diff --git a/README.md b/README.md
index 9b04af7f..e7dfe476 100644
--- a/README.md
+++ b/README.md
@@ -90,6 +90,8 @@ For info on how to get latest development version with latest features and bug f


 +
+ 
 -
-  +
+
+
+  diff --git a/docs/docs/preferences.md b/docs/docs/preferences.md
index c894a170..98f5dbb3 100644
--- a/docs/docs/preferences.md
+++ b/docs/docs/preferences.md
@@ -52,6 +52,18 @@ Last sentence will be at the top.
This mode will also try to correct errors at the end of previously transcribed sentences. This mode requires more
processing power and more powerful hardware to work.
+## Model Preferences
+
+This section lets you download new models for transcription and delete unused ones.
+
+For Whisper.cpp you can also download custom models. Select `Custom` in the model size list and paste the download url
+to the model `.bin` file. Use the link from "download" button from the Huggingface.
+
+To improve transcription speed and memory usage you can select a quantized version of some
+larger model. For example `q_5` version. Whisper.cpp base models in different quantizations are [available here](https://huggingface.co/ggerganov/whisper.cpp/tree/main). See also [custom models](https://github.com/chidiwilliams/buzz/discussions/866) discussion page for custom models in different languages.
+
+[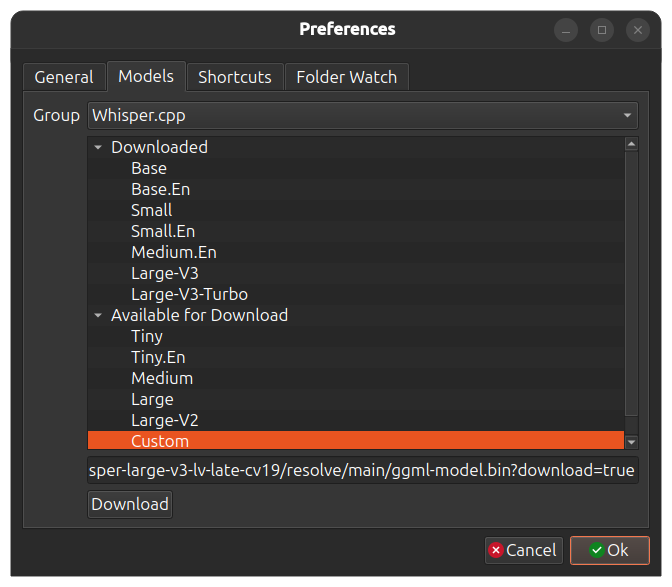](https://www.loom.com/share/cf263b099ac3481082bb56d19b7c87fe "Model preferences")
+
## Advanced Preferences
To keep preferences section simple for new users, some more advanced preferences are settable via OS environment variables. Set the necessary environment variables in your OS before starting Buzz or create a script to set them.
diff --git a/docs/docs/usage/1_file_import.md b/docs/docs/usage/1_file_import.md
index bc8cc7e9..91ccc672 100644
--- a/docs/docs/usage/1_file_import.md
+++ b/docs/docs/usage/1_file_import.md
@@ -2,7 +2,7 @@
title: File Import
---
-To import a file:
+**To import a file:**
- Click Import Media File on the File menu (or the '+' icon on the toolbar, or **Command/Ctrl + O**).
- Choose an audio or video file.
@@ -11,11 +11,16 @@ To import a file:
- When the transcription status shows 'Completed', double-click on the row (or select the row and click the '⤢' icon) to
open the transcription.
-| Field | Options | Default | Description |
-| ------------------ | ------------------- | ------- | -------------------------------------------------------------------------------------------------------------------------------------------------------- |
-| Export As | "TXT", "SRT", "VTT" | "TXT" | Export file format |
-| Word-Level Timings | Off / On | Off | If checked, the transcription will generate a separate subtitle line for each word in the audio. Enabled only when "Export As" is set to "SRT" or "VTT". |
-| Extract speech | Off / On | Off | If checked, speech will be extracted to a separate audio tack to improve accuracy. Available since 1.3.0. |
+**Available options:**
+
+To reduce misspellings you can pass some commonly misspelled words in an `Initial prompt` that is available under `Advanced...` button. See this [guide on prompting](https://cookbook.openai.com/examples/whisper_prompting_guide#pass-names-in-the-prompt-to-prevent-misspellings).
+
+
+| Field | Options | Default | Description |
+| ------------------ | ------------------- | ------- |---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+| Export As | "TXT", "SRT", "VTT" | "TXT" | Export file format |
+| Word-Level Timings | Off / On | Off | If checked, the transcription will generate a separate subtitle line for each word in the audio. Combine words into subtitles afterwards with the [resize option](https://chidiwilliams.github.io/buzz/docs/usage/edit_and_resize). |
+| Extract speech | Off / On | Off | If checked, speech will be extracted to a separate audio tack to improve accuracy. Available since 1.3.0. |
(See the [Live Recording section](https://chidiwilliams.github.io/buzz/docs/usage/live_recording) for more information about the task, language, and quality settings.)
diff --git a/docs/docs/usage/2_live_recording.md b/docs/docs/usage/2_live_recording.md
index ead75f10..83c567d1 100644
--- a/docs/docs/usage/2_live_recording.md
+++ b/docs/docs/usage/2_live_recording.md
@@ -7,14 +7,13 @@ To start a live recording:
- Select a recording task, language, quality, and microphone.
- Click Record.
-> **Note:** Transcribing audio using the default Whisper model is resource-intensive. Consider using the Whisper.cpp
-> Tiny model to get real-time performance.
+> **Note:** Transcribing audio using the default Whisper model is resource-intensive. Consider using the Whisper.cpp.
+> Since 1.3.0 it supports GPU acceleration, if the model fits in GPU memory. Use smaller models for real-time performance.
| Field | Options | Default | Description |
|------------|------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
-| Task | "Transcribe", "Translate" | "Transcribe" | "Transcribe" converts the input audio into text in the selected language, while "Translate" converts it into text in English. |
+| Task | "Transcribe", "Translate to English" | "Transcribe" | "Transcribe" converts the input audio into text in the selected language, while "Translate to English" converts it into text in English. |
| Language | See [Whisper's documentation](https://github.com/openai/whisper#available-models-and-languages) for the full list of supported languages | "Detect Language" | "Detect Language" will try to detect the spoken language in the audio based on the first few seconds. However, selecting a language is recommended (if known) as it will improve transcription quality in many cases. |
-| Quality | "Very Low", "Low", "Medium", "High" | "Very Low" | The transcription quality determines the Whisper model used for transcription. "Very Low" uses the "tiny" model; "Low" uses the "base" model; "Medium" uses the "small" model; and "High" uses the "medium" model. The larger models produce higher-quality transcriptions, but require more system resources. See [Whisper's documentation](https://github.com/openai/whisper#available-models-and-languages) for more information about the models. |
| Microphone | [Available system microphones] | [Default system microphone] | Microphone for recording input audio. |
[](https://www.loom.com/share/564b753eb4d44b55b985b8abd26b55f7 "Live Recording on Buzz")
diff --git a/docs/docs/usage/4_edit_and_resize.md b/docs/docs/usage/4_edit_and_resize.md
index 09438e3a..8b51cc3f 100644
--- a/docs/docs/usage/4_edit_and_resize.md
+++ b/docs/docs/usage/4_edit_and_resize.md
@@ -2,6 +2,8 @@
title: Edit and Resize
---
+[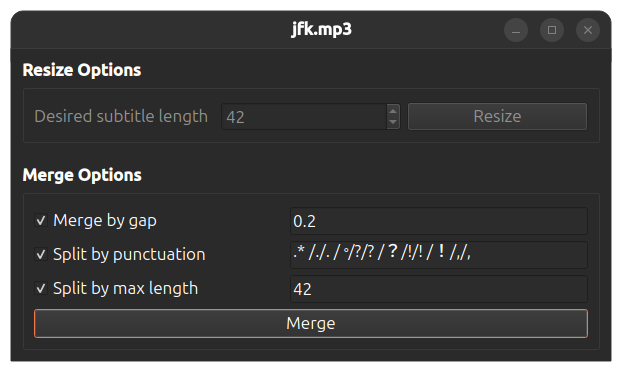](https://www.loom.com/share/cf263b099ac3481082bb56d19b7c87fe "Resize options")
+
When transcript of some audio or video file is generated you can edit it and export to different subtitle formats or plain text. Double-click the transcript in the list of transcripts to see additional options for editing and exporting.
Transcription view screen has option to resize the transcripts. Click on the "Resize" button so see available options. Transcripts that have been generated **with word-level timings** setting enabled can be combined into subtitles specifying different options, like maximum length of a subtitle and if subtitles should be split on punctuation. For transcripts that have been generated **without word-level timings** setting enabled can only be recombined specifying desired max length of a subtitle.
diff --git a/share/screenshots/buzz-3.2-model-preferences.png b/share/screenshots/buzz-3.2-model-preferences.png
new file mode 100644
index 00000000..d699ffb9
Binary files /dev/null and b/share/screenshots/buzz-3.2-model-preferences.png differ
diff --git a/share/screenshots/buzz-6-resize.png b/share/screenshots/buzz-6-resize.png
new file mode 100644
index 00000000..4ae3f120
Binary files /dev/null and b/share/screenshots/buzz-6-resize.png differ
diff --git a/docs/docs/preferences.md b/docs/docs/preferences.md
index c894a170..98f5dbb3 100644
--- a/docs/docs/preferences.md
+++ b/docs/docs/preferences.md
@@ -52,6 +52,18 @@ Last sentence will be at the top.
This mode will also try to correct errors at the end of previously transcribed sentences. This mode requires more
processing power and more powerful hardware to work.
+## Model Preferences
+
+This section lets you download new models for transcription and delete unused ones.
+
+For Whisper.cpp you can also download custom models. Select `Custom` in the model size list and paste the download url
+to the model `.bin` file. Use the link from "download" button from the Huggingface.
+
+To improve transcription speed and memory usage you can select a quantized version of some
+larger model. For example `q_5` version. Whisper.cpp base models in different quantizations are [available here](https://huggingface.co/ggerganov/whisper.cpp/tree/main). See also [custom models](https://github.com/chidiwilliams/buzz/discussions/866) discussion page for custom models in different languages.
+
+[](https://www.loom.com/share/cf263b099ac3481082bb56d19b7c87fe "Model preferences")
+
## Advanced Preferences
To keep preferences section simple for new users, some more advanced preferences are settable via OS environment variables. Set the necessary environment variables in your OS before starting Buzz or create a script to set them.
diff --git a/docs/docs/usage/1_file_import.md b/docs/docs/usage/1_file_import.md
index bc8cc7e9..91ccc672 100644
--- a/docs/docs/usage/1_file_import.md
+++ b/docs/docs/usage/1_file_import.md
@@ -2,7 +2,7 @@
title: File Import
---
-To import a file:
+**To import a file:**
- Click Import Media File on the File menu (or the '+' icon on the toolbar, or **Command/Ctrl + O**).
- Choose an audio or video file.
@@ -11,11 +11,16 @@ To import a file:
- When the transcription status shows 'Completed', double-click on the row (or select the row and click the '⤢' icon) to
open the transcription.
-| Field | Options | Default | Description |
-| ------------------ | ------------------- | ------- | -------------------------------------------------------------------------------------------------------------------------------------------------------- |
-| Export As | "TXT", "SRT", "VTT" | "TXT" | Export file format |
-| Word-Level Timings | Off / On | Off | If checked, the transcription will generate a separate subtitle line for each word in the audio. Enabled only when "Export As" is set to "SRT" or "VTT". |
-| Extract speech | Off / On | Off | If checked, speech will be extracted to a separate audio tack to improve accuracy. Available since 1.3.0. |
+**Available options:**
+
+To reduce misspellings you can pass some commonly misspelled words in an `Initial prompt` that is available under `Advanced...` button. See this [guide on prompting](https://cookbook.openai.com/examples/whisper_prompting_guide#pass-names-in-the-prompt-to-prevent-misspellings).
+
+
+| Field | Options | Default | Description |
+| ------------------ | ------------------- | ------- |---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+| Export As | "TXT", "SRT", "VTT" | "TXT" | Export file format |
+| Word-Level Timings | Off / On | Off | If checked, the transcription will generate a separate subtitle line for each word in the audio. Combine words into subtitles afterwards with the [resize option](https://chidiwilliams.github.io/buzz/docs/usage/edit_and_resize). |
+| Extract speech | Off / On | Off | If checked, speech will be extracted to a separate audio tack to improve accuracy. Available since 1.3.0. |
(See the [Live Recording section](https://chidiwilliams.github.io/buzz/docs/usage/live_recording) for more information about the task, language, and quality settings.)
diff --git a/docs/docs/usage/2_live_recording.md b/docs/docs/usage/2_live_recording.md
index ead75f10..83c567d1 100644
--- a/docs/docs/usage/2_live_recording.md
+++ b/docs/docs/usage/2_live_recording.md
@@ -7,14 +7,13 @@ To start a live recording:
- Select a recording task, language, quality, and microphone.
- Click Record.
-> **Note:** Transcribing audio using the default Whisper model is resource-intensive. Consider using the Whisper.cpp
-> Tiny model to get real-time performance.
+> **Note:** Transcribing audio using the default Whisper model is resource-intensive. Consider using the Whisper.cpp.
+> Since 1.3.0 it supports GPU acceleration, if the model fits in GPU memory. Use smaller models for real-time performance.
| Field | Options | Default | Description |
|------------|------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
-| Task | "Transcribe", "Translate" | "Transcribe" | "Transcribe" converts the input audio into text in the selected language, while "Translate" converts it into text in English. |
+| Task | "Transcribe", "Translate to English" | "Transcribe" | "Transcribe" converts the input audio into text in the selected language, while "Translate to English" converts it into text in English. |
| Language | See [Whisper's documentation](https://github.com/openai/whisper#available-models-and-languages) for the full list of supported languages | "Detect Language" | "Detect Language" will try to detect the spoken language in the audio based on the first few seconds. However, selecting a language is recommended (if known) as it will improve transcription quality in many cases. |
-| Quality | "Very Low", "Low", "Medium", "High" | "Very Low" | The transcription quality determines the Whisper model used for transcription. "Very Low" uses the "tiny" model; "Low" uses the "base" model; "Medium" uses the "small" model; and "High" uses the "medium" model. The larger models produce higher-quality transcriptions, but require more system resources. See [Whisper's documentation](https://github.com/openai/whisper#available-models-and-languages) for more information about the models. |
| Microphone | [Available system microphones] | [Default system microphone] | Microphone for recording input audio. |
[](https://www.loom.com/share/564b753eb4d44b55b985b8abd26b55f7 "Live Recording on Buzz")
diff --git a/docs/docs/usage/4_edit_and_resize.md b/docs/docs/usage/4_edit_and_resize.md
index 09438e3a..8b51cc3f 100644
--- a/docs/docs/usage/4_edit_and_resize.md
+++ b/docs/docs/usage/4_edit_and_resize.md
@@ -2,6 +2,8 @@
title: Edit and Resize
---
+[](https://www.loom.com/share/cf263b099ac3481082bb56d19b7c87fe "Resize options")
+
When transcript of some audio or video file is generated you can edit it and export to different subtitle formats or plain text. Double-click the transcript in the list of transcripts to see additional options for editing and exporting.
Transcription view screen has option to resize the transcripts. Click on the "Resize" button so see available options. Transcripts that have been generated **with word-level timings** setting enabled can be combined into subtitles specifying different options, like maximum length of a subtitle and if subtitles should be split on punctuation. For transcripts that have been generated **without word-level timings** setting enabled can only be recombined specifying desired max length of a subtitle.
diff --git a/share/screenshots/buzz-3.2-model-preferences.png b/share/screenshots/buzz-3.2-model-preferences.png
new file mode 100644
index 00000000..d699ffb9
Binary files /dev/null and b/share/screenshots/buzz-3.2-model-preferences.png differ
diff --git a/share/screenshots/buzz-6-resize.png b/share/screenshots/buzz-6-resize.png
new file mode 100644
index 00000000..4ae3f120
Binary files /dev/null and b/share/screenshots/buzz-6-resize.png differ