mirror of
https://github.com/chidiwilliams/buzz.git
synced 2026-03-14 14:45:46 +01:00
Add docs (#500)
This commit is contained in:
parent
5ca72dd992
commit
b68663f324
21 changed files with 13222 additions and 193 deletions
32
.github/workflows/gh-pages.yml
vendored
Normal file
32
.github/workflows/gh-pages.yml
vendored
Normal file
|
|
@ -0,0 +1,32 @@
|
|||
---
|
||||
name: GitHub Pages
|
||||
on:
|
||||
push:
|
||||
branches:
|
||||
- main
|
||||
|
||||
jobs:
|
||||
deploy:
|
||||
name: Deploy
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- uses: actions/setup-node@v3
|
||||
with:
|
||||
node-version: 18
|
||||
cache: npm
|
||||
cache-dependency-path: docs/package-lock.json
|
||||
|
||||
- name: Install dependencies
|
||||
run: npm ci
|
||||
working-directory: docs
|
||||
|
||||
- name: Build
|
||||
run: npm run build
|
||||
working-directory: docs
|
||||
|
||||
- name: Deploy to GitHub Pages
|
||||
uses: peaceiris/actions-gh-pages@v3
|
||||
with:
|
||||
github_token: ${{ secrets.GITHUB_TOKEN }}
|
||||
publish_dir: ./docs/build
|
||||
195
README.md
195
README.md
|
|
@ -1,5 +1,7 @@
|
|||
# Buzz
|
||||
|
||||
[Documentation](https://chidiwilliams.github.io/buzz/) | [Buzz Captions on the App Store](https://apps.apple.com/us/app/buzz-captions/id6446018936?mt=12&itsct=apps_box_badge&itscg=30200)
|
||||
|
||||
Transcribe and translate audio offline on your personal computer. Powered by
|
||||
OpenAI's [Whisper](https://github.com/openai/whisper).
|
||||
|
||||
|
|
@ -15,196 +17,3 @@ OpenAI's [Whisper](https://github.com/openai/whisper).
|
|||
</blockquote>
|
||||
|
||||

|
||||
|
||||
## Features
|
||||
|
||||
- Import audio and video files and export transcripts to TXT, SRT, and
|
||||
VTT ([Demo](https://www.loom.com/share/cf263b099ac3481082bb56d19b7c87fe))
|
||||
- Transcription and translation from your computer's microphones to text (Resource-intensive and may not be
|
||||
real-time, [Demo](https://www.loom.com/share/564b753eb4d44b55b985b8abd26b55f7))
|
||||
- Supports [Whisper](https://github.com/openai/whisper#available-models-and-languages),
|
||||
[Whisper.cpp](https://github.com/ggerganov/whisper.cpp), [Faster Whisper](https://github.com/guillaumekln/faster-whisper),
|
||||
[Whisper-compatible Hugging Face models](https://huggingface.co/models?other=whisper), and
|
||||
the [OpenAI Whisper API](https://platform.openai.com/docs/api-reference/introduction)
|
||||
- [Command-Line Interface](#command-line-interface)
|
||||
- Available on Mac, Windows, and Linux
|
||||
|
||||
## Installation
|
||||
|
||||
To install Buzz, download the [latest version](https://github.com/chidiwilliams/buzz/releases/latest) for your operating
|
||||
system. Buzz is available on **Mac** (Intel), **Windows**, and **Linux**. (For Apple Silicon, please see the [App Store version](https://apps.apple.com/us/app/buzz-captions/id6446018936?mt=12&itsct=apps_box_badge&itscg=30200).)
|
||||
|
||||
### Mac (Intel, macOS 11.7 and later)
|
||||
|
||||
- Install via [brew](https://brew.sh/):
|
||||
|
||||
```shell
|
||||
brew install --cask buzz
|
||||
```
|
||||
|
||||
Alternatively, download and run the `Buzz-x.y.z.dmg` file.
|
||||
|
||||
### Windows (Windows 10 and later)
|
||||
|
||||
- Download and run the `Buzz-x.y.z.exe` file.
|
||||
|
||||
### Linux (Ubuntu 20.04 and later)
|
||||
|
||||
- Install dependencies:
|
||||
|
||||
```shell
|
||||
sudo apt-get install libportaudio2
|
||||
```
|
||||
|
||||
- Download and extract the `Buzz-x.y.z-unix.tar.gz` file
|
||||
|
||||
## How to use
|
||||
|
||||
### File import
|
||||
|
||||
To import a file:
|
||||
|
||||
- Click Import Media File on the File menu (or the '+' icon on the toolbar, or **Command/Ctrl + O**).
|
||||
- Choose an audio or video file.
|
||||
- Select a task, language, and the model settings.
|
||||
- Click Run.
|
||||
- When the transcription status shows 'Completed', double-click on the row (or select the row and click the '⤢' icon) to
|
||||
open the transcription.
|
||||
|
||||
| Field | Options | Default | Description |
|
||||
| ------------------ | ------------------- | ------- | -------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| Export As | "TXT", "SRT", "VTT" | "TXT" | Export file format |
|
||||
| Word-Level Timings | Off / On | Off | If checked, the transcription will generate a separate subtitle line for each word in the audio. Enabled only when "Export As" is set to "SRT" or "VTT". |
|
||||
|
||||
(See the [Live Recording section](#live-recording) for more information about the task, language, and quality settings.)
|
||||
|
||||
[](https://www.loom.com/share/cf263b099ac3481082bb56d19b7c87fe "Media File Import on Buzz")
|
||||
|
||||
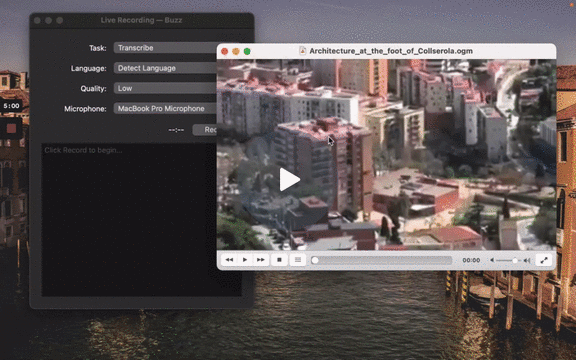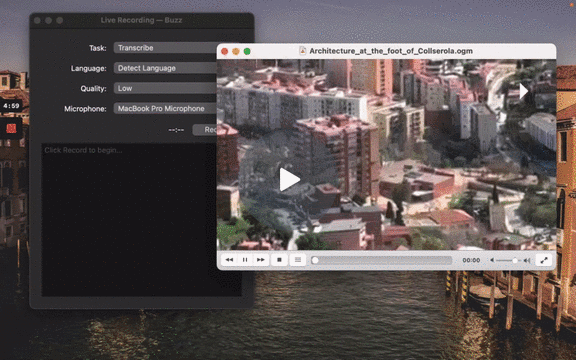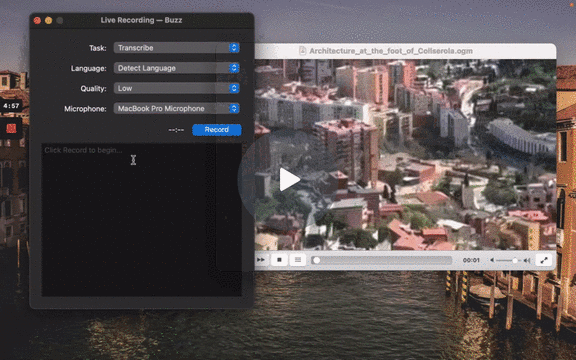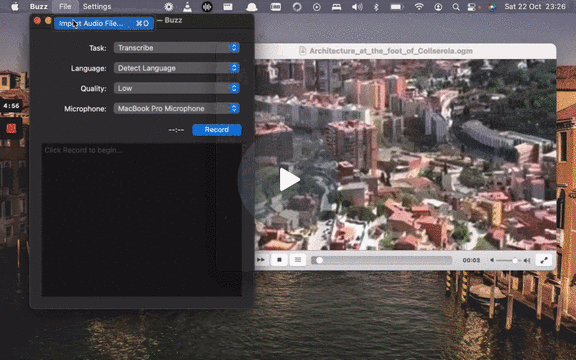
### Live Recording
|
||||
|
||||
To start a live recording:
|
||||
|
||||
- Select a recording task, language, quality, and microphone.
|
||||
- Click Record.
|
||||
|
||||
> **Note:** Transcribing audio using the default Whisper model is resource-intensive. Consider using the Whisper.cpp
|
||||
> Tiny model to get real-time performance.
|
||||
|
||||
| Field | Options | Default | Description |
|
||||
| ---------- | ---------------------------------------------------------------------------------------------------------------------------------------- | --------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| Task | "Transcribe", "Translate" | "Transcribe" | "Transcribe" converts the input audio into text in the selected language, while "Translate" converts it into text in English. |
|
||||
| Language | See [Whisper's documentation](https://github.com/openai/whisper#available-models-and-languages) for the full list of supported languages | "Detect Language" | "Detect Language" will try to detect the spoken language in the audio based on the first few seconds. However, selecting a language is recommended (if known) as it will improve transcription quality in many cases. |
|
||||
| Quality | "Very Low", "Low", "Medium", "High" | "Very Low" | The transcription quality determines the Whisper model used for transcription. "Very Low" uses the "tiny" model; "Low" uses the "base" model; "Medium" uses the "small" model; and "High" uses the "medium" model. The larger models produce higher-quality transcriptions, but require more system resources. See [Whisper's documentation](https://github.com/openai/whisper#available-models-and-languages) for more information about the models. |
|
||||
| Microphone | [Available system microphones] | [Default system microphone] | Microphone for recording input audio. |
|
||||
|
||||
[](https://www.loom.com/share/564b753eb4d44b55b985b8abd26b55f7 "Live Recording on Buzz")
|
||||
|
||||
### Record audio playing from computer
|
||||
|
||||
To record audio playing from an application on your computer, you may install an audio loopback driver (a program that
|
||||
lets you create virtual audio devices). The rest of this guide will
|
||||
use [BlackHole](https://github.com/ExistentialAudio/BlackHole) on Mac, but you can use other alternatives for your
|
||||
operating system (
|
||||
see [LoopBeAudio](https://nerds.de/en/loopbeaudio.html), [LoopBack](https://rogueamoeba.com/loopback/),
|
||||
and [Virtual Audio Cable](https://vac.muzychenko.net/en/)).
|
||||
|
||||
1. Install [BlackHole via Homebrew](https://github.com/ExistentialAudio/BlackHole#option-2-install-via-homebrew)
|
||||
|
||||
```shell
|
||||
brew install blackhole-2ch
|
||||
```
|
||||
|
||||
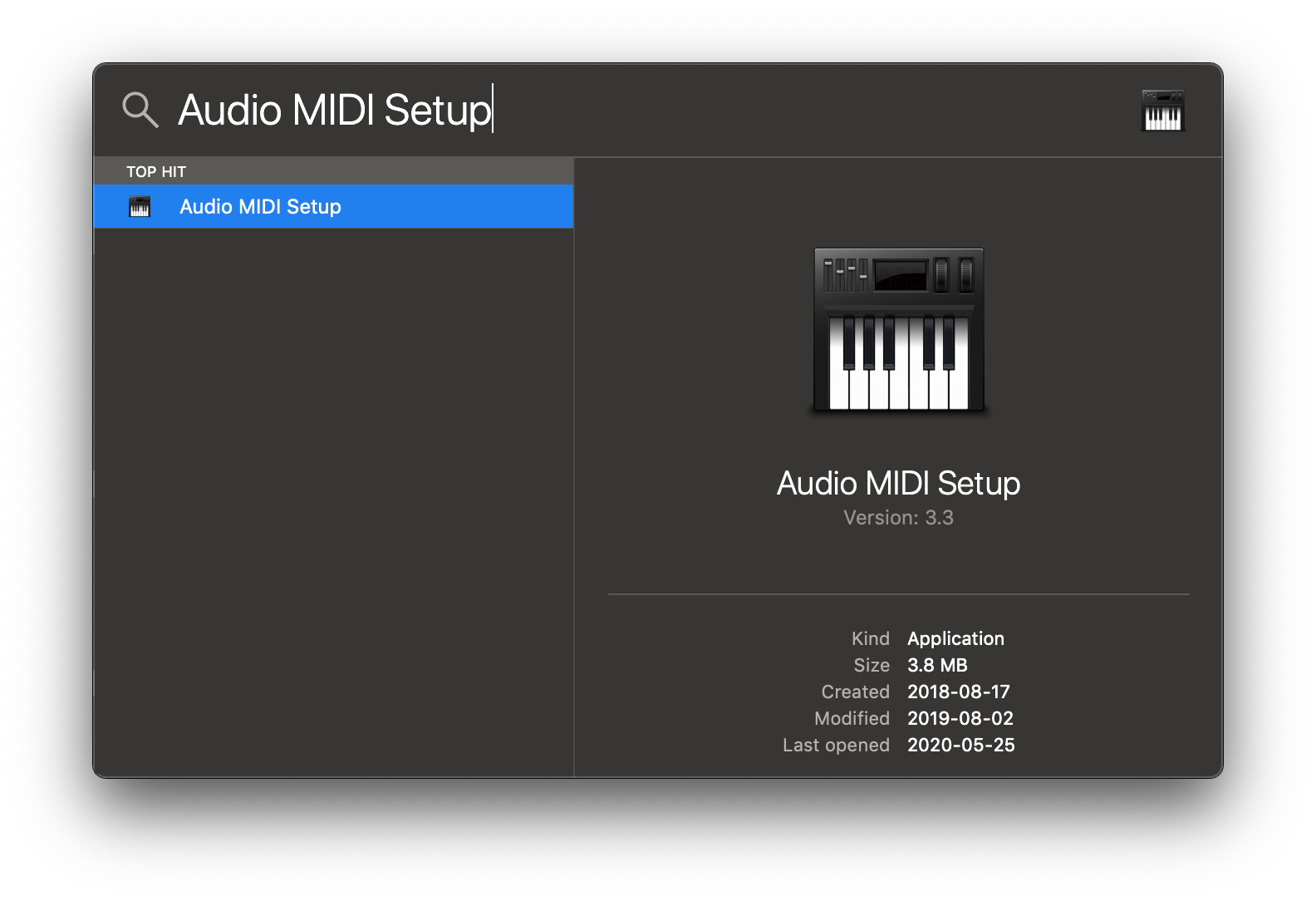
2. Open Audio MIDI Setup from Spotlight or from `/Applications/Utilities/Audio Midi Setup.app`.
|
||||
|
||||
|
||||
|
||||
3. Click the '+' icon at the lower left corner and select 'Create Multi-Output Device'.
|
||||
|
||||

|
||||
|
||||
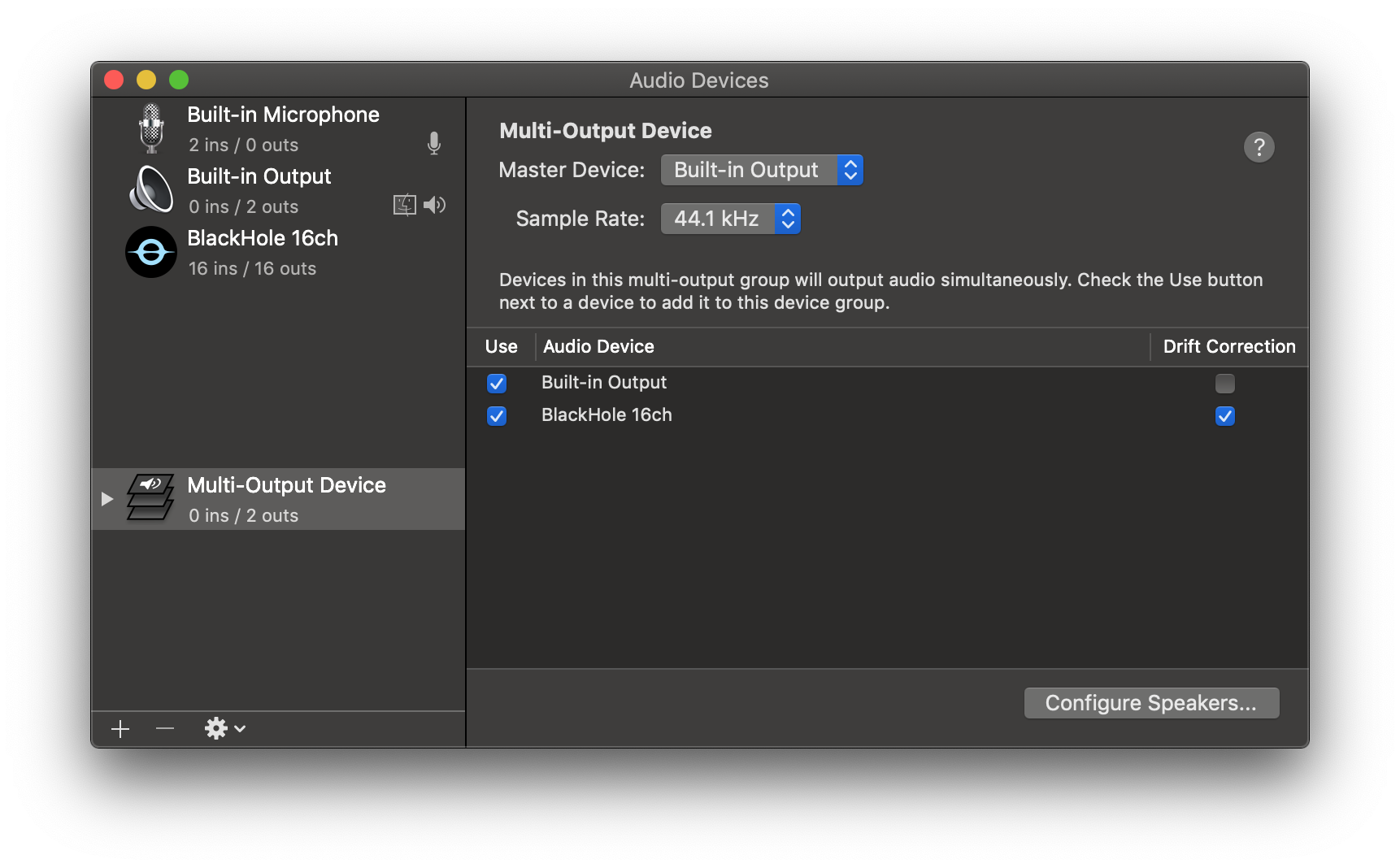
4. Add your default speaker and BlackHole to the multi-output device.
|
||||
|
||||
|
||||
|
||||
5. Select this multi-output device as your speaker (application or system-wide) to play audio into BlackHole.
|
||||
|
||||
6. Open Buzz, select BlackHole as your microphone, and record as before to see transcriptions from the audio playing
|
||||
through BlackHole.
|
||||
|
||||
## Command-Line Interface
|
||||
|
||||
### `add`
|
||||
|
||||
Start a new transcription task
|
||||
|
||||
Examples:
|
||||
|
||||
```shell
|
||||
# Translate two MP3 files from French to English using OpenAI Whisper API
|
||||
buzz add --task translate --language fr --model-type openaiapi /Users/user/Downloads/1b3b03e4-8db5-ea2c-ace5-b71ff32e3304.mp3 /Users/user/Downloads/koaf9083k1lkpsfdi0.mp3
|
||||
|
||||
# Transcribe an MP4 using Whisper.cpp "small" model and immediately export to SRT and VTT files
|
||||
buzz add --task transcribe --model-type whispercpp --model-size small --prompt "My initial prompt" --srt --vtt /Users/user/Downloads/buzz/1b3b03e4-8db5-ea2c-ace5-b71ff32e3304.mp4
|
||||
```
|
||||
|
||||
Run `buzz add --help` to see all available options.
|
||||
|
||||
## Build
|
||||
|
||||
To build/run Buzz locally from source, first install the requirements:
|
||||
|
||||
1. [Poetry](https://python-poetry.org/docs/#installing-with-the-official-installer)
|
||||
|
||||
Then:
|
||||
|
||||
1. Clone the repository
|
||||
|
||||
```shell
|
||||
git clone --recurse-submodules https://github.com/chidiwilliams/buzz
|
||||
```
|
||||
|
||||
2. Install the project dependencies.
|
||||
|
||||
```shell
|
||||
poetry install
|
||||
```
|
||||
|
||||
3. (Optional) To use Whisper.cpp inference, run:
|
||||
|
||||
```shell
|
||||
make buzz/whisper_cpp.py
|
||||
```
|
||||
|
||||
4. (Optional) To compile the translations, run:
|
||||
|
||||
```shell
|
||||
make translation_mo
|
||||
```
|
||||
|
||||
5. Finally, run the app with:
|
||||
|
||||
```shell
|
||||
poetry run python main.py
|
||||
```
|
||||
|
||||
Or build with:
|
||||
|
||||
```shell
|
||||
poetry run pyinstaller --noconfirm Buzz.spec
|
||||
```
|
||||
|
||||
## FAQ
|
||||
|
||||
1. **Where are the models stored?**
|
||||
|
||||
The Whisper models are stored in `~/.cache/whisper`. The Whisper.cpp models are stored in `~/Library/Caches/Buzz` (
|
||||
Mac OS), `~/.cache/Buzz` (Unix), or `C:\Users\<username>\AppData\Local\Buzz\Buzz\Cache` (Windows). The Hugging Face
|
||||
models are stored in `~/.cache/huggingface/hub`.
|
||||
|
||||
2. **What can I try if the transcription runs too slowly?**
|
||||
|
||||
Try using a lower Whisper model size or using a Whisper.cpp model.
|
||||
|
||||
## Credits
|
||||
|
||||
- SVG Icons: [Google Fonts Material Symbols](https://fonts.google.com/icons)
|
||||
|
|
|
|||
20
docs/.gitignore
vendored
Normal file
20
docs/.gitignore
vendored
Normal file
|
|
@ -0,0 +1,20 @@
|
|||
# Dependencies
|
||||
/node_modules
|
||||
|
||||
# Production
|
||||
/build
|
||||
|
||||
# Generated files
|
||||
.docusaurus
|
||||
.cache-loader
|
||||
|
||||
# Misc
|
||||
.DS_Store
|
||||
.env.local
|
||||
.env.development.local
|
||||
.env.test.local
|
||||
.env.production.local
|
||||
|
||||
npm-debug.log*
|
||||
yarn-debug.log*
|
||||
yarn-error.log*
|
||||
41
docs/README.md
Normal file
41
docs/README.md
Normal file
|
|
@ -0,0 +1,41 @@
|
|||
# Website
|
||||
|
||||
This website is built using [Docusaurus 2](https://docusaurus.io/), a modern static website generator.
|
||||
|
||||
### Installation
|
||||
|
||||
```
|
||||
$ yarn
|
||||
```
|
||||
|
||||
### Local Development
|
||||
|
||||
```
|
||||
$ yarn start
|
||||
```
|
||||
|
||||
This command starts a local development server and opens up a browser window. Most changes are reflected live without having to restart the server.
|
||||
|
||||
### Build
|
||||
|
||||
```
|
||||
$ yarn build
|
||||
```
|
||||
|
||||
This command generates static content into the `build` directory and can be served using any static contents hosting service.
|
||||
|
||||
### Deployment
|
||||
|
||||
Using SSH:
|
||||
|
||||
```
|
||||
$ USE_SSH=true yarn deploy
|
||||
```
|
||||
|
||||
Not using SSH:
|
||||
|
||||
```
|
||||
$ GIT_USER=<Your GitHub username> yarn deploy
|
||||
```
|
||||
|
||||
If you are using GitHub pages for hosting, this command is a convenient way to build the website and push to the `gh-pages` branch.
|
||||
3
docs/babel.config.js
Normal file
3
docs/babel.config.js
Normal file
|
|
@ -0,0 +1,3 @@
|
|||
module.exports = {
|
||||
presets: [require.resolve('@docusaurus/core/lib/babel/preset')],
|
||||
};
|
||||
85
docs/docs/cli.md
Normal file
85
docs/docs/cli.md
Normal file
|
|
@ -0,0 +1,85 @@
|
|||
---
|
||||
title: CLI
|
||||
sidebar_position: 4
|
||||
---
|
||||
|
||||
## Commands
|
||||
|
||||
### `add`
|
||||
|
||||
Start a new transcription task.
|
||||
|
||||
```
|
||||
Usage: buzz add [options] [file file file...]
|
||||
|
||||
Options:
|
||||
-t, --task <task> The task to perform. Allowed: translate,
|
||||
transcribe. Default: transcribe.
|
||||
-m, --model-type <model-type> Model type. Allowed: whisper, whispercpp,
|
||||
huggingface, fasterwhisper, openaiapi. Default:
|
||||
whisper.
|
||||
-s, --model-size <model-size> Model size. Use only when --model-type is
|
||||
whisper, whispercpp, or fasterwhisper. Allowed:
|
||||
tiny, base, small, medium, large. Default:
|
||||
tiny.
|
||||
--hfid <id> Hugging Face model ID. Use only when
|
||||
--model-type is huggingface. Example:
|
||||
"openai/whisper-tiny"
|
||||
-l, --language <code> Language code. Allowed: af (Afrikaans), am
|
||||
(Amharic), ar (Arabic), as (Assamese), az
|
||||
(Azerbaijani), ba (Bashkir), be (Belarusian),
|
||||
bg (Bulgarian), bn (Bengali), bo (Tibetan), br
|
||||
(Breton), bs (Bosnian), ca (Catalan), cs
|
||||
(Czech), cy (Welsh), da (Danish), de (German),
|
||||
el (Greek), en (English), es (Spanish), et
|
||||
(Estonian), eu (Basque), fa (Persian), fi
|
||||
(Finnish), fo (Faroese), fr (French), gl
|
||||
(Galician), gu (Gujarati), ha (Hausa), haw
|
||||
(Hawaiian), he (Hebrew), hi (Hindi), hr
|
||||
(Croatian), ht (Haitian Creole), hu
|
||||
(Hungarian), hy (Armenian), id (Indonesian), is
|
||||
(Icelandic), it (Italian), ja (Japanese), jw
|
||||
(Javanese), ka (Georgian), kk (Kazakh), km
|
||||
(Khmer), kn (Kannada), ko (Korean), la (Latin),
|
||||
lb (Luxembourgish), ln (Lingala), lo (Lao), lt
|
||||
(Lithuanian), lv (Latvian), mg (Malagasy), mi
|
||||
(Maori), mk (Macedonian), ml (Malayalam), mn
|
||||
(Mongolian), mr (Marathi), ms (Malay), mt
|
||||
(Maltese), my (Myanmar), ne (Nepali), nl
|
||||
(Dutch), nn (Nynorsk), no (Norwegian), oc
|
||||
(Occitan), pa (Punjabi), pl (Polish), ps
|
||||
(Pashto), pt (Portuguese), ro (Romanian), ru
|
||||
(Russian), sa (Sanskrit), sd (Sindhi), si
|
||||
(Sinhala), sk (Slovak), sl (Slovenian), sn
|
||||
(Shona), so (Somali), sq (Albanian), sr
|
||||
(Serbian), su (Sundanese), sv (Swedish), sw
|
||||
(Swahili), ta (Tamil), te (Telugu), tg (Tajik),
|
||||
th (Thai), tk (Turkmen), tl (Tagalog), tr
|
||||
(Turkish), tt (Tatar), uk (Ukrainian), ur
|
||||
(Urdu), uz (Uzbek), vi (Vietnamese), yi
|
||||
(Yiddish), yo (Yoruba), zh (Chinese). Leave
|
||||
empty to detect language.
|
||||
-p, --prompt <prompt> Initial prompt
|
||||
--openai-token <token> OpenAI access token. Use only when
|
||||
--model-type is openaiapi. Defaults to your
|
||||
previously saved access token, if one exists.
|
||||
--srt Output result in an SRT file.
|
||||
--vtt Output result in a VTT file.
|
||||
--txt Output result in a TXT file.
|
||||
-h, --help Displays help on commandline options.
|
||||
--help-all Displays help including Qt specific options.
|
||||
-v, --version Displays version information.
|
||||
|
||||
Arguments:
|
||||
files Input file paths
|
||||
```
|
||||
|
||||
**Examples**:
|
||||
|
||||
```shell
|
||||
# Translate two MP3 files from French to English using OpenAI Whisper API
|
||||
buzz add --task translate --language fr --model-type openaiapi /Users/user/Downloads/1b3b03e4-8db5-ea2c-ace5-b71ff32e3304.mp3 /Users/user/Downloads/koaf9083k1lkpsfdi0.mp3
|
||||
|
||||
# Transcribe an MP4 using Whisper.cpp "small" model and immediately export to SRT and VTT files
|
||||
buzz add --task transcribe --model-type whispercpp --model-size small --prompt "My initial prompt" --srt --vtt /Users/user/Downloads/buzz/1b3b03e4-8db5-ea2c-ace5-b71ff32e3304.mp4
|
||||
```
|
||||
14
docs/docs/faq.md
Normal file
14
docs/docs/faq.md
Normal file
|
|
@ -0,0 +1,14 @@
|
|||
---
|
||||
title: FAQ
|
||||
sidebar_position: 5
|
||||
---
|
||||
|
||||
1. **Where are the models stored?**
|
||||
|
||||
The Whisper models are stored in `~/.cache/whisper`. The Whisper.cpp models are stored in `~/Library/Caches/Buzz`
|
||||
(Mac OS), `~/.cache/Buzz` (Unix), or `C:\Users\<username>\AppData\Local\Buzz\Buzz\Cache` (Windows). The Hugging Face
|
||||
models are stored in `~/.cache/huggingface/hub`.
|
||||
|
||||
2. **What can I try if the transcription runs too slowly?**
|
||||
|
||||
Try using a lower Whisper model size or using a Whisper.cpp model.
|
||||
29
docs/docs/index.md
Normal file
29
docs/docs/index.md
Normal file
|
|
@ -0,0 +1,29 @@
|
|||
---
|
||||
title: Introduction
|
||||
sidebar_position: 1
|
||||
---
|
||||
|
||||
Transcribe and translate audio offline on your personal computer. Powered by
|
||||
OpenAI's [Whisper](https://github.com/openai/whisper).
|
||||
|
||||

|
||||
[](https://github.com/chidiwilliams/buzz/actions/workflows/ci.yml)
|
||||
[](https://codecov.io/github/chidiwilliams/buzz)
|
||||

|
||||
[](https://GitHub.com/chidiwilliams/buzz/releases/)
|
||||
|
||||
> Buzz is better on the App Store. Get a Mac-native version of Buzz with a cleaner look, audio playback, drag-and-drop import, transcript editing, search, and much more.
|
||||
> <a href="https://apps.apple.com/us/app/buzz-captions/id6446018936?mt=12&itsct=apps_box_badge&itscg=30200"><img src="https://tools.applemediaservices.com/api/badges/download-on-the-mac-app-store/black/en-us?size=250x83&releaseDate=1679529600" alt="Download on the Mac App Store" /></a>
|
||||
|
||||
## Features
|
||||
|
||||
- Import audio and video files and export transcripts to TXT, SRT, and
|
||||
VTT ([Demo](https://www.loom.com/share/cf263b099ac3481082bb56d19b7c87fe))
|
||||
- Transcription and translation from your computer's microphones to text (Resource-intensive and may not be
|
||||
real-time, [Demo](https://www.loom.com/share/564b753eb4d44b55b985b8abd26b55f7))
|
||||
- Supports [Whisper](https://github.com/openai/whisper#available-models-and-languages),
|
||||
[Whisper.cpp](https://github.com/ggerganov/whisper.cpp), [Faster Whisper](https://github.com/guillaumekln/faster-whisper),
|
||||
[Whisper-compatible Hugging Face models](https://huggingface.co/models?other=whisper), and
|
||||
the [OpenAI Whisper API](https://platform.openai.com/docs/api-reference/introduction)
|
||||
- [Command-Line Interface](#command-line-interface)
|
||||
- Available on Mac, Windows, and Linux
|
||||
43
docs/docs/installation.md
Normal file
43
docs/docs/installation.md
Normal file
|
|
@ -0,0 +1,43 @@
|
|||
---
|
||||
title: Installation
|
||||
sidebar_position: 2
|
||||
---
|
||||
|
||||
To install Buzz, download the [latest version](https://github.com/chidiwilliams/buzz/releases/latest) for your operating
|
||||
system. Buzz is available on **Mac** (Intel), **Windows**, and **Linux**. (For Apple Silicon, please see
|
||||
the [App Store version](https://apps.apple.com/us/app/buzz-captions/id6446018936?mt=12&itsct=apps_box_badge&itscg=30200).)
|
||||
|
||||
## macOS (Intel, macOS 11.7 and later)
|
||||
|
||||
Install via [brew](https://brew.sh/):
|
||||
|
||||
```shell
|
||||
brew install --cask buzz
|
||||
```
|
||||
|
||||
Alternatively, download and run the `Buzz-x.y.z.dmg` file.
|
||||
|
||||
For Mac Silicon (and for a better experience on Mac Intel),
|
||||
download [Buzz Captions](https://apps.apple.com/us/app/buzz-captions/id6446018936?mt=12&itsct=apps_box_badge&itscg=30200)
|
||||
on the App Store.
|
||||
|
||||
## Windows (Windows 10 and later)
|
||||
|
||||
Download and run the `Buzz-x.y.z.exe` file.
|
||||
|
||||
## Linux
|
||||
|
||||
```shell
|
||||
sudo apt-get install libportaudio2
|
||||
sudo snap install buzz
|
||||
```
|
||||
|
||||
[](https://snapcraft.io/buzz)
|
||||
|
||||
Alternatively, on Ubuntu 20.04 and later, install the dependencies:
|
||||
|
||||
```shell
|
||||
sudo apt-get install libportaudio2
|
||||
```
|
||||
|
||||
Then, download and extract the `Buzz-x.y.z-unix.tar.gz` file
|
||||
75
docs/docs/usage.md
Normal file
75
docs/docs/usage.md
Normal file
|
|
@ -0,0 +1,75 @@
|
|||
---
|
||||
title: Usage
|
||||
sidebar_position: 3
|
||||
---
|
||||
|
||||
## File import
|
||||
|
||||
To import a file:
|
||||
|
||||
- Click Import Media File on the File menu (or the '+' icon on the toolbar, or **Command/Ctrl + O**).
|
||||
- Choose an audio or video file.
|
||||
- Select a task, language, and the model settings.
|
||||
- Click Run.
|
||||
- When the transcription status shows 'Completed', double-click on the row (or select the row and click the '⤢' icon) to
|
||||
open the transcription.
|
||||
|
||||
| Field | Options | Default | Description |
|
||||
|--------------------|---------------------|---------|----------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| Export As | "TXT", "SRT", "VTT" | "TXT" | Export file format |
|
||||
| Word-Level Timings | Off / On | Off | If checked, the transcription will generate a separate subtitle line for each word in the audio. Enabled only when "Export As" is set to "SRT" or "VTT". |
|
||||
|
||||
(See the [Live Recording section](#live-recording) for more information about the task, language, and quality settings.)
|
||||
|
||||
[](https://www.loom.com/share/cf263b099ac3481082bb56d19b7c87fe "Media File Import on Buzz")
|
||||
|
||||
## Live recording
|
||||
|
||||
To start a live recording:
|
||||
|
||||
- Select a recording task, language, quality, and microphone.
|
||||
- Click Record.
|
||||
|
||||
> **Note:** Transcribing audio using the default Whisper model is resource-intensive. Consider using the Whisper.cpp
|
||||
> Tiny model to get real-time performance.
|
||||
|
||||
| Field | Options | Default | Description |
|
||||
|------------|------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| Task | "Transcribe", "Translate" | "Transcribe" | "Transcribe" converts the input audio into text in the selected language, while "Translate" converts it into text in English. |
|
||||
| Language | See [Whisper's documentation](https://github.com/openai/whisper#available-models-and-languages) for the full list of supported languages | "Detect Language" | "Detect Language" will try to detect the spoken language in the audio based on the first few seconds. However, selecting a language is recommended (if known) as it will improve transcription quality in many cases. |
|
||||
| Quality | "Very Low", "Low", "Medium", "High" | "Very Low" | The transcription quality determines the Whisper model used for transcription. "Very Low" uses the "tiny" model; "Low" uses the "base" model; "Medium" uses the "small" model; and "High" uses the "medium" model. The larger models produce higher-quality transcriptions, but require more system resources. See [Whisper's documentation](https://github.com/openai/whisper#available-models-and-languages) for more information about the models. |
|
||||
| Microphone | [Available system microphones] | [Default system microphone] | Microphone for recording input audio. |
|
||||
|
||||
[](https://www.loom.com/share/564b753eb4d44b55b985b8abd26b55f7 "Live Recording on Buzz")
|
||||
|
||||
### Record audio playing from computer (macOS)
|
||||
|
||||
To record audio playing from an application on your computer, you may install an audio loopback driver (a program that
|
||||
lets you create virtual audio devices). The rest of this guide will
|
||||
use [BlackHole](https://github.com/ExistentialAudio/BlackHole) on Mac, but you can use other alternatives for your
|
||||
operating system (
|
||||
see [LoopBeAudio](https://nerds.de/en/loopbeaudio.html), [LoopBack](https://rogueamoeba.com/loopback/),
|
||||
and [Virtual Audio Cable](https://vac.muzychenko.net/en/)).
|
||||
|
||||
1. Install [BlackHole via Homebrew](https://github.com/ExistentialAudio/BlackHole#option-2-install-via-homebrew)
|
||||
|
||||
```shell
|
||||
brew install blackhole-2ch
|
||||
```
|
||||
|
||||
2. Open Audio MIDI Setup from Spotlight or from `/Applications/Utilities/Audio Midi Setup.app`.
|
||||
|
||||

|
||||
|
||||
3. Click the '+' icon at the lower left corner and select 'Create Multi-Output Device'.
|
||||
|
||||

|
||||
|
||||
4. Add your default speaker and BlackHole to the multi-output device.
|
||||
|
||||

|
||||
|
||||
5. Select this multi-output device as your speaker (application or system-wide) to play audio into BlackHole.
|
||||
|
||||
6. Open Buzz, select BlackHole as your microphone, and record as before to see transcriptions from the audio playing
|
||||
through BlackHole.
|
||||
88
docs/docusaurus.config.js
Normal file
88
docs/docusaurus.config.js
Normal file
|
|
@ -0,0 +1,88 @@
|
|||
// @ts-check
|
||||
// Note: type annotations allow type checking and IDEs autocompletion
|
||||
|
||||
const lightCodeTheme = require('prism-react-renderer/themes/github');
|
||||
const darkCodeTheme = require('prism-react-renderer/themes/dracula');
|
||||
|
||||
/** @type {import('@docusaurus/types').Config} */
|
||||
const config = {
|
||||
title: 'Buzz',
|
||||
tagline: 'Audio transcription and translation',
|
||||
favicon: 'img/favicon.ico',
|
||||
|
||||
// Set the production url of your site here
|
||||
url: 'https://chidiwilliams.github.io',
|
||||
// Set the /<baseUrl>/ pathname under which your site is served
|
||||
// For GitHub pages deployment, it is often '/<projectName>/'
|
||||
baseUrl: '/buzz/',
|
||||
|
||||
// GitHub pages deployment config.
|
||||
// If you aren't using GitHub pages, you don't need these.
|
||||
organizationName: 'chidiwilliams', // Usually your GitHub org/user name.
|
||||
projectName: 'buzz', // Usually your repo name.
|
||||
|
||||
onBrokenLinks: 'throw',
|
||||
onBrokenMarkdownLinks: 'warn',
|
||||
|
||||
trailingSlash: false,
|
||||
|
||||
// Even if you don't use internalization, you can use this field to set useful
|
||||
// metadata like html lang. For example, if your site is Chinese, you may want
|
||||
// to replace "en" with "zh-Hans".
|
||||
i18n: {
|
||||
defaultLocale: 'en',
|
||||
locales: ['en'],
|
||||
},
|
||||
|
||||
presets: [
|
||||
[
|
||||
'classic',
|
||||
/** @type {import('@docusaurus/preset-classic').Options} */
|
||||
({
|
||||
docs: {
|
||||
sidebarPath: require.resolve('./sidebars.js'),
|
||||
},
|
||||
blog: {
|
||||
showReadingTime: true,
|
||||
},
|
||||
theme: {
|
||||
customCss: require.resolve('./src/css/custom.css'),
|
||||
},
|
||||
}),
|
||||
],
|
||||
],
|
||||
|
||||
themeConfig:
|
||||
/** @type {import('@docusaurus/preset-classic').ThemeConfig} */
|
||||
({
|
||||
// Replace with your project's social card
|
||||
image: 'img/favicon.ico',
|
||||
navbar: {
|
||||
title: 'Buzz',
|
||||
logo: {
|
||||
alt: 'Buzz',
|
||||
src: 'img/favicon.ico',
|
||||
},
|
||||
items: [
|
||||
{
|
||||
type: 'docSidebar',
|
||||
sidebarId: 'tutorialSidebar',
|
||||
position: 'left',
|
||||
label: 'Docs',
|
||||
},
|
||||
// {to: '/blog', label: 'Blog', position: 'left'},
|
||||
{
|
||||
href: 'https://github.com/chidiwilliams/buzz',
|
||||
label: 'GitHub',
|
||||
position: 'right',
|
||||
},
|
||||
],
|
||||
},
|
||||
prism: {
|
||||
theme: lightCodeTheme,
|
||||
darkTheme: darkCodeTheme,
|
||||
},
|
||||
}),
|
||||
};
|
||||
|
||||
module.exports = config;
|
||||
12662
docs/package-lock.json
generated
Normal file
12662
docs/package-lock.json
generated
Normal file
File diff suppressed because it is too large
Load diff
46
docs/package.json
Normal file
46
docs/package.json
Normal file
|
|
@ -0,0 +1,46 @@
|
|||
{
|
||||
"name": "docs",
|
||||
"version": "0.0.0",
|
||||
"private": true,
|
||||
"scripts": {
|
||||
"docusaurus": "docusaurus",
|
||||
"start": "docusaurus start",
|
||||
"build": "docusaurus build",
|
||||
"swizzle": "docusaurus swizzle",
|
||||
"deploy": "docusaurus deploy",
|
||||
"clear": "docusaurus clear",
|
||||
"serve": "docusaurus serve",
|
||||
"write-translations": "docusaurus write-translations",
|
||||
"write-heading-ids": "docusaurus write-heading-ids",
|
||||
"typecheck": "tsc"
|
||||
},
|
||||
"dependencies": {
|
||||
"@docusaurus/core": "2.4.1",
|
||||
"@docusaurus/preset-classic": "2.4.1",
|
||||
"@mdx-js/react": "^1.6.22",
|
||||
"clsx": "^1.2.1",
|
||||
"prism-react-renderer": "^1.3.5",
|
||||
"react": "^17.0.2",
|
||||
"react-dom": "^17.0.2"
|
||||
},
|
||||
"devDependencies": {
|
||||
"@docusaurus/module-type-aliases": "2.4.1",
|
||||
"@tsconfig/docusaurus": "^1.0.5",
|
||||
"typescript": "^4.7.4"
|
||||
},
|
||||
"browserslist": {
|
||||
"production": [
|
||||
">0.5%",
|
||||
"not dead",
|
||||
"not op_mini all"
|
||||
],
|
||||
"development": [
|
||||
"last 1 chrome version",
|
||||
"last 1 firefox version",
|
||||
"last 1 safari version"
|
||||
]
|
||||
},
|
||||
"engines": {
|
||||
"node": ">=16.14"
|
||||
}
|
||||
}
|
||||
33
docs/sidebars.js
Normal file
33
docs/sidebars.js
Normal file
|
|
@ -0,0 +1,33 @@
|
|||
/**
|
||||
* Creating a sidebar enables you to:
|
||||
- create an ordered group of docs
|
||||
- render a sidebar for each doc of that group
|
||||
- provide next/previous navigation
|
||||
|
||||
The sidebars can be generated from the filesystem, or explicitly defined here.
|
||||
|
||||
Create as many sidebars as you want.
|
||||
*/
|
||||
|
||||
// @ts-check
|
||||
|
||||
/** @type {import('@docusaurus/plugin-content-docs').SidebarsConfig} */
|
||||
const sidebars = {
|
||||
// By default, Docusaurus generates a sidebar from the docs folder structure
|
||||
tutorialSidebar: [{type: 'autogenerated', dirName: '.'}],
|
||||
|
||||
// But you can create a sidebar manually
|
||||
/*
|
||||
tutorialSidebar: [
|
||||
'intro',
|
||||
'hello',
|
||||
{
|
||||
type: 'category',
|
||||
label: 'Tutorial',
|
||||
items: ['tutorial-basics/create-a-document'],
|
||||
},
|
||||
],
|
||||
*/
|
||||
};
|
||||
|
||||
module.exports = sidebars;
|
||||
30
docs/src/css/custom.css
Normal file
30
docs/src/css/custom.css
Normal file
|
|
@ -0,0 +1,30 @@
|
|||
/**
|
||||
* Any CSS included here will be global. The classic template
|
||||
* bundles Infima by default. Infima is a CSS framework designed to
|
||||
* work well for content-centric websites.
|
||||
*/
|
||||
|
||||
/* You can override the default Infima variables here. */
|
||||
:root {
|
||||
--ifm-color-primary: #c13a3a;
|
||||
--ifm-color-primary-dark: #29784c;
|
||||
--ifm-color-primary-darker: #277148;
|
||||
--ifm-color-primary-darkest: #205d3b;
|
||||
--ifm-color-primary-light: #33925d;
|
||||
--ifm-color-primary-lighter: #359962;
|
||||
--ifm-color-primary-lightest: #3cad6e;
|
||||
--ifm-code-font-size: 95%;
|
||||
--docusaurus-highlighted-code-line-bg: rgba(0, 0, 0, 0.1);
|
||||
}
|
||||
|
||||
/* For readability concerns, you should choose a lighter palette in dark mode. */
|
||||
[data-theme='dark'] {
|
||||
--ifm-color-primary: #ffa9a9;
|
||||
--ifm-color-primary-dark: #21af90;
|
||||
--ifm-color-primary-darker: #1fa588;
|
||||
--ifm-color-primary-darkest: #1a8870;
|
||||
--ifm-color-primary-light: #29d5b0;
|
||||
--ifm-color-primary-lighter: #32d8b4;
|
||||
--ifm-color-primary-lightest: #4fddbf;
|
||||
--docusaurus-highlighted-code-line-bg: rgba(0, 0, 0, 0.3);
|
||||
}
|
||||
0
docs/src/pages/index.module.css
Normal file
0
docs/src/pages/index.module.css
Normal file
12
docs/src/pages/index.tsx
Normal file
12
docs/src/pages/index.tsx
Normal file
|
|
@ -0,0 +1,12 @@
|
|||
import React from 'react';
|
||||
import clsx from 'clsx';
|
||||
import Link from '@docusaurus/Link';
|
||||
import useDocusaurusContext from '@docusaurus/useDocusaurusContext';
|
||||
import Layout from '@theme/Layout';
|
||||
import {Redirect} from '@docusaurus/router';
|
||||
|
||||
export default function Home(): JSX.Element {
|
||||
return (
|
||||
<Redirect to="/buzz/docs"></Redirect>
|
||||
);
|
||||
}
|
||||
0
docs/static/.nojekyll
vendored
Normal file
0
docs/static/.nojekyll
vendored
Normal file
BIN
docs/static/img/banner.jpg
vendored
Normal file
BIN
docs/static/img/banner.jpg
vendored
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 895 KiB |
BIN
docs/static/img/favicon.ico
vendored
Normal file
BIN
docs/static/img/favicon.ico
vendored
Normal file
Binary file not shown.
|
After Width: | Height: | Size: 32 KiB |
7
docs/tsconfig.json
Normal file
7
docs/tsconfig.json
Normal file
|
|
@ -0,0 +1,7 @@
|
|||
{
|
||||
// This file is not used in compilation. It is here just for a nice editor experience.
|
||||
"extends": "@tsconfig/docusaurus/tsconfig.json",
|
||||
"compilerOptions": {
|
||||
"baseUrl": "."
|
||||
}
|
||||
}
|
||||
Loading…
Add table
Add a link
Reference in a new issue