 +
+  +
+  +
+  +
+  +
+  +
+  +
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+-+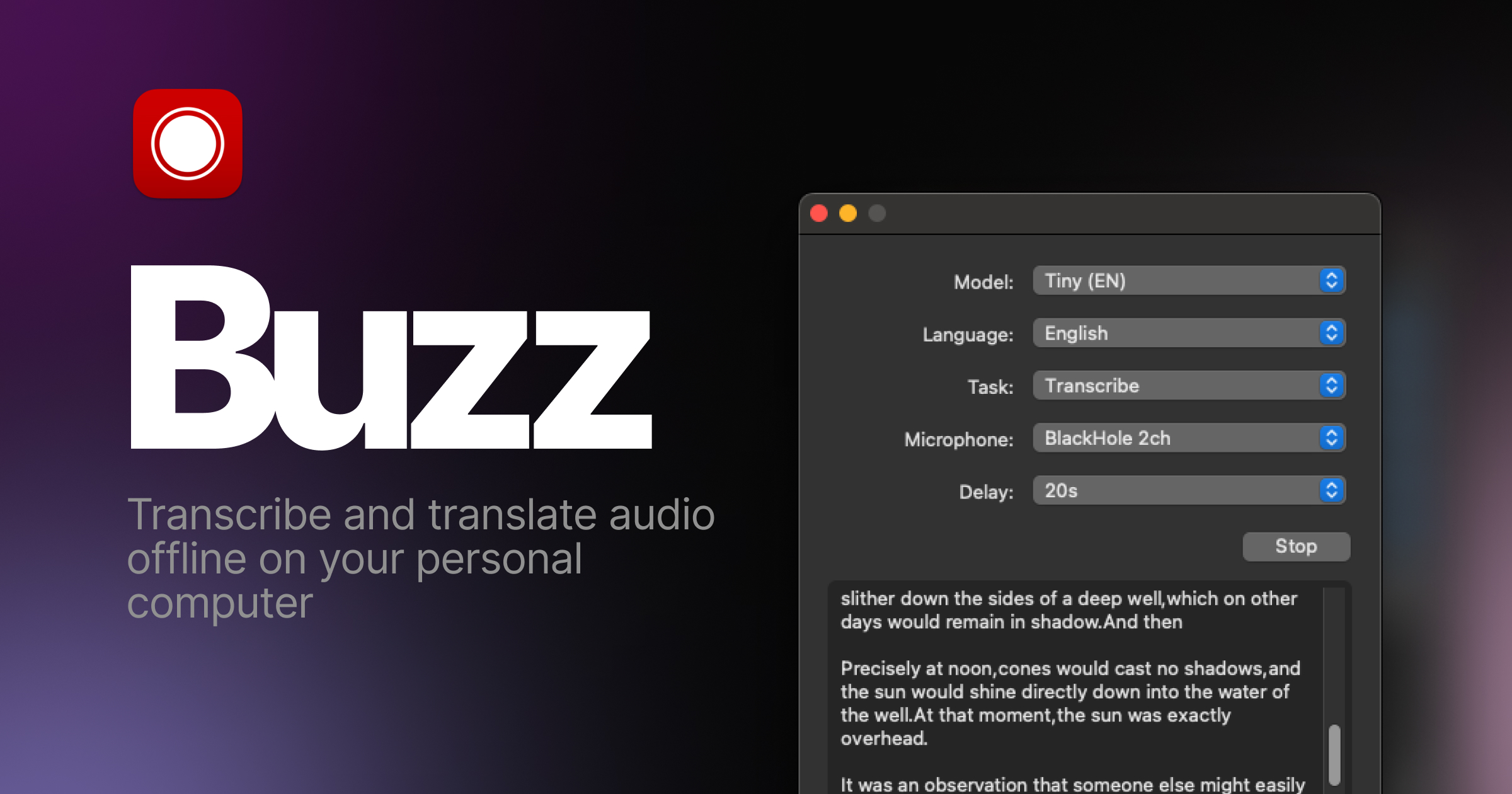 - +## Features +- Transcribe audio and video files or Youtube links +- Live realtime audio transcription from microphone + - Presentation window for easy accessibility during events and presentations +- Speech separation before transcription for better accuracy on noisy audio +- Speaker identification in transcribed media +- Multiple whisper backend support + - CUDA acceleration support for Nvidia GPUs + - Apple Silicon support for Macs + - Vulkan acceleration support for Whisper.cpp on most GPUs, including integrated GPUs +- Export transcripts to TXT, SRT, and VTT +- Advanced Transcription Viewer with search, playback controls, and speed adjustment +- Keyboard shortcuts for efficient navigation +- Watch folder for automatic transcription of new files +- Command-Line Interface for scripting and automation ## Installation -### PyPI - -Install [ffmpeg](https://www.ffmpeg.org/download.html) - -Install Buzz - -```shell -pip install buzz-captions -python -m buzz -``` - ### macOS -Install with [brew utility](https://brew.sh/) - -```shell -brew install --cask buzz -``` - -Or download the `.dmg` from the [releases page](https://github.com/chidiwilliams/buzz/releases/latest). +Download the `.dmg` from the [SourceForge](https://sourceforge.net/projects/buzz-captions/files/). ### Windows -Download and run the `.exe` from the [releases page](https://github.com/chidiwilliams/buzz/releases/latest). +Get the installation files from the [SourceForge](https://sourceforge.net/projects/buzz-captions/files/). App is not signed, you will get a warning when you install it. Select `More info` -> `Run anyway`. -**Alternatively, install with [winget](https://learn.microsoft.com/en-us/windows/package-manager/winget/)** - -```shell -winget install ChidiWilliams.Buzz -``` - -**GPU support for PyPI** - -To have GPU support for Nvidia GPUS on Windows, for PyPI installed version ensure, CUDA support for [torch](https://pytorch.org/get-started/locally/) - -``` -pip3 install -U torch==2.7.1+cu128 torchaudio==2.7.1+cu128 --index-url https://download.pytorch.org/whl/cu128 -pip3 install nvidia-cublas-cu12==12.8.3.14 nvidia-cuda-cupti-cu12==12.8.57 nvidia-cuda-nvrtc-cu12==12.8.61 nvidia-cuda-runtime-cu12==12.8.57 nvidia-cudnn-cu12==9.7.1.26 nvidia-cufft-cu12==11.3.3.41 nvidia-curand-cu12==10.3.9.55 nvidia-cusolver-cu12==11.7.2.55 nvidia-cusparse-cu12==12.5.4.2 nvidia-cusparselt-cu12==0.6.3 nvidia-nvjitlink-cu12==12.8.61 nvidia-nvtx-cu12==12.8.55 --extra-index-url https://pypi.ngc.nvidia.com -``` - ### Linux Buzz is available as a [Flatpak](https://flathub.org/apps/io.github.chidiwilliams.Buzz) or a [Snap](https://snapcraft.io/buzz). @@ -73,26 +52,55 @@ To install flatpak, run: flatpak install flathub io.github.chidiwilliams.Buzz ``` +[](https://flathub.org/en/apps/io.github.chidiwilliams.Buzz) + To install snap, run: ```shell sudo apt-get install libportaudio2 libcanberra-gtk-module libcanberra-gtk3-module sudo snap install buzz -sudo snap connect buzz:password-manager-service +``` + +[](https://snapcraft.io/buzz) + +### PyPI + +Install [ffmpeg](https://www.ffmpeg.org/download.html) + +Ensure you use Python 3.12 environment. + +Install Buzz + +```shell +pip install buzz-captions +python -m buzz +``` + +**GPU support for PyPI** + +To have GPU support for Nvidia GPUS on Windows, for PyPI installed version ensure, CUDA support for [torch](https://pytorch.org/get-started/locally/) + +``` +pip3 install -U torch==2.8.0+cu129 torchaudio==2.8.0+cu129 --index-url https://download.pytorch.org/whl/cu129 +pip3 install nvidia-cublas-cu12==12.9.1.4 nvidia-cuda-cupti-cu12==12.9.79 nvidia-cuda-runtime-cu12==12.9.79 --extra-index-url https://pypi.ngc.nvidia.com ``` ### Latest development version For info on how to get latest development version with latest features and bug fixes see [FAQ](https://chidiwilliams.github.io/buzz/docs/faq#9-where-can-i-get-latest-development-version). +### Support Buzz + +You can help the Buzz by starring 🌟 the repo and sharing it with your friends. + ### ScreenshotsBuzz is better on the App Store. Get a Mac-native version of Buzz with a cleaner look, audio playback, drag-and-drop import, transcript editing, search, and much more.
--
-
-
-
-
-
-
+  +
+  +
+  +
+  +
+  +
+  +
+ 
-- ## 功能 - 导入音频和视频文件,并将转录内容导出为 TXT、SRT 和 VTT 格式([演示](https://www.loom.com/share/cf263b099ac3481082bb56d19b7c87fe)) diff --git a/docs/i18n/zh/docusaurus-plugin-content-docs/current/installation.md b/docs/i18n/zh/docusaurus-plugin-content-docs/current/installation.md index 2ce56a94..b3bbc7c1 100644 --- a/docs/i18n/zh/docusaurus-plugin-content-docs/current/installation.md +++ b/docs/i18n/zh/docusaurus-plugin-content-docs/current/installation.md @@ -3,7 +3,7 @@ title: 安装 sidebar_position: 2 --- -要安装 Buzz,请下载适用于您操作系统的[最新版本](https://github.com/chidiwilliams/buzz/releases/latest)。Buzz 支持 **Mac**(Intel)、**Windows** 和 **Linux** 系统。(对于 Apple Silicon 用户,请参阅 [App Store 版本](https://apps.apple.com/us/app/buzz-captions/id6446018936?mt=12&itsct=apps_box_badge&itscg=30200)。) +要安装 Buzz,请下载适用于您操作系统的[最新版本](https://github.com/chidiwilliams/buzz/releases/latest)。Buzz 支持 **Mac**(Intel)、**Windows** 和 **Linux** 系统。 ## macOS(Intel,macOS 11.7 及更高版本) @@ -15,8 +15,7 @@ brew install --cask buzz 或者,下载并运行 `Buzz-x.y.z.dmg` 文件。 -对于 Mac Silicon 用户(以及希望在 Mac Intel 上获得更好体验的用户), -请从 App Store 下载 [Buzz Captions](https://apps.apple.com/us/app/buzz-captions/id6446018936?mt=12&itsct=apps_box_badge&itscg=30200)。 +对于 Mac Silicon 用户(以及希望在 Mac Intel 上获得更好体验的用户)。 ## Windows(Windows 10 及更高版本) diff --git a/flatpak/run-buzz.sh b/flatpak/run-buzz.sh index fa136c3b..f32217ec 100644 --- a/flatpak/run-buzz.sh +++ b/flatpak/run-buzz.sh @@ -1,3 +1,5 @@ #!/bin/sh echo "Running buzz..." +echo "Note: ffmpeg errors are safe to ignore" + python -m buzz \ No newline at end of file diff --git a/hatch_build.py b/hatch_build.py index b7267b85..0aeeab4c 100644 --- a/hatch_build.py +++ b/hatch_build.py @@ -66,6 +66,70 @@ class CustomBuildHook(BuildHookInterface): print(result.stderr, file=sys.stderr) print("Successfully built whisper.cpp binaries") + # Run the make command for translation files + result = subprocess.run( + ["make", "translation_mo"], + cwd=project_root, + check=True, + capture_output=True, + text=True + ) + print(result.stdout) + if result.stderr: + print(result.stderr, file=sys.stderr) + print("Successfully compiled translation files") + + # Build ctc_forced_aligner C++ extension in-place + print("Building ctc_forced_aligner C++ extension...") + ctc_aligner_dir = project_root / "ctc_forced_aligner" + + # Apply local patches before building. + # Uses --check first to avoid touching the working tree unnecessarily, + # which is safer in a detached-HEAD submodule. + patches_dir = project_root / "patches" + for patch_file in sorted(patches_dir.glob("ctc_forced_aligner_*.patch")): + # Dry-run forward: succeeds only if patch is NOT yet applied. + check_forward = subprocess.run( + ["git", "apply", "--check", "--ignore-whitespace", str(patch_file)], + cwd=ctc_aligner_dir, + capture_output=True, + text=True, + ) + if check_forward.returncode == 0: + # Patch can be applied — do it for real. + subprocess.run( + ["git", "apply", "--ignore-whitespace", str(patch_file)], + cwd=ctc_aligner_dir, + check=True, + capture_output=True, + text=True, + ) + print(f"Applied patch: {patch_file.name}") + else: + # Dry-run failed — either already applied or genuinely broken. + check_reverse = subprocess.run( + ["git", "apply", "--check", "--reverse", "--ignore-whitespace", str(patch_file)], + cwd=ctc_aligner_dir, + capture_output=True, + text=True, + ) + if check_reverse.returncode == 0: + print(f"Patch already applied (skipping): {patch_file.name}") + else: + print(f"WARNING: could not apply patch {patch_file.name}: {check_forward.stderr}", file=sys.stderr) + + result = subprocess.run( + [sys.executable, "setup.py", "build_ext", "--inplace"], + cwd=ctc_aligner_dir, + check=True, + capture_output=True, + text=True + ) + print(result.stdout) + if result.stderr: + print(result.stderr, file=sys.stderr) + print("Successfully built ctc_forced_aligner C++ extension") + # Force include all files in buzz/whisper_cpp directory whisper_cpp_dir = project_root / "buzz" / "whisper_cpp" if whisper_cpp_dir.exists(): @@ -88,6 +152,71 @@ class CustomBuildHook(BuildHookInterface): else: print(f"Warning: {whisper_cpp_dir} does not exist after build", file=sys.stderr) + # Force include demucs package at top level (demucs_repo/demucs -> demucs/) + demucs_pkg_dir = project_root / "demucs_repo" / "demucs" + if demucs_pkg_dir.exists(): + # Get all files in the demucs package directory + demucs_files = glob.glob(str(demucs_pkg_dir / "**" / "*"), recursive=True) + + # Filter only files (not directories) + demucs_files = [f for f in demucs_files if Path(f).is_file()] + + # Add them to force_include, mapping to top-level demucs/ + if 'force_include' not in build_data: + build_data['force_include'] = {} + + for file_path in demucs_files: + # Convert to relative path from demucs package dir + rel_from_pkg = Path(file_path).relative_to(demucs_pkg_dir) + # Target path is demucs/在 App Store 下载运行的性能更佳。 获得外观更整洁、音频播放、拖放导入、转录编辑、搜索等功能的原生Mac版本。
--
-- - - ## 安装 **PyPI**: @@ -53,7 +46,6 @@ brew install --cask buzz ```shell sudo apt-get install libportaudio2 libcanberra-gtk-module libcanberra-gtk3-module sudo snap install buzz -sudo snap connect buzz:password-manager-service ``` ### 最新开发者版本 diff --git a/share/applications/buzz.desktop b/share/applications/buzz.desktop new file mode 100644 index 00000000..1e8cf81d --- /dev/null +++ b/share/applications/buzz.desktop @@ -0,0 +1,17 @@ +[Desktop Entry] + +Type=Application + +Encoding=UTF-8 + +Name=Buzz + +Comment=Buzz transcribes and translates audio offline on your personal computer. + +Path=/opt/buzz + +Exec=/opt/buzz/Buzz + +Icon=buzz + +Terminal=false diff --git a/share/icons/io.github.chidiwilliams.Buzz.svg b/share/icons/io.github.chidiwilliams.Buzz.svg index 79604329..d5b67bc0 100644 --- a/share/icons/io.github.chidiwilliams.Buzz.svg +++ b/share/icons/io.github.chidiwilliams.Buzz.svg @@ -1,16 +1,23 @@ \ No newline at end of file +在 App Store 下载运行的性能更佳。 获得外观更整洁、音频播放、拖放导入、转录编辑、搜索等功能的原生Mac版本。
-
- Note: If your system theme is not applied to Buzz, ensure it is in ~/.themes folder. You may need to copy the system themes to this folder cp -r /usr/share/themes/ ~/.themes/.
+ Note: If your system theme is not applied to Buzz, ensure it is in ~/.themes folder. You may need to copy the system themes to this folder cp -r /usr/share/themes/ ~/.themes/ and give Flatpaks access to this folder flatpak override --user --filesystem=~/.themes.
Bug fixes and minor improvements.
+Fixed support for whisper.cpp on older CPUs and issues in speaker identification.
+Adding speaker identification on transcriptions and video support for transcription viewer, improvements to transcription table and support for over 1000 of worlds languages via MMS models as well as separate window to show live transcripts on a projector.
+Release details:
+This release introduces Vulkan GPU support for whisper.cpp making it significantly faster even on laptops. Real-time transcription is possible even with large models on computers with ~5GB RAM video cards. There @@ -77,7 +118,7 @@