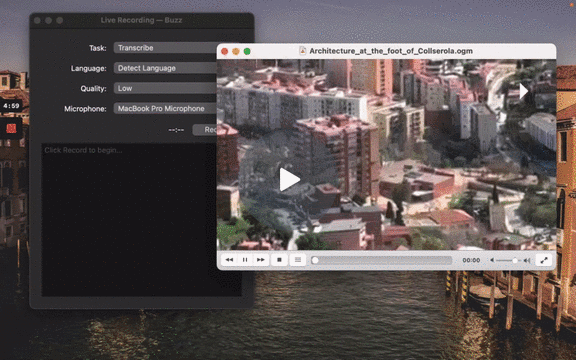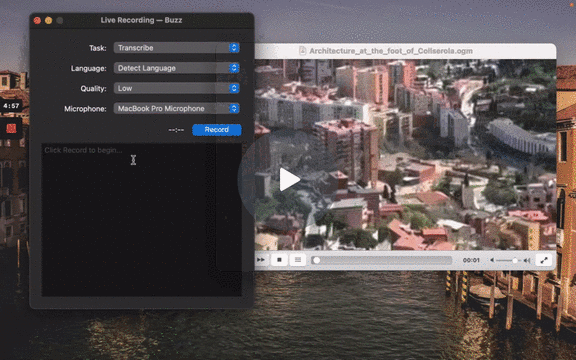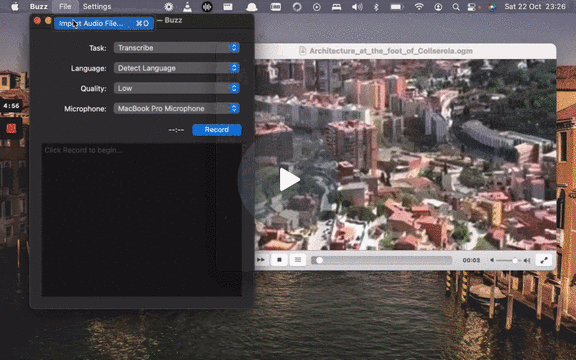](https://www.loom.com/share/cf263b099ac3481082bb56d19b7c87fe "Media File Import on Buzz")
|
||||
|
|
@ -0,0 +1,69 @@
|
|||
---
|
||||
title: Live Recording
|
||||
---
|
||||
|
||||
To start a live recording:
|
||||
|
||||
- Select a recording task, language, quality, and microphone.
|
||||
- Click Record.
|
||||
|
||||
> **Note:** Transcribing audio using the default Whisper model is resource-intensive. Consider using the Whisper.cpp
|
||||
> Tiny model to get real-time performance.
|
||||
|
||||
| Field | Options | Default | Description |
|
||||
|------------|------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| Task | "Transcribe", "Translate" | "Transcribe" | "Transcribe" converts the input audio into text in the selected language, while "Translate" converts it into text in English. |
|
||||
| Language | See [Whisper's documentation](https://github.com/openai/whisper#available-models-and-languages) for the full list of supported languages | "Detect Language" | "Detect Language" will try to detect the spoken language in the audio based on the first few seconds. However, selecting a language is recommended (if known) as it will improve transcription quality in many cases. |
|
||||
| Quality | "Very Low", "Low", "Medium", "High" | "Very Low" | The transcription quality determines the Whisper model used for transcription. "Very Low" uses the "tiny" model; "Low" uses the "base" model; "Medium" uses the "small" model; and "High" uses the "medium" model. The larger models produce higher-quality transcriptions, but require more system resources. See [Whisper's documentation](https://github.com/openai/whisper#available-models-and-languages) for more information about the models. |
|
||||
| Microphone | [Available system microphones] | [Default system microphone] | Microphone for recording input audio. |
|
||||
|
||||
[](https://www.loom.com/share/564b753eb4d44b55b985b8abd26b55f7 "Live Recording on Buzz")
|
||||
|
||||
### Record audio playing from computer (macOS)
|
||||
|
||||
To record audio playing from an application on your computer, you may install an audio loopback driver (a program that
|
||||
lets you create virtual audio devices). The rest of this guide will
|
||||
use [BlackHole](https://github.com/ExistentialAudio/BlackHole) on Mac, but you can use other alternatives for your
|
||||
operating system (
|
||||
see [LoopBeAudio](https://nerds.de/en/loopbeaudio.html), [LoopBack](https://rogueamoeba.com/loopback/),
|
||||
and [Virtual Audio Cable](https://vac.muzychenko.net/en/)).
|
||||
|
||||
1. Install [BlackHole via Homebrew](https://github.com/ExistentialAudio/BlackHole#option-2-install-via-homebrew)
|
||||
|
||||
```shell
|
||||
brew install blackhole-2ch
|
||||
```
|
||||
|
||||
2. Open Audio MIDI Setup from Spotlight or from `/Applications/Utilities/Audio Midi Setup.app`.
|
||||
|
||||
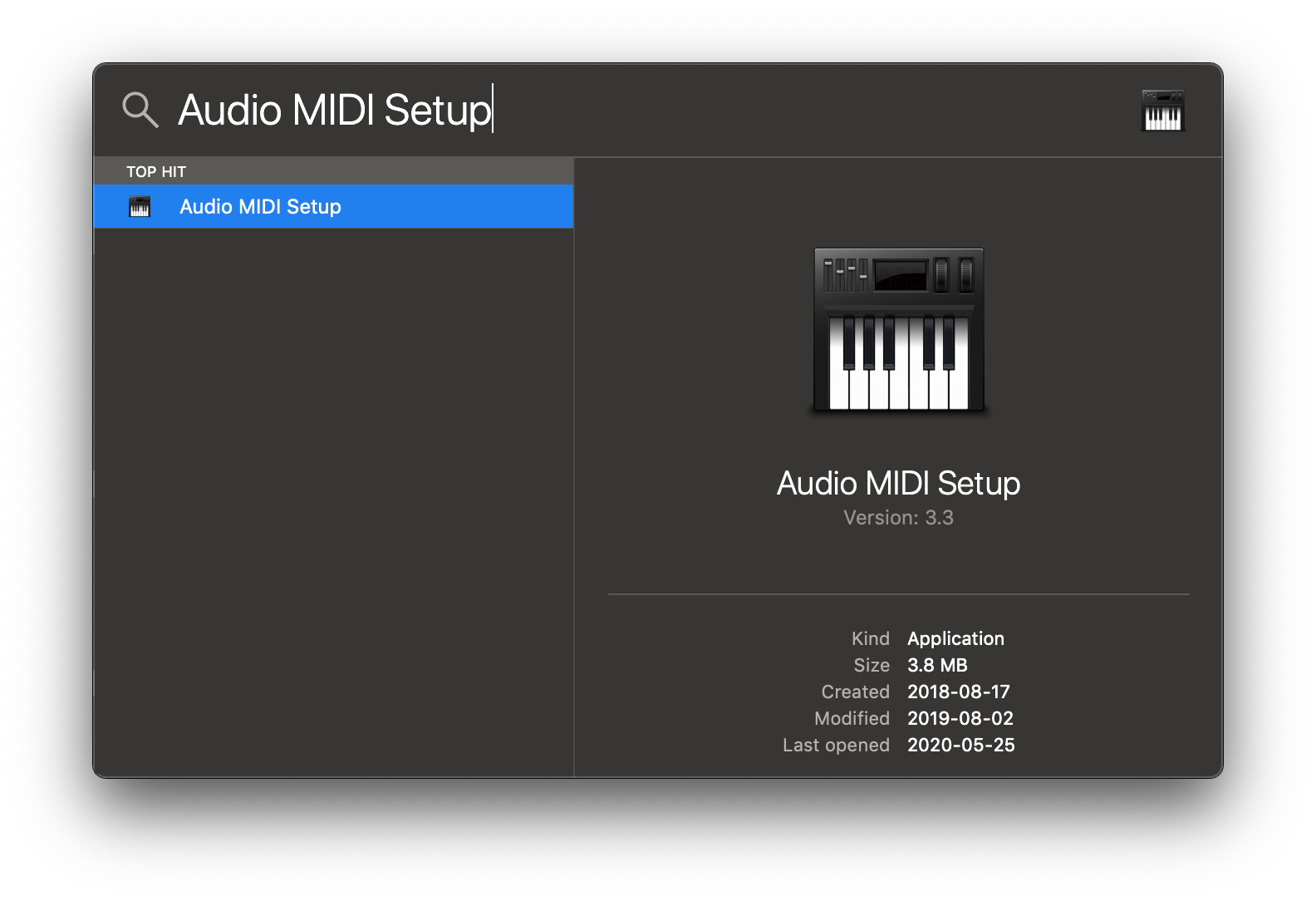
|
||||
|
||||
3. Click the '+' icon at the lower left corner and select 'Create Multi-Output Device'.
|
||||
|
||||

|
||||
|
||||
4. Add your default speaker and BlackHole to the multi-output device.
|
||||
|
||||
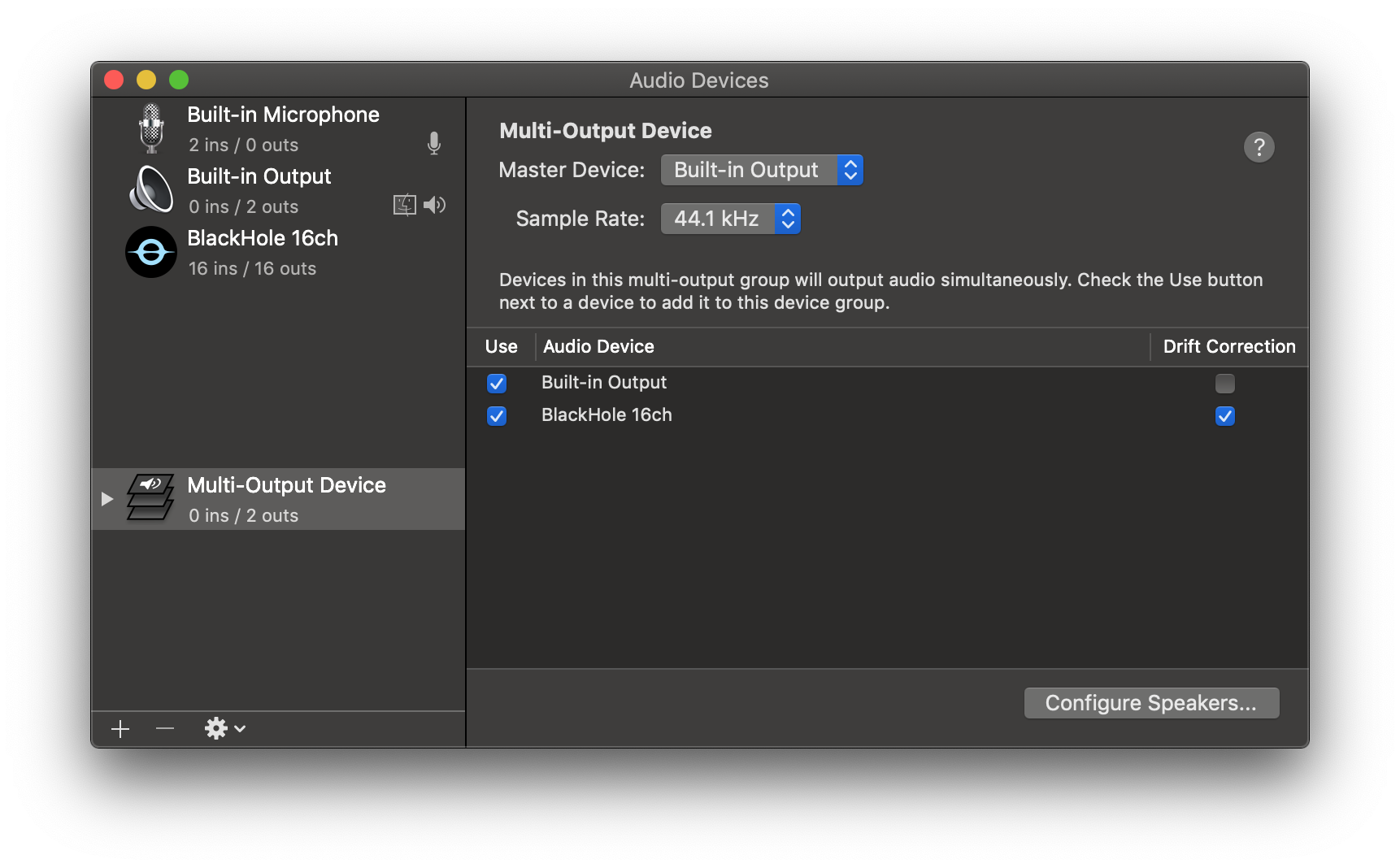
|
||||
|
||||
5. Select this multi-output device as your speaker (application or system-wide) to play audio into BlackHole.
|
||||
|
||||
6. Open Buzz, select BlackHole as your microphone, and record as before to see transcriptions from the audio playing
|
||||
through BlackHole.
|
||||
|
||||
### Record audio playing from computer (Windows)
|
||||
|
||||
To transcribe system audio you need to configure virtual audio device and connect output from the applications you whant to transcribe to this virtual speaker. After that you can select it as source in the Buzz.
|
||||
|
||||
1. Install [VB CABLE](https://vb-audio.com/Cable/) as virtual audio device.
|
||||
|
||||
2. Configure using Windows Sound settings. Right-click on the speaker icon in the system tray and select "Open Sound settings". In the "Choose your output device" dropdown select "CABLE Input" to send all system sound to the virtual device or use "Advanced sound options" to select application that will output their sound to this device.
|
||||
|
||||
### Record audio playing from computer (Linux)
|
||||
|
||||
As described on [Ubuntu Wiki](https://wiki.ubuntu.com/record_system_sound) on any Linux with pulse audio you can redirect application audio to a virtual speaker. After that you can select it as source in Buzz.
|
||||
|
||||
Overall steps:
|
||||
1. Launch application that will produce the sound you want to transcribe and start the playback. For example start a video in a media player.
|
||||
2. Launch Buzz and open Live recording screen, so you see the settings.
|
||||
3. Configure sound routing from the application you want to transcribe sound from to Buzz in `Recording tab` of the PulseAudio Volume Control (`pavucontrol`).
|
||||
|
|
@ -0,0 +1,17 @@
|
|||
---
|
||||
title: Translations
|
||||
---
|
||||
|
||||
Default `Translation` task uses Whisper model ability to translate to English. Since version `1.0.0` Buzz supports additional AI translations to any other language.
|
||||
|
||||
To use translation feature you will need to configure OpenAI API key and translation settings. Set OpenAI API ket in Preferences. Buzz also supports custom locally running translation AIs that support OpenAI API. For more information on locally running AIs see [ollama](https://ollama.com/blog/openai-compatibility) or [LM Studio](https://lmstudio.ai/). For information on available custom APIs see this [discussion thread](https://github.com/chidiwilliams/buzz/discussions/827)
|
||||
|
||||
To configure translation for Live recordings enable it in Advances settings dialog of the Live Recording settings. Enter AI model to use and prompt with instructions for the AI on how to translate. Translation option is also available for files that already have speech recognised. Use Translate button on transcription viewer toolbar.
|
||||
|
||||
For AI to know how to translate enter translation instructions in the "Instructions for AI" section. In your instructions you should describe to what language you want it to translate the text to. Also, you may need to add additional instructions to not add any notes or comments as AIs tend to add them. Example instructions to translate English subtitles to Spanish:
|
||||
|
||||
> You are a professional translator, skilled in translating English to Spanish. You will only translate each sentence sent to you into Spanish and not add any notes or comments.
|
||||
|
||||
If you enable "Enable live recording transcription export" in Preferences, Live text transcripts will be exported to a text file as they get generated and translated. This file can be used to further integrate Live transcripts with other applications like OBS Studio.
|
||||
|
||||
Approximate cost of translation for 1 hour long audio with ChatGPT `gpt-4o` model is around 0.50$
|
||||
|
|
@ -0,0 +1,9 @@
|
|||
---
|
||||
title: Edit and Resize
|
||||
---
|
||||
|
||||
When transcript of some audio or video file is generated you can edit it and export to different subtitle formats or plain text. Double-click the transcript in the list of transcripts to see additional options for editing and exporting.
|
||||
|
||||
Transcription view screen has option to resize the transcripts. Click on the "Resize" button so see available options. Transcripts that have been generated **with word-level timings** setting enabled can be combined into subtitles specifying different options, like maximum length of a subtitle and if subtitles should be split on punctuation. For transcripts that have been generated **without word-level timings** setting enabled can only be recombined specifying desired max length of a subtitle.
|
||||
|
||||
If audio file is still present on the system word-level timing merge will also analyze the audio for silences to improve subtitle accuracy. Subtitle generation from transcripts with word-level timings is available since version 1.3.0.
|
||||
|
|
@ -0,0 +1,2 @@
|
|||
label: Usage
|
||||
position: 3
|
||||
Loading…
Add table
Add a link
Reference in a new issue