mirror of
https://github.com/chidiwilliams/buzz.git
synced 2026-03-16 07:35:49 +01:00
Compare commits
No commits in common. "main" and "v1.4.3" have entirely different histories.
92 changed files with 7904 additions and 16672 deletions
|
|
@ -8,12 +8,5 @@ omit =
|
|||
deepmultilingualpunctuation/*
|
||||
ctc_forced_aligner/*
|
||||
|
||||
[report]
|
||||
exclude_also =
|
||||
if sys.platform == "win32":
|
||||
if platform.system\(\) == "Windows":
|
||||
if platform.system\(\) == "Linux":
|
||||
if platform.system\(\) == "Darwin":
|
||||
|
||||
[html]
|
||||
directory = coverage/html
|
||||
|
|
|
|||
10
.github/workflows/ci.yml
vendored
10
.github/workflows/ci.yml
vendored
|
|
@ -81,7 +81,7 @@ jobs:
|
|||
# Add ubuntu-toolchain-r PPA for newer libstdc++6 with GLIBCXX_3.4.32
|
||||
sudo add-apt-repository ppa:ubuntu-toolchain-r/test -y
|
||||
sudo apt-get update
|
||||
sudo apt-get install -y libstdc++6
|
||||
sudo apt-get install -y gcc-13 g++-13 libstdc++-13-dev
|
||||
fi
|
||||
|
||||
sudo apt-get install libyaml-dev libxkbcommon-x11-0 libxcb-icccm4 libxcb-image0 libxcb-keysyms1 libxcb-randr0 libxcb-render-util0 libxcb-xinerama0 libxcb-shape0 libxcb-cursor0 libportaudio2 gettext libpulse0 libgl1-mesa-dev libvulkan-dev ccache
|
||||
|
|
@ -94,8 +94,6 @@ jobs:
|
|||
run: |
|
||||
uv run make test
|
||||
shell: bash
|
||||
env:
|
||||
PYTHONFAULTHANDLER: "1"
|
||||
|
||||
- name: Upload coverage reports to Codecov with GitHub Action
|
||||
uses: codecov/codecov-action@v4
|
||||
|
|
@ -167,7 +165,7 @@ jobs:
|
|||
# Add ubuntu-toolchain-r PPA for newer libstdc++6 with GLIBCXX_3.4.32
|
||||
sudo add-apt-repository ppa:ubuntu-toolchain-r/test -y
|
||||
sudo apt-get update
|
||||
sudo apt-get install -y libstdc++6
|
||||
sudo apt-get install -y gcc-13 g++-13 libstdc++-13-dev
|
||||
fi
|
||||
|
||||
sudo apt-get install libyaml-dev libxkbcommon-x11-0 libxcb-icccm4 libxcb-image0 libxcb-keysyms1 libxcb-randr0 libxcb-render-util0 libxcb-xinerama0 libxcb-shape0 libxcb-cursor0 libportaudio2 gettext libpulse0 libgl1-mesa-dev libvulkan-dev ccache
|
||||
|
|
@ -176,10 +174,10 @@ jobs:
|
|||
- name: Install dependencies
|
||||
run: uv sync
|
||||
|
||||
- uses: AnimMouse/setup-ffmpeg@v1
|
||||
- uses: AnimMouse/setup-ffmpeg@v1.2.1
|
||||
id: setup-ffmpeg
|
||||
with:
|
||||
version: ${{ matrix.os == 'macos-15-intel' && '7.1.1' || matrix.os == 'macos-latest' && '80' || '8.0' }}
|
||||
version: ${{ matrix.os == 'macos-15-intel' && '7.1.1' || matrix.os == 'macos-latest' && '71' || '7.1' }}
|
||||
|
||||
- name: Install MSVC for Windows
|
||||
run: |
|
||||
|
|
|
|||
51
.github/workflows/snapcraft.yml
vendored
51
.github/workflows/snapcraft.yml
vendored
|
|
@ -14,7 +14,7 @@ concurrency:
|
|||
|
||||
jobs:
|
||||
build:
|
||||
runs-on: ubuntu-24.04
|
||||
runs-on: ubuntu-latest
|
||||
timeout-minutes: 90
|
||||
env:
|
||||
BUZZ_DISABLE_TELEMETRY: true
|
||||
|
|
@ -24,48 +24,31 @@ jobs:
|
|||
# Ideas from https://github.com/orgs/community/discussions/25678
|
||||
- name: Remove unused build tools
|
||||
run: |
|
||||
sudo apt-get remove -y '^llvm-.*'
|
||||
sudo apt-get remove -y 'php.*'
|
||||
sudo apt-get remove -y azure-cli google-cloud-sdk hhvm google-chrome-stable firefox powershell mono-devel || true
|
||||
sudo apt-get autoremove -y
|
||||
sudo apt-get clean
|
||||
python -m pip cache purge
|
||||
rm -rf /opt/hostedtoolcache || true
|
||||
- name: Check available disk space
|
||||
run: |
|
||||
echo "=== Disk space ==="
|
||||
df -h
|
||||
echo "=== Memory ==="
|
||||
free -h
|
||||
- name: Maximize build space
|
||||
uses: easimon/maximize-build-space@master
|
||||
with:
|
||||
root-reserve-mb: 26000
|
||||
swap-size-mb: 1024
|
||||
remove-dotnet: 'true'
|
||||
remove-android: 'true'
|
||||
remove-haskell: 'true'
|
||||
remove-codeql: 'true'
|
||||
remove-docker-images: 'true'
|
||||
- uses: actions/checkout@v4
|
||||
with:
|
||||
submodules: recursive
|
||||
- name: Install Snapcraft and dependencies
|
||||
run: |
|
||||
set -x
|
||||
# Ensure snapd is ready
|
||||
sudo systemctl start snapd.socket
|
||||
sudo snap wait system seed.loaded
|
||||
|
||||
echo "=== Installing snapcraft ==="
|
||||
sudo snap install --classic snapcraft
|
||||
|
||||
echo "=== Installing gnome extension dependencies ==="
|
||||
sudo snap install gnome-46-2404 || { echo "Failed to install gnome-46-2404"; sudo journalctl -u snapd --no-pager -n 50; exit 1; }
|
||||
sudo snap install gnome-46-2404-sdk || { echo "Failed to install gnome-46-2404-sdk"; sudo journalctl -u snapd --no-pager -n 50; exit 1; }
|
||||
|
||||
echo "=== Installing build-snaps ==="
|
||||
sudo snap install --classic astral-uv || { echo "Failed to install astral-uv"; sudo journalctl -u snapd --no-pager -n 50; exit 1; }
|
||||
|
||||
echo "=== Installed snaps ==="
|
||||
snap list
|
||||
- name: Check disk space before build
|
||||
run: df -h
|
||||
- name: Build snap
|
||||
- uses: snapcore/action-build@v1.3.0
|
||||
id: snapcraft
|
||||
env:
|
||||
SNAPCRAFT_BUILD_ENVIRONMENT: host
|
||||
run: |
|
||||
sudo -E snapcraft pack --verbose --destructive-mode
|
||||
echo "snap=$(ls *.snap)" >> $GITHUB_OUTPUT
|
||||
- run: |
|
||||
sudo apt-get update
|
||||
sudo apt-get install libportaudio2 libtbb-dev
|
||||
- run: sudo snap install --devmode *.snap
|
||||
- run: |
|
||||
cd $HOME
|
||||
|
|
|
|||
|
|
@ -46,7 +46,7 @@ datas += collect_data_files("whisper")
|
|||
datas += collect_data_files("demucs", include_py_files=True)
|
||||
datas += collect_data_files("whisper_diarization", include_py_files=True)
|
||||
datas += collect_data_files("deepmultilingualpunctuation", include_py_files=True)
|
||||
datas += collect_data_files("ctc_forced_aligner", include_py_files=True, excludes=["build"])
|
||||
datas += collect_data_files("ctc_forced_aligner", include_py_files=True)
|
||||
datas += collect_data_files("nemo", include_py_files=True)
|
||||
datas += collect_data_files("lightning_fabric", include_py_files=True)
|
||||
datas += collect_data_files("pytorch_lightning", include_py_files=True)
|
||||
|
|
@ -124,9 +124,7 @@ a = Analysis(
|
|||
hookspath=[],
|
||||
hooksconfig={},
|
||||
runtime_hooks=[],
|
||||
# pyarrow is excluded because its Windows wheel requires AVX2 CPU instructions,
|
||||
# causing a crash (0xc000001d) on older hardware. Buzz does not use pyarrow directly;
|
||||
excludes=["pyarrow"],
|
||||
excludes=[],
|
||||
win_no_prefer_redirects=False,
|
||||
win_private_assemblies=False,
|
||||
cipher=block_cipher,
|
||||
|
|
|
|||
42
Makefile
42
Makefile
|
|
@ -1,5 +1,5 @@
|
|||
# Change also in pyproject.toml and buzz/__version__.py
|
||||
version := 1.4.4
|
||||
version := 1.4.3
|
||||
|
||||
mac_app_path := ./dist/Buzz.app
|
||||
mac_zip_path := ./dist/Buzz-${version}-mac.zip
|
||||
|
|
@ -35,11 +35,6 @@ endif
|
|||
COVERAGE_THRESHOLD := 70
|
||||
|
||||
test: buzz/whisper_cpp
|
||||
# A check to get updates of yt-dlp. Should run only on local as part of regular development operations
|
||||
# Sort of a local "update checker"
|
||||
ifndef CI
|
||||
uv lock --upgrade-package yt-dlp
|
||||
endif
|
||||
pytest -s -vv --cov=buzz --cov-report=xml --cov-report=html --benchmark-skip --cov-fail-under=${COVERAGE_THRESHOLD} --cov-config=.coveragerc
|
||||
|
||||
benchmarks: buzz/whisper_cpp
|
||||
|
|
@ -65,7 +60,6 @@ ifeq ($(OS), Windows_NT)
|
|||
cp whisper.cpp/build/bin/Release/whisper-cli.exe buzz/whisper_cpp/
|
||||
cp whisper.cpp/build/bin/Release/whisper-server.exe buzz/whisper_cpp/
|
||||
cp dll_backup/SDL2.dll buzz/whisper_cpp
|
||||
PowerShell -NoProfile -ExecutionPolicy Bypass -Command "if (-not (Test-Path 'buzz\whisper_cpp\ggml-silero-v6.2.0.bin')) { Start-BitsTransfer -Source https://huggingface.co/ggml-org/whisper-vad/resolve/main/ggml-silero-v6.2.0.bin -Destination 'buzz\whisper_cpp\ggml-silero-v6.2.0.bin' }"
|
||||
endif
|
||||
|
||||
ifeq ($(shell uname -s), Linux)
|
||||
|
|
@ -78,12 +72,13 @@ ifeq ($(shell uname -s), Linux)
|
|||
cmake --build whisper.cpp/build -j --config Release --verbose
|
||||
cp whisper.cpp/build/bin/whisper-cli buzz/whisper_cpp/ || true
|
||||
cp whisper.cpp/build/bin/whisper-server buzz/whisper_cpp/ || true
|
||||
cp -P whisper.cpp/build/src/libwhisper.so* buzz/whisper_cpp/ || true
|
||||
cp -P whisper.cpp/build/ggml/src/libggml.so* buzz/whisper_cpp/ || true
|
||||
cp -P whisper.cpp/build/ggml/src/libggml-base.so* buzz/whisper_cpp/ || true
|
||||
cp -P whisper.cpp/build/ggml/src/libggml-cpu.so* buzz/whisper_cpp/ || true
|
||||
cp -P whisper.cpp/build/ggml/src/ggml-vulkan/libggml-vulkan.so* buzz/whisper_cpp/ || true
|
||||
test -f buzz/whisper_cpp/ggml-silero-v6.2.0.bin || curl -L -o buzz/whisper_cpp/ggml-silero-v6.2.0.bin https://huggingface.co/ggml-org/whisper-vad/resolve/main/ggml-silero-v6.2.0.bin
|
||||
cp whisper.cpp/build/src/libwhisper.so buzz/whisper_cpp/ || true
|
||||
cp whisper.cpp/build/src/libwhisper.so.1 buzz/whisper_cpp/ || true
|
||||
cp whisper.cpp/build/src/libwhisper.so.1.8.2 buzz/whisper_cpp/ || true
|
||||
cp whisper.cpp/build/ggml/src/libggml.so buzz/whisper_cpp/ || true
|
||||
cp whisper.cpp/build/ggml/src/libggml-base.so buzz/whisper_cpp/ || true
|
||||
cp whisper.cpp/build/ggml/src/libggml-cpu.so buzz/whisper_cpp/ || true
|
||||
cp whisper.cpp/build/ggml/src/ggml-vulkan/libggml-vulkan.so buzz/whisper_cpp/ || true
|
||||
endif
|
||||
|
||||
# Build on Macs
|
||||
|
|
@ -103,7 +98,6 @@ endif
|
|||
cp whisper.cpp/build/bin/whisper-server buzz/whisper_cpp/ || true
|
||||
cp whisper.cpp/build/src/libwhisper.dylib buzz/whisper_cpp/ || true
|
||||
cp whisper.cpp/build/ggml/src/libggml* buzz/whisper_cpp/ || true
|
||||
test -f buzz/whisper_cpp/ggml-silero-v6.2.0.bin || curl -L -o buzz/whisper_cpp/ggml-silero-v6.2.0.bin https://huggingface.co/ggml-org/whisper-vad/resolve/main/ggml-silero-v6.2.0.bin
|
||||
endif
|
||||
|
||||
# Prints all the Mac developer identities used for code signing
|
||||
|
|
@ -196,26 +190,26 @@ gh_upgrade_pr:
|
|||
# Internationalization
|
||||
|
||||
translation_po_all:
|
||||
$(MAKE) translation_po locale=ca_ES
|
||||
$(MAKE) translation_po locale=da_DK
|
||||
$(MAKE) translation_po locale=de_DE
|
||||
$(MAKE) translation_po locale=en_US
|
||||
$(MAKE) translation_po locale=ca_ES
|
||||
$(MAKE) translation_po locale=es_ES
|
||||
$(MAKE) translation_po locale=it_IT
|
||||
$(MAKE) translation_po locale=ja_JP
|
||||
$(MAKE) translation_po locale=lv_LV
|
||||
$(MAKE) translation_po locale=nl
|
||||
$(MAKE) translation_po locale=pl_PL
|
||||
$(MAKE) translation_po locale=pt_BR
|
||||
$(MAKE) translation_po locale=uk_UA
|
||||
$(MAKE) translation_po locale=zh_CN
|
||||
$(MAKE) translation_po locale=zh_TW
|
||||
$(MAKE) translation_po locale=it_IT
|
||||
$(MAKE) translation_po locale=lv_LV
|
||||
$(MAKE) translation_po locale=uk_UA
|
||||
$(MAKE) translation_po locale=ja_JP
|
||||
$(MAKE) translation_po locale=da_DK
|
||||
$(MAKE) translation_po locale=de_DE
|
||||
$(MAKE) translation_po locale=nl
|
||||
$(MAKE) translation_po locale=pt_BR
|
||||
|
||||
TMP_POT_FILE_PATH := $(shell mktemp)
|
||||
PO_FILE_PATH := buzz/locale/${locale}/LC_MESSAGES/buzz.po
|
||||
translation_po:
|
||||
mkdir -p buzz/locale/${locale}/LC_MESSAGES
|
||||
xgettext --from-code=UTF-8 --add-location=file -o "${TMP_POT_FILE_PATH}" -l python $(shell find buzz -name '*.py')
|
||||
xgettext --from-code=UTF-8 -o "${TMP_POT_FILE_PATH}" -l python $(shell find buzz -name '*.py')
|
||||
sed -i.bak 's/CHARSET/UTF-8/' ${TMP_POT_FILE_PATH}
|
||||
if [ ! -f ${PO_FILE_PATH} ]; then \
|
||||
msginit --no-translator --input=${TMP_POT_FILE_PATH} --output-file=${PO_FILE_PATH}; \
|
||||
|
|
|
|||
20
README.md
20
README.md
|
|
@ -13,7 +13,7 @@ OpenAI's [Whisper](https://github.com/openai/whisper).
|
|||

|
||||
[](https://GitHub.com/chidiwilliams/buzz/releases/)
|
||||
|
||||
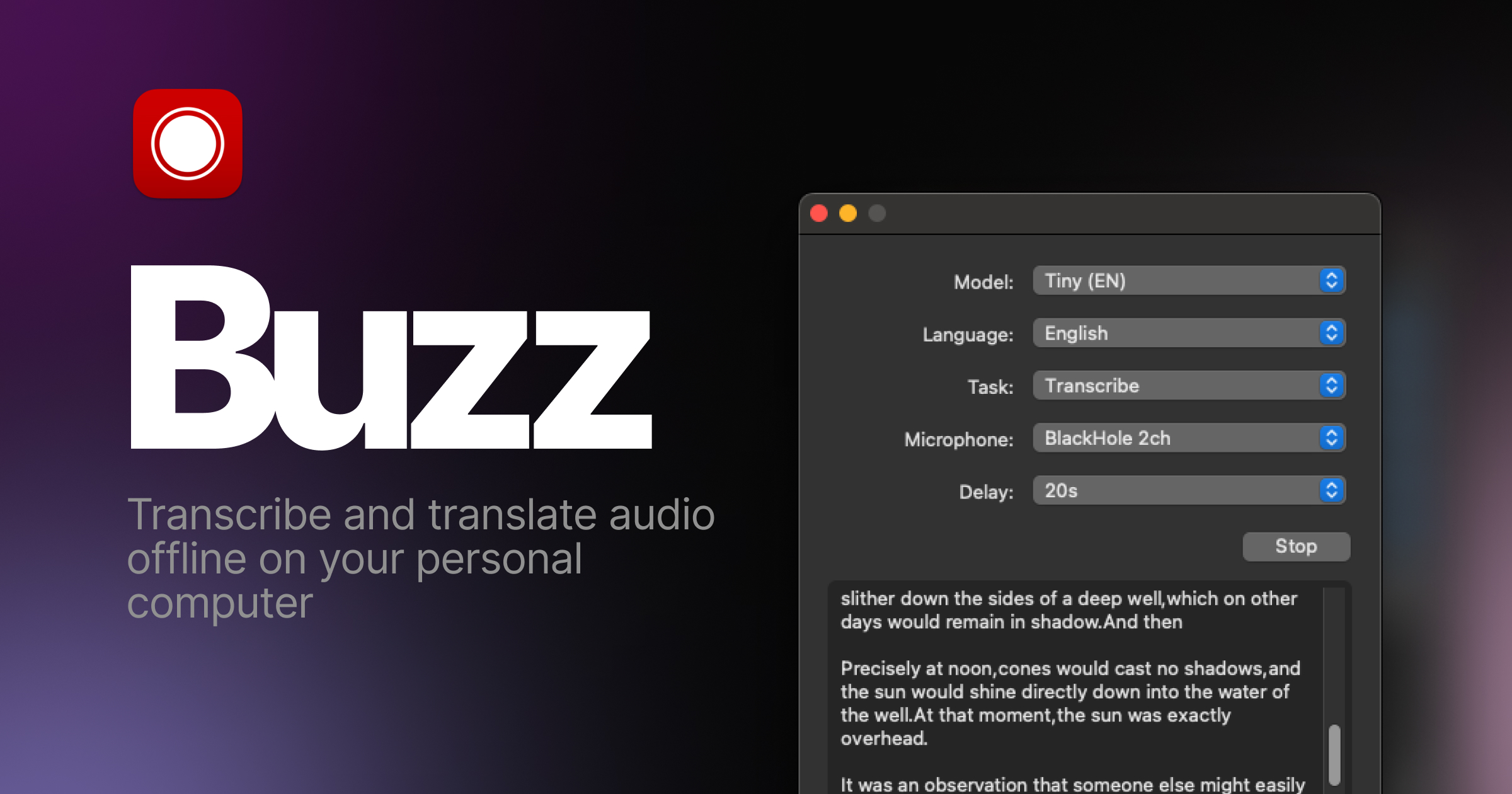
|
||||

|
||||
|
||||
## Features
|
||||
- Transcribe audio and video files or Youtube links
|
||||
|
|
@ -88,19 +88,15 @@ pip3 install nvidia-cublas-cu12==12.9.1.4 nvidia-cuda-cupti-cu12==12.9.79 nvidia
|
|||
|
||||
For info on how to get latest development version with latest features and bug fixes see [FAQ](https://chidiwilliams.github.io/buzz/docs/faq#9-where-can-i-get-latest-development-version).
|
||||
|
||||
### Support Buzz
|
||||
|
||||
You can help the Buzz by starring 🌟 the repo and sharing it with your friends.
|
||||
|
||||
### Screenshots
|
||||
|
||||
<div style="display: flex; flex-wrap: wrap;">
|
||||
<img alt="File import" src="https://github.com/chidiwilliams/buzz/raw/main/share/screenshots/buzz-1-import.png" style="max-width: 18%; margin-right: 1%;" />
|
||||
<img alt="Main screen" src="https://github.com/chidiwilliams/buzz/raw/main/share/screenshots/buzz-2-main_screen.png" style="max-width: 18%; margin-right: 1%; height:auto;" />
|
||||
<img alt="Preferences" src="https://github.com/chidiwilliams/buzz/raw/main/share/screenshots/buzz-3-preferences.png" style="max-width: 18%; margin-right: 1%; height:auto;" />
|
||||
<img alt="Model preferences" src="https://github.com/chidiwilliams/buzz/raw/main/share/screenshots/buzz-3.2-model-preferences.png" style="max-width: 18%; margin-right: 1%; height:auto;" />
|
||||
<img alt="Transcript" src="https://github.com/chidiwilliams/buzz/raw/main/share/screenshots/buzz-4-transcript.png" style="max-width: 18%; margin-right: 1%; height:auto;" />
|
||||
<img alt="Live recording" src="https://github.com/chidiwilliams/buzz/raw/main/share/screenshots/buzz-5-live_recording.png" style="max-width: 18%; margin-right: 1%; height:auto;" />
|
||||
<img alt="Resize" src="https://github.com/chidiwilliams/buzz/raw/main/share/screenshots/buzz-6-resize.png" style="max-width: 18%;" />
|
||||
<img alt="File import" src="share/screenshots/buzz-1-import.png" style="max-width: 18%; margin-right: 1%;" />
|
||||
<img alt="Main screen" src="share/screenshots/buzz-2-main_screen.png" style="max-width: 18%; margin-right: 1%; height:auto;" />
|
||||
<img alt="Preferences" src="share/screenshots/buzz-3-preferences.png" style="max-width: 18%; margin-right: 1%; height:auto;" />
|
||||
<img alt="Model preferences" src="share/screenshots/buzz-3.2-model-preferences.png" style="max-width: 18%; margin-right: 1%; height:auto;" />
|
||||
<img alt="Transcript" src="share/screenshots/buzz-4-transcript.png" style="max-width: 18%; margin-right: 1%; height:auto;" />
|
||||
<img alt="Live recording" src="share/screenshots/buzz-5-live_recording.png" style="max-width: 18%; margin-right: 1%; height:auto;" />
|
||||
<img alt="Resize" src="share/screenshots/buzz-6-resize.png" style="max-width: 18%;" />
|
||||
</div>
|
||||
|
||||
|
|
|
|||
|
|
@ -1 +1 @@
|
|||
VERSION = "1.4.4"
|
||||
VERSION = "1.4.3"
|
||||
|
|
|
|||
{kind=link}
|
|
@ -1 +0,0 @@
|
|||
<svg xmlns="http://www.w3.org/2000/svg" height="48" viewBox="0 -960 960 960" width="48"><path d="M160-200v-60h640v60H160Zm320-136L280-536l42-42 128 128v-310h60v310l128-128 42 42-200 200Z" transform="rotate(180 480 -480)"/></svg>
|
||||
|
Before Width: | Height: | Size: 229 B |
|
|
@ -25,11 +25,8 @@ from buzz.assets import APP_BASE_DIR
|
|||
if getattr(sys, "frozen", False) is False and platform.system() != "Windows":
|
||||
faulthandler.enable()
|
||||
|
||||
# Sets stdout/stderr to no-op TextIO when None (run as Windows GUI with --noconsole).
|
||||
# stdout fix: torch.hub uses sys.stdout.write() for download progress and crashes if None.
|
||||
# stderr fix: Resolves https://github.com/chidiwilliams/buzz/issues/221
|
||||
if sys.stdout is None:
|
||||
sys.stdout = TextIO()
|
||||
# Sets stderr to no-op TextIO when None (run as Windows GUI).
|
||||
# Resolves https://github.com/chidiwilliams/buzz/issues/221
|
||||
if sys.stderr is None:
|
||||
sys.stderr = TextIO()
|
||||
|
||||
|
|
|
|||
|
|
@ -53,7 +53,6 @@ if sys.platform == "win32":
|
|||
|
||||
from demucs import api as demucsApi
|
||||
|
||||
from buzz.locale import _
|
||||
from buzz.model_loader import ModelType
|
||||
from buzz.transcriber.file_transcriber import FileTranscriber
|
||||
from buzz.transcriber.openai_whisper_api_file_transcriber import (
|
||||
|
|
@ -128,19 +127,11 @@ class FileTranscriberQueueWorker(QObject):
|
|||
separator = None
|
||||
separated = None
|
||||
try:
|
||||
# Force CPU if specified, otherwise use CUDA if available
|
||||
force_cpu = os.getenv("BUZZ_FORCE_CPU", "false").lower() == "true"
|
||||
if force_cpu:
|
||||
device = "cpu"
|
||||
else:
|
||||
import torch
|
||||
device = "cuda" if torch.cuda.is_available() else "cpu"
|
||||
separator = demucsApi.Separator(
|
||||
device=device,
|
||||
progress=True,
|
||||
callback=separator_progress_callback,
|
||||
)
|
||||
_origin, separated = separator.separate_audio_file(Path(self.current_task.file_path))
|
||||
_, separated = separator.separate_audio_file(Path(self.current_task.file_path))
|
||||
|
||||
task_file_path = Path(self.current_task.file_path)
|
||||
self.speech_path = task_file_path.with_name(f"{task_file_path.stem}_speech.mp3")
|
||||
|
|
@ -149,12 +140,6 @@ class FileTranscriberQueueWorker(QObject):
|
|||
self.current_task.file_path = str(self.speech_path)
|
||||
except Exception as e:
|
||||
logging.error(f"Error during speech extraction: {e}", exc_info=True)
|
||||
self.task_error.emit(
|
||||
self.current_task,
|
||||
_("Speech extraction failed! Check your internet connection — a model may need to be downloaded."),
|
||||
)
|
||||
self.is_running = False
|
||||
return
|
||||
finally:
|
||||
# Release memory used by speech extractor
|
||||
del separator, separated
|
||||
|
|
|
|||
File diff suppressed because it is too large
Load diff
File diff suppressed because it is too large
Load diff
File diff suppressed because it is too large
Load diff
File diff suppressed because it is too large
Load diff
File diff suppressed because it is too large
Load diff
File diff suppressed because it is too large
Load diff
File diff suppressed because it is too large
Load diff
File diff suppressed because it is too large
Load diff
File diff suppressed because it is too large
Load diff
File diff suppressed because it is too large
Load diff
File diff suppressed because it is too large
Load diff
File diff suppressed because it is too large
Load diff
File diff suppressed because it is too large
Load diff
File diff suppressed because it is too large
Load diff
|
|
@ -9,9 +9,6 @@ from PyQt6.QtCore import QObject, pyqtSignal
|
|||
class RecordingAmplitudeListener(QObject):
|
||||
stream: Optional[sounddevice.InputStream] = None
|
||||
amplitude_changed = pyqtSignal(float)
|
||||
average_amplitude_changed = pyqtSignal(float)
|
||||
|
||||
ACCUMULATION_SECONDS = 1
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
|
|
@ -20,9 +17,6 @@ class RecordingAmplitudeListener(QObject):
|
|||
):
|
||||
super().__init__(parent)
|
||||
self.input_device_index = input_device_index
|
||||
self.buffer = np.ndarray([], dtype=np.float32)
|
||||
self.accumulation_size = 0
|
||||
self._active = True
|
||||
|
||||
def start_recording(self):
|
||||
try:
|
||||
|
|
@ -33,24 +27,16 @@ class RecordingAmplitudeListener(QObject):
|
|||
callback=self.stream_callback,
|
||||
)
|
||||
self.stream.start()
|
||||
self.accumulation_size = int(self.stream.samplerate * self.ACCUMULATION_SECONDS)
|
||||
except Exception as e:
|
||||
except sounddevice.PortAudioError:
|
||||
self.stop_recording()
|
||||
logging.exception("Failed to start audio stream on device %s: %s", self.input_device_index, e)
|
||||
logging.exception("")
|
||||
|
||||
def stop_recording(self):
|
||||
self._active = False
|
||||
if self.stream is not None:
|
||||
self.stream.stop()
|
||||
self.stream.close()
|
||||
|
||||
def stream_callback(self, in_data: np.ndarray, frame_count, time_info, status):
|
||||
if not self._active:
|
||||
return
|
||||
chunk = in_data.ravel()
|
||||
self.amplitude_changed.emit(float(np.sqrt(np.mean(chunk**2))))
|
||||
|
||||
self.buffer = np.append(self.buffer, chunk)
|
||||
if self.buffer.size >= self.accumulation_size:
|
||||
self.average_amplitude_changed.emit(float(np.sqrt(np.mean(self.buffer**2))))
|
||||
self.buffer = np.ndarray([], dtype=np.float32)
|
||||
amplitude = np.sqrt(np.mean(chunk**2)) # root-mean-square
|
||||
self.amplitude_changed.emit(amplitude)
|
||||
|
|
|
|||
|
|
@ -17,6 +17,7 @@ class Settings:
|
|||
RECORDING_TRANSCRIBER_TASK = "recording-transcriber/task"
|
||||
RECORDING_TRANSCRIBER_MODEL = "recording-transcriber/model"
|
||||
RECORDING_TRANSCRIBER_LANGUAGE = "recording-transcriber/language"
|
||||
RECORDING_TRANSCRIBER_TEMPERATURE = "recording-transcriber/temperature"
|
||||
RECORDING_TRANSCRIBER_INITIAL_PROMPT = "recording-transcriber/initial-prompt"
|
||||
RECORDING_TRANSCRIBER_ENABLE_LLM_TRANSLATION = "recording-transcriber/enable-llm-translation"
|
||||
RECORDING_TRANSCRIBER_LLM_MODEL = "recording-transcriber/llm-model"
|
||||
|
|
@ -24,13 +25,6 @@ class Settings:
|
|||
RECORDING_TRANSCRIBER_EXPORT_ENABLED = "recording-transcriber/export-enabled"
|
||||
RECORDING_TRANSCRIBER_EXPORT_FOLDER = "recording-transcriber/export-folder"
|
||||
RECORDING_TRANSCRIBER_MODE = "recording-transcriber/mode"
|
||||
RECORDING_TRANSCRIBER_SILENCE_THRESHOLD = "recording-transcriber/silence-threshold"
|
||||
RECORDING_TRANSCRIBER_LINE_SEPARATOR = "recording-transcriber/line-separator"
|
||||
RECORDING_TRANSCRIBER_TRANSCRIPTION_STEP = "recording-transcriber/transcription-step"
|
||||
RECORDING_TRANSCRIBER_EXPORT_FILE_TYPE = "recording-transcriber/export-file-type"
|
||||
RECORDING_TRANSCRIBER_EXPORT_MAX_ENTRIES = "recording-transcriber/export-max-entries"
|
||||
RECORDING_TRANSCRIBER_EXPORT_FILE_NAME = "recording-transcriber/export-file-name"
|
||||
RECORDING_TRANSCRIBER_HIDE_UNCONFIRMED = "recording-transcriber/hide-unconfirmed"
|
||||
|
||||
PRESENTATION_WINDOW_TEXT_COLOR = "presentation-window/text-color"
|
||||
PRESENTATION_WINDOW_BACKGROUND_COLOR = "presentation-window/background-color"
|
||||
|
|
@ -40,6 +34,7 @@ class Settings:
|
|||
FILE_TRANSCRIBER_TASK = "file-transcriber/task"
|
||||
FILE_TRANSCRIBER_MODEL = "file-transcriber/model"
|
||||
FILE_TRANSCRIBER_LANGUAGE = "file-transcriber/language"
|
||||
FILE_TRANSCRIBER_TEMPERATURE = "file-transcriber/temperature"
|
||||
FILE_TRANSCRIBER_INITIAL_PROMPT = "file-transcriber/initial-prompt"
|
||||
FILE_TRANSCRIBER_ENABLE_LLM_TRANSLATION = "file-transcriber/enable-llm-translation"
|
||||
FILE_TRANSCRIBER_LLM_MODEL = "file-transcriber/llm-model"
|
||||
|
|
@ -82,9 +77,6 @@ class Settings:
|
|||
FORCE_CPU = "force-cpu"
|
||||
REDUCE_GPU_MEMORY = "reduce-gpu-memory"
|
||||
|
||||
LAST_UPDATE_CHECK = "update/last-check"
|
||||
UPDATE_AVAILABLE_VERSION = "update/available-version"
|
||||
|
||||
def get_user_identifier(self) -> str:
|
||||
user_id = self.value(self.Key.USER_IDENTIFIER, "")
|
||||
if not user_id:
|
||||
|
|
|
|||
|
|
@ -155,16 +155,13 @@ class FileTranscriber(QObject):
|
|||
or self.transcription_task.file_path
|
||||
)
|
||||
if source_path and os.path.exists(source_path):
|
||||
if self.transcription_task.delete_source_file:
|
||||
os.remove(source_path)
|
||||
else:
|
||||
shutil.move(
|
||||
source_path,
|
||||
os.path.join(
|
||||
self.transcription_task.output_directory,
|
||||
os.path.basename(source_path),
|
||||
),
|
||||
)
|
||||
shutil.move(
|
||||
source_path,
|
||||
os.path.join(
|
||||
self.transcription_task.output_directory,
|
||||
os.path.basename(source_path),
|
||||
),
|
||||
)
|
||||
|
||||
def on_download_progress(self, data: dict):
|
||||
if data["status"] == "downloading":
|
||||
|
|
@ -179,6 +176,7 @@ class FileTranscriber(QObject):
|
|||
...
|
||||
|
||||
|
||||
# TODO: Move to transcription service
|
||||
def write_output(
|
||||
path: str,
|
||||
segments: List[Segment],
|
||||
|
|
|
|||
|
|
@ -26,7 +26,7 @@ from buzz.locale import _
|
|||
from buzz.assets import APP_BASE_DIR
|
||||
from buzz.model_loader import ModelType, map_language_to_mms
|
||||
from buzz.settings.settings import Settings
|
||||
from buzz.transcriber.transcriber import TranscriptionOptions, Task, DEFAULT_WHISPER_TEMPERATURE
|
||||
from buzz.transcriber.transcriber import TranscriptionOptions, Task
|
||||
from buzz.transformers_whisper import TransformersTranscriber
|
||||
from buzz.settings.recording_transcriber_mode import RecordingTranscriberMode
|
||||
|
||||
|
|
@ -38,9 +38,6 @@ class RecordingTranscriber(QObject):
|
|||
transcription = pyqtSignal(str)
|
||||
finished = pyqtSignal()
|
||||
error = pyqtSignal(str)
|
||||
amplitude_changed = pyqtSignal(float)
|
||||
average_amplitude_changed = pyqtSignal(float)
|
||||
queue_size_changed = pyqtSignal(int)
|
||||
is_running = False
|
||||
SAMPLE_RATE = whisper_audio.SAMPLE_RATE
|
||||
|
||||
|
|
@ -62,10 +59,10 @@ class RecordingTranscriber(QObject):
|
|||
self.input_device_index = input_device_index
|
||||
self.sample_rate = sample_rate if sample_rate is not None else whisper_audio.SAMPLE_RATE
|
||||
self.model_path = model_path
|
||||
self.n_batch_samples = int(5 * self.sample_rate) # 5 seconds
|
||||
self.n_batch_samples = 5 * self.sample_rate # 5 seconds
|
||||
self.keep_sample_seconds = 0.15
|
||||
if self.transcriber_mode == RecordingTranscriberMode.APPEND_AND_CORRECT:
|
||||
self.n_batch_samples = int(transcription_options.transcription_step * self.sample_rate)
|
||||
self.n_batch_samples = 3 * self.sample_rate # 3 seconds
|
||||
self.keep_sample_seconds = 1.5
|
||||
# pause queueing if more than 3 batches behind
|
||||
self.max_queue_size = 3 * self.n_batch_samples
|
||||
|
|
@ -77,10 +74,8 @@ class RecordingTranscriber(QObject):
|
|||
key=Settings.Key.OPENAI_API_MODEL, default_value="whisper-1"
|
||||
)
|
||||
self.process = None
|
||||
self._stderr_lines: list[bytes] = []
|
||||
|
||||
def start(self):
|
||||
self.is_running = True
|
||||
model = None
|
||||
model_path = self.model_path
|
||||
keep_samples = int(self.keep_sample_seconds * self.sample_rate)
|
||||
|
|
@ -96,12 +91,6 @@ class RecordingTranscriber(QObject):
|
|||
model = whisper.load_model(model_path, device=device)
|
||||
elif self.transcription_options.model.model_type == ModelType.WHISPER_CPP:
|
||||
self.start_local_whisper_server()
|
||||
if self.openai_client is None:
|
||||
if not self.is_running:
|
||||
self.finished.emit()
|
||||
else:
|
||||
self.error.emit(_("Whisper server failed to start. Check logs for details."))
|
||||
return
|
||||
elif self.transcription_options.model.model_type == ModelType.FASTER_WHISPER:
|
||||
model_root_dir = user_cache_dir("Buzz")
|
||||
model_root_dir = os.path.join(model_root_dir, "models")
|
||||
|
|
@ -134,6 +123,14 @@ class RecordingTranscriber(QObject):
|
|||
cpu_threads=(os.cpu_count() or 8)//2,
|
||||
)
|
||||
|
||||
# This was commented out as it was causing issues. On the other hand some users are reporting errors without
|
||||
# this. It is possible issues were present in older model versions without some config files and now are fixed
|
||||
#
|
||||
# Fix for large-v3 https://github.com/guillaumekln/faster-whisper/issues/547#issuecomment-1797962599
|
||||
# if self.transcription_options.model.whisper_model_size in {WhisperModelSize.LARGEV3, WhisperModelSize.LARGEV3TURBO}:
|
||||
# model.feature_extractor.mel_filters = model.feature_extractor.get_mel_filters(
|
||||
# model.feature_extractor.sampling_rate, model.feature_extractor.n_fft, n_mels=128
|
||||
# )
|
||||
elif self.transcription_options.model.model_type == ModelType.OPEN_AI_WHISPER_API:
|
||||
custom_openai_base_url = self.settings.value(
|
||||
key=Settings.Key.CUSTOM_OPENAI_BASE_URL, default_value=""
|
||||
|
|
@ -158,6 +155,7 @@ class RecordingTranscriber(QObject):
|
|||
self.input_device_index,
|
||||
)
|
||||
|
||||
self.is_running = True
|
||||
try:
|
||||
with self.sounddevice.InputStream(
|
||||
samplerate=self.sample_rate,
|
||||
|
|
@ -169,19 +167,11 @@ class RecordingTranscriber(QObject):
|
|||
while self.is_running:
|
||||
if self.queue.size >= self.n_batch_samples:
|
||||
self.mutex.acquire()
|
||||
cut = self.find_silence_cut_point(
|
||||
self.queue[:self.n_batch_samples], self.sample_rate
|
||||
)
|
||||
samples = self.queue[:cut]
|
||||
if self.transcriber_mode == RecordingTranscriberMode.APPEND_AND_CORRECT:
|
||||
self.queue = self.queue[cut - keep_samples:]
|
||||
else:
|
||||
self.queue = self.queue[cut:]
|
||||
samples = self.queue[: self.n_batch_samples]
|
||||
self.queue = self.queue[self.n_batch_samples - keep_samples:]
|
||||
self.mutex.release()
|
||||
|
||||
amplitude = self.amplitude(samples)
|
||||
self.average_amplitude_changed.emit(amplitude)
|
||||
self.queue_size_changed.emit(self.queue.size)
|
||||
|
||||
logging.debug(
|
||||
"Processing next frame, sample size = %s, queue size = %s, amplitude = %s",
|
||||
|
|
@ -190,7 +180,7 @@ class RecordingTranscriber(QObject):
|
|||
amplitude,
|
||||
)
|
||||
|
||||
if amplitude < self.transcription_options.silence_threshold:
|
||||
if amplitude < 0.025:
|
||||
time.sleep(0.5)
|
||||
continue
|
||||
|
||||
|
|
@ -206,9 +196,8 @@ class RecordingTranscriber(QObject):
|
|||
language=self.transcription_options.language,
|
||||
task=self.transcription_options.task.value,
|
||||
initial_prompt=initial_prompt,
|
||||
temperature=DEFAULT_WHISPER_TEMPERATURE,
|
||||
no_speech_threshold=0.4,
|
||||
fp16=False,
|
||||
temperature=self.transcription_options.temperature,
|
||||
no_speech_threshold=0.4
|
||||
)
|
||||
elif (
|
||||
self.transcription_options.model.model_type
|
||||
|
|
@ -222,7 +211,7 @@ class RecordingTranscriber(QObject):
|
|||
else None,
|
||||
task=self.transcription_options.task.value,
|
||||
# Prevent crash on Windows https://github.com/SYSTRAN/faster-whisper/issues/71#issuecomment-1526263764
|
||||
temperature=0 if platform.system() == "Windows" else DEFAULT_WHISPER_TEMPERATURE,
|
||||
temperature=0 if platform.system() == "Windows" else self.transcription_options.temperature,
|
||||
initial_prompt=self.transcription_options.initial_prompt,
|
||||
word_timestamps=False,
|
||||
without_timestamps=True,
|
||||
|
|
@ -255,7 +244,8 @@ class RecordingTranscriber(QObject):
|
|||
)
|
||||
else: # OPEN_AI_WHISPER_API, also used for WHISPER_CPP
|
||||
if self.openai_client is None:
|
||||
self.error.emit(_("A connection error occurred"))
|
||||
self.transcription.emit(_("A connection error occurred"))
|
||||
self.stop_recording()
|
||||
return
|
||||
|
||||
# scale samples to 16-bit PCM
|
||||
|
|
@ -305,7 +295,7 @@ class RecordingTranscriber(QObject):
|
|||
next_text: str = result.get("text")
|
||||
|
||||
# Update initial prompt between successive recording chunks
|
||||
initial_prompt = next_text
|
||||
initial_prompt += next_text
|
||||
|
||||
logging.debug(
|
||||
"Received next result, length = %s, time taken = %s",
|
||||
|
|
@ -318,22 +308,17 @@ class RecordingTranscriber(QObject):
|
|||
|
||||
except PortAudioError as exc:
|
||||
self.error.emit(str(exc))
|
||||
logging.exception("PortAudio error during recording")
|
||||
return
|
||||
except Exception as exc:
|
||||
logging.exception("Unexpected error during recording")
|
||||
self.error.emit(str(exc))
|
||||
logging.exception("")
|
||||
return
|
||||
|
||||
# Cleanup before emitting finished to avoid destroying QThread
|
||||
# while this function is still on the call stack
|
||||
self.finished.emit()
|
||||
|
||||
# Cleanup
|
||||
if model:
|
||||
del model
|
||||
if torch.cuda.is_available():
|
||||
torch.cuda.empty_cache()
|
||||
|
||||
self.finished.emit()
|
||||
|
||||
@staticmethod
|
||||
def get_device_sample_rate(device_id: Optional[int]) -> int:
|
||||
"""Returns the sample rate to be used for recording. It uses the default sample rate
|
||||
|
|
@ -353,64 +338,19 @@ class RecordingTranscriber(QObject):
|
|||
def stream_callback(self, in_data: np.ndarray, frame_count, time_info, status):
|
||||
# Try to enqueue the next block. If the queue is already full, drop the block.
|
||||
chunk: np.ndarray = in_data.ravel()
|
||||
|
||||
amplitude = self.amplitude(chunk)
|
||||
self.amplitude_changed.emit(amplitude)
|
||||
|
||||
with self.mutex:
|
||||
if self.queue.size < self.max_queue_size:
|
||||
self.queue = np.append(self.queue, chunk)
|
||||
|
||||
@staticmethod
|
||||
def find_silence_cut_point(samples: np.ndarray, sample_rate: int,
|
||||
search_seconds: float = 1.5,
|
||||
window_seconds: float = 0.02,
|
||||
silence_ratio: float = 0.5) -> int:
|
||||
"""Return index of the last quiet point in the final search_seconds of samples.
|
||||
|
||||
Scans backwards through short windows; returns the midpoint of the rightmost
|
||||
window whose RMS is below silence_ratio * mean_rms of the search region.
|
||||
Falls back to len(samples) if no quiet window is found.
|
||||
"""
|
||||
window = int(window_seconds * sample_rate)
|
||||
search_start = max(0, len(samples) - int(search_seconds * sample_rate))
|
||||
region = samples[search_start:]
|
||||
n_windows = (len(region) - window) // window
|
||||
if n_windows < 1:
|
||||
return len(samples)
|
||||
|
||||
energies = np.array([
|
||||
np.sqrt(np.mean(region[i * window:(i + 1) * window] ** 2))
|
||||
for i in range(n_windows)
|
||||
])
|
||||
mean_energy = energies.mean()
|
||||
threshold = silence_ratio * mean_energy
|
||||
|
||||
for i in range(n_windows - 1, -1, -1):
|
||||
if energies[i] < threshold:
|
||||
cut = search_start + i * window + window // 2
|
||||
return cut
|
||||
|
||||
return len(samples)
|
||||
|
||||
@staticmethod
|
||||
def amplitude(arr: np.ndarray):
|
||||
return float(np.sqrt(np.mean(arr**2)))
|
||||
|
||||
def _drain_stderr(self):
|
||||
if self.process and self.process.stderr:
|
||||
for line in self.process.stderr:
|
||||
self._stderr_lines.append(line)
|
||||
return (abs(max(arr)) + abs(min(arr))) / 2
|
||||
|
||||
def stop_recording(self):
|
||||
self.is_running = False
|
||||
if self.process and self.process.poll() is None:
|
||||
self.process.terminate()
|
||||
try:
|
||||
self.process.wait(timeout=5)
|
||||
except subprocess.TimeoutExpired:
|
||||
self.process.kill()
|
||||
logging.warning("Whisper server process had to be killed after timeout")
|
||||
self.process.wait(5000)
|
||||
|
||||
def start_local_whisper_server(self):
|
||||
# Reduce verbose HTTP client logging from OpenAI/httpx
|
||||
|
|
@ -420,9 +360,6 @@ class RecordingTranscriber(QObject):
|
|||
|
||||
self.transcription.emit(_("Starting Whisper.cpp..."))
|
||||
|
||||
if platform.system() == "Darwin" and platform.machine() == "arm64":
|
||||
self.transcription.emit(_("First time use of a model may take up to several minutest to load."))
|
||||
|
||||
self.process = None
|
||||
|
||||
server_executable = "whisper-server.exe" if sys.platform == "win32" else "whisper-server"
|
||||
|
|
@ -439,6 +376,8 @@ class RecordingTranscriber(QObject):
|
|||
"--threads", str(os.getenv("BUZZ_WHISPERCPP_N_THREADS", (os.cpu_count() or 8) // 2)),
|
||||
"--model", self.model_path,
|
||||
"--no-timestamps",
|
||||
# on Windows context causes duplications of last message
|
||||
"--no-context",
|
||||
# Protections against hallucinated repetition. Seems to be problem on macOS
|
||||
# https://github.com/ggml-org/whisper.cpp/issues/1507
|
||||
"--max-context", "64",
|
||||
|
|
@ -472,27 +411,20 @@ class RecordingTranscriber(QObject):
|
|||
except Exception as e:
|
||||
error_msg = f"Failed to start whisper-server subprocess: {str(e)}"
|
||||
logging.error(error_msg)
|
||||
self.error.emit(error_msg)
|
||||
return
|
||||
|
||||
# Drain stderr in a background thread to prevent pipe buffer from filling
|
||||
# up and blocking the subprocess (especially on Windows with compiled exe).
|
||||
self._stderr_lines = []
|
||||
stderr_thread = threading.Thread(target=self._drain_stderr, daemon=True)
|
||||
stderr_thread.start()
|
||||
|
||||
# Wait for server to start and load model, checking periodically
|
||||
for i in range(100): # 10 seconds total, in 0.1s increments
|
||||
if not self.is_running or self.process.poll() is not None:
|
||||
break
|
||||
time.sleep(0.1)
|
||||
# Wait for server to start and load model
|
||||
time.sleep(10)
|
||||
|
||||
if self.process is not None and self.process.poll() is None:
|
||||
self.transcription.emit(_("Starting transcription..."))
|
||||
logging.debug(f"Whisper server started successfully.")
|
||||
logging.debug(f"Model: {self.model_path}")
|
||||
else:
|
||||
stderr_thread.join(timeout=2)
|
||||
stderr_output = b"".join(self._stderr_lines).decode(errors="replace")
|
||||
stderr_output = ""
|
||||
if self.process.stderr is not None:
|
||||
stderr_output = self.process.stderr.read().decode()
|
||||
logging.error(f"Whisper server failed to start. Error: {stderr_output}")
|
||||
|
||||
self.transcription.emit(_("Whisper server failed to start. Check logs for details."))
|
||||
|
|
@ -518,7 +450,4 @@ class RecordingTranscriber(QObject):
|
|||
def __del__(self):
|
||||
if self.process and self.process.poll() is None:
|
||||
self.process.terminate()
|
||||
try:
|
||||
self.process.wait(timeout=5)
|
||||
except subprocess.TimeoutExpired:
|
||||
self.process.kill()
|
||||
self.process.wait(5000)
|
||||
|
|
@ -153,9 +153,6 @@ class TranscriptionOptions:
|
|||
enable_llm_translation: bool = False
|
||||
llm_prompt: str = ""
|
||||
llm_model: str = ""
|
||||
silence_threshold: float = 0.0025
|
||||
line_separator: str = "\n\n"
|
||||
transcription_step: float = 3.5
|
||||
|
||||
|
||||
def humanize_language(language: str) -> str:
|
||||
|
|
@ -203,7 +200,6 @@ class FileTranscriptionTask:
|
|||
source: Source = Source.FILE_IMPORT
|
||||
file_path: Optional[str] = None
|
||||
original_file_path: Optional[str] = None # Original path before speech extraction
|
||||
delete_source_file: bool = False
|
||||
url: Optional[str] = None
|
||||
fraction_downloaded: float = 0.0
|
||||
|
||||
|
|
|
|||
|
|
@ -109,11 +109,6 @@ class WhisperCpp:
|
|||
"-f", file_to_process,
|
||||
]
|
||||
|
||||
# Add VAD if the model is available
|
||||
vad_model_path = os.path.join(os.path.dirname(whisper_cli_path), "ggml-silero-v6.2.0.bin")
|
||||
if os.path.exists(vad_model_path):
|
||||
cmd.extend(["--vad", "--vad-model", vad_model_path])
|
||||
|
||||
# Add translate flag if needed
|
||||
if task.transcription_options.task == Task.TRANSLATE:
|
||||
cmd.extend(["--translate"])
|
||||
|
|
@ -308,11 +303,6 @@ class WhisperCpp:
|
|||
if not token_text:
|
||||
continue
|
||||
|
||||
# Skip low probability tokens
|
||||
token_p = token_data.get("p", 1.0)
|
||||
if token_p < 0.01:
|
||||
continue
|
||||
|
||||
token_start = int(token_data.get("offsets", {}).get("from", 0))
|
||||
token_end = int(token_data.get("offsets", {}).get("to", 0))
|
||||
|
||||
|
|
|
|||
|
|
@ -25,10 +25,9 @@ from buzz.conn import pipe_stderr
|
|||
from buzz.model_loader import ModelType, WhisperModelSize, map_language_to_mms
|
||||
from buzz.transformers_whisper import TransformersTranscriber
|
||||
from buzz.transcriber.file_transcriber import FileTranscriber
|
||||
from buzz.transcriber.transcriber import FileTranscriptionTask, Segment, Task, DEFAULT_WHISPER_TEMPERATURE
|
||||
from buzz.transcriber.transcriber import FileTranscriptionTask, Segment, Task
|
||||
from buzz.transcriber.whisper_cpp import WhisperCpp
|
||||
|
||||
import av
|
||||
import faster_whisper
|
||||
import whisper
|
||||
import stable_whisper
|
||||
|
|
@ -37,22 +36,6 @@ from stable_whisper import WhisperResult
|
|||
PROGRESS_REGEX = re.compile(r"\d+(\.\d+)?%")
|
||||
|
||||
|
||||
def check_file_has_audio_stream(file_path: str) -> None:
|
||||
"""Check if a media file has at least one audio stream.
|
||||
|
||||
Raises:
|
||||
ValueError: If the file has no audio streams.
|
||||
"""
|
||||
try:
|
||||
with av.open(file_path) as container:
|
||||
if len(container.streams.audio) == 0:
|
||||
raise ValueError("No audio streams found")
|
||||
except av.error.InvalidDataError as e:
|
||||
raise ValueError(f"Invalid media file: {e}")
|
||||
except av.error.FileNotFoundError:
|
||||
raise ValueError("File not found")
|
||||
|
||||
|
||||
class WhisperFileTranscriber(FileTranscriber):
|
||||
"""WhisperFileTranscriber transcribes an audio file to text, writes the text to a file, and then opens the file
|
||||
using the default program for opening txt files."""
|
||||
|
|
@ -71,7 +54,6 @@ class WhisperFileTranscriber(FileTranscriber):
|
|||
self.stopped = False
|
||||
self.recv_pipe = None
|
||||
self.send_pipe = None
|
||||
self.error_message = None
|
||||
|
||||
def transcribe(self) -> List[Segment]:
|
||||
time_started = datetime.datetime.now()
|
||||
|
|
@ -137,7 +119,7 @@ class WhisperFileTranscriber(FileTranscriber):
|
|||
logging.debug("Whisper process was terminated (exit code: %s), treating as cancellation", self.current_process.exitcode)
|
||||
raise Exception("Transcription was canceled")
|
||||
else:
|
||||
raise Exception(self.error_message or "Unknown error")
|
||||
raise Exception("Unknown error")
|
||||
|
||||
return self.segments
|
||||
|
||||
|
|
@ -176,36 +158,27 @@ class WhisperFileTranscriber(FileTranscriber):
|
|||
subprocess.run = _patched_run
|
||||
subprocess.Popen = _PatchedPopen
|
||||
|
||||
try:
|
||||
# Check if the file has audio streams before processing
|
||||
check_file_has_audio_stream(task.file_path)
|
||||
with pipe_stderr(stderr_conn):
|
||||
if task.transcription_options.model.model_type == ModelType.WHISPER_CPP:
|
||||
segments = cls.transcribe_whisper_cpp(task)
|
||||
elif task.transcription_options.model.model_type == ModelType.HUGGING_FACE:
|
||||
sys.stderr.write("0%\n")
|
||||
segments = cls.transcribe_hugging_face(task)
|
||||
sys.stderr.write("100%\n")
|
||||
elif (
|
||||
task.transcription_options.model.model_type == ModelType.FASTER_WHISPER
|
||||
):
|
||||
segments = cls.transcribe_faster_whisper(task)
|
||||
elif task.transcription_options.model.model_type == ModelType.WHISPER:
|
||||
segments = cls.transcribe_openai_whisper(task)
|
||||
else:
|
||||
raise Exception(
|
||||
f"Invalid model type: {task.transcription_options.model.model_type}"
|
||||
)
|
||||
|
||||
with pipe_stderr(stderr_conn):
|
||||
if task.transcription_options.model.model_type == ModelType.WHISPER_CPP:
|
||||
segments = cls.transcribe_whisper_cpp(task)
|
||||
elif task.transcription_options.model.model_type == ModelType.HUGGING_FACE:
|
||||
sys.stderr.write("0%\n")
|
||||
segments = cls.transcribe_hugging_face(task)
|
||||
sys.stderr.write("100%\n")
|
||||
elif (
|
||||
task.transcription_options.model.model_type == ModelType.FASTER_WHISPER
|
||||
):
|
||||
segments = cls.transcribe_faster_whisper(task)
|
||||
elif task.transcription_options.model.model_type == ModelType.WHISPER:
|
||||
segments = cls.transcribe_openai_whisper(task)
|
||||
else:
|
||||
raise Exception(
|
||||
f"Invalid model type: {task.transcription_options.model.model_type}"
|
||||
)
|
||||
|
||||
segments_json = json.dumps(segments, ensure_ascii=True, default=vars)
|
||||
sys.stderr.write(f"segments = {segments_json}\n")
|
||||
sys.stderr.write(WhisperFileTranscriber.READ_LINE_THREAD_STOP_TOKEN + "\n")
|
||||
except Exception as e:
|
||||
# Send error message back to the parent process
|
||||
stderr_conn.send(f"error = {str(e)}\n")
|
||||
stderr_conn.send(WhisperFileTranscriber.READ_LINE_THREAD_STOP_TOKEN + "\n")
|
||||
raise
|
||||
segments_json = json.dumps(segments, ensure_ascii=True, default=vars)
|
||||
sys.stderr.write(f"segments = {segments_json}\n")
|
||||
sys.stderr.write(WhisperFileTranscriber.READ_LINE_THREAD_STOP_TOKEN + "\n")
|
||||
|
||||
@classmethod
|
||||
def transcribe_whisper_cpp(cls, task: FileTranscriptionTask) -> List[Segment]:
|
||||
|
|
@ -292,7 +265,7 @@ class WhisperFileTranscriber(FileTranscriber):
|
|||
language=task.transcription_options.language,
|
||||
task=task.transcription_options.task.value,
|
||||
# Prevent crash on Windows https://github.com/SYSTRAN/faster-whisper/issues/71#issuecomment-1526263764
|
||||
temperature = 0 if platform.system() == "Windows" else DEFAULT_WHISPER_TEMPERATURE,
|
||||
temperature = 0 if platform.system() == "Windows" else task.transcription_options.temperature,
|
||||
initial_prompt=task.transcription_options.initial_prompt,
|
||||
word_timestamps=task.transcription_options.word_level_timings,
|
||||
no_speech_threshold=0.4,
|
||||
|
|
@ -349,10 +322,9 @@ class WhisperFileTranscriber(FileTranscriber):
|
|||
audio=whisper_audio.load_audio(task.file_path),
|
||||
language=task.transcription_options.language,
|
||||
task=task.transcription_options.task.value,
|
||||
temperature=DEFAULT_WHISPER_TEMPERATURE,
|
||||
temperature=task.transcription_options.temperature,
|
||||
initial_prompt=task.transcription_options.initial_prompt,
|
||||
no_speech_threshold=0.4,
|
||||
fp16=False,
|
||||
)
|
||||
return [
|
||||
Segment(
|
||||
|
|
@ -372,7 +344,6 @@ class WhisperFileTranscriber(FileTranscriber):
|
|||
temperature=task.transcription_options.temperature,
|
||||
initial_prompt=task.transcription_options.initial_prompt,
|
||||
verbose=False,
|
||||
fp16=False,
|
||||
)
|
||||
segments = result.get("segments")
|
||||
return [
|
||||
|
|
@ -444,8 +415,6 @@ class WhisperFileTranscriber(FileTranscriber):
|
|||
for segment in segments_dict
|
||||
]
|
||||
self.segments = segments
|
||||
elif line.startswith("error = "):
|
||||
self.error_message = line[8:]
|
||||
else:
|
||||
try:
|
||||
match = PROGRESS_REGEX.search(line)
|
||||
|
|
|
|||
|
|
@ -1,22 +1,17 @@
|
|||
import os
|
||||
import re
|
||||
import logging
|
||||
import queue
|
||||
|
||||
from typing import Optional, List, Tuple
|
||||
from typing import Optional
|
||||
from openai import OpenAI, max_retries
|
||||
from PyQt6.QtCore import QObject, pyqtSignal
|
||||
|
||||
from buzz.locale import _
|
||||
from buzz.settings.settings import Settings
|
||||
from buzz.store.keyring_store import get_password, Key
|
||||
from buzz.transcriber.transcriber import TranscriptionOptions
|
||||
from buzz.widgets.transcriber.advanced_settings_dialog import AdvancedSettingsDialog
|
||||
|
||||
|
||||
BATCH_SIZE = 10
|
||||
|
||||
|
||||
class Translator(QObject):
|
||||
translation = pyqtSignal(str, int)
|
||||
finished = pyqtSignal()
|
||||
|
|
@ -56,94 +51,6 @@ class Translator(QObject):
|
|||
max_retries=0
|
||||
)
|
||||
|
||||
def _translate_single(self, transcript: str, transcript_id: int) -> Tuple[str, int]:
|
||||
"""Translate a single transcript via the API. Returns (translation, transcript_id)."""
|
||||
try:
|
||||
completion = self.openai_client.chat.completions.create(
|
||||
model=self.transcription_options.llm_model,
|
||||
messages=[
|
||||
{"role": "system", "content": self.transcription_options.llm_prompt},
|
||||
{"role": "user", "content": transcript}
|
||||
],
|
||||
timeout=60.0,
|
||||
)
|
||||
except Exception as e:
|
||||
completion = None
|
||||
logging.error(f"Translation error! Server response: {e}")
|
||||
|
||||
if completion and completion.choices and completion.choices[0].message:
|
||||
logging.debug(f"Received translation response: {completion}")
|
||||
return completion.choices[0].message.content, transcript_id
|
||||
else:
|
||||
logging.error(f"Translation error! Server response: {completion}")
|
||||
# Translation error
|
||||
return "", transcript_id
|
||||
|
||||
def _translate_batch(self, items: List[Tuple[str, int]]) -> List[Tuple[str, int]]:
|
||||
"""Translate multiple transcripts in a single API call.
|
||||
Returns list of (translation, transcript_id) in the same order as input."""
|
||||
numbered_parts = []
|
||||
for i, (transcript, _) in enumerate(items, 1):
|
||||
numbered_parts.append(f"[{i}] {transcript}")
|
||||
combined = "\n".join(numbered_parts)
|
||||
|
||||
batch_prompt = (
|
||||
f"{self.transcription_options.llm_prompt}\n\n"
|
||||
f"You will receive {len(items)} numbered texts. "
|
||||
f"Process each one separately according to the instruction above "
|
||||
f"and return them in the exact same numbered format, e.g.:\n"
|
||||
f"[1] processed text\n[2] processed text"
|
||||
)
|
||||
|
||||
try:
|
||||
completion = self.openai_client.chat.completions.create(
|
||||
model=self.transcription_options.llm_model,
|
||||
messages=[
|
||||
{"role": "system", "content": batch_prompt},
|
||||
{"role": "user", "content": combined}
|
||||
],
|
||||
timeout=60.0,
|
||||
)
|
||||
except Exception as e:
|
||||
completion = None
|
||||
logging.error(f"Batch translation error! Server response: {e}")
|
||||
|
||||
if not (completion and completion.choices and completion.choices[0].message):
|
||||
logging.error(f"Batch translation error! Server response: {completion}")
|
||||
# Translation error
|
||||
return [("", tid) for _, tid in items]
|
||||
|
||||
response_text = completion.choices[0].message.content
|
||||
logging.debug(f"Received batch translation response: {response_text}")
|
||||
|
||||
translations = self._parse_batch_response(response_text, len(items))
|
||||
|
||||
results = []
|
||||
for i, (_, transcript_id) in enumerate(items):
|
||||
if i < len(translations):
|
||||
results.append((translations[i], transcript_id))
|
||||
else:
|
||||
# Translation error
|
||||
results.append(("", transcript_id))
|
||||
return results
|
||||
|
||||
@staticmethod
|
||||
def _parse_batch_response(response: str, expected_count: int) -> List[str]:
|
||||
"""Parse a numbered batch response like '[1] text\\n[2] text' into a list of strings."""
|
||||
# Split on [N] markers — re.split with a group returns: [before, group1, after1, group2, after2, ...]
|
||||
parts = re.split(r'\[(\d+)\]\s*', response)
|
||||
|
||||
translations = {}
|
||||
for i in range(1, len(parts) - 1, 2):
|
||||
num = int(parts[i])
|
||||
text = parts[i + 1].strip()
|
||||
translations[num] = text
|
||||
|
||||
return [
|
||||
translations.get(i, "")
|
||||
for i in range(1, expected_count + 1)
|
||||
]
|
||||
|
||||
def start(self):
|
||||
logging.debug("Starting translation queue")
|
||||
|
||||
|
|
@ -155,32 +62,30 @@ class Translator(QObject):
|
|||
logging.debug("Translation queue received stop signal")
|
||||
break
|
||||
|
||||
# Collect a batch: start with the first item, then drain more
|
||||
batch = [item]
|
||||
stop_after_batch = False
|
||||
while len(batch) < BATCH_SIZE:
|
||||
try:
|
||||
next_item = self.queue.get_nowait()
|
||||
if next_item is None:
|
||||
stop_after_batch = True
|
||||
break
|
||||
batch.append(next_item)
|
||||
except queue.Empty:
|
||||
break
|
||||
transcript, transcript_id = item
|
||||
|
||||
if len(batch) == 1:
|
||||
transcript, transcript_id = batch[0]
|
||||
translation, tid = self._translate_single(transcript, transcript_id)
|
||||
self.translation.emit(translation, tid)
|
||||
try:
|
||||
completion = self.openai_client.chat.completions.create(
|
||||
model=self.transcription_options.llm_model,
|
||||
messages=[
|
||||
{"role": "system", "content": self.transcription_options.llm_prompt},
|
||||
{"role": "user", "content": transcript}
|
||||
],
|
||||
timeout=30.0,
|
||||
|
||||
)
|
||||
except Exception as e:
|
||||
completion = None
|
||||
logging.error(f"Translation error! Server response: {e}")
|
||||
|
||||
if completion and completion.choices and completion.choices[0].message:
|
||||
logging.debug(f"Received translation response: {completion}")
|
||||
next_translation = completion.choices[0].message.content
|
||||
else:
|
||||
logging.debug(f"Translating batch of {len(batch)} in single request")
|
||||
results = self._translate_batch(batch)
|
||||
for translation, tid in results:
|
||||
self.translation.emit(translation, tid)
|
||||
logging.error(f"Translation error! Server response: {completion}")
|
||||
next_translation = "Translation error, see logs!"
|
||||
|
||||
if stop_after_batch:
|
||||
logging.debug("Translation queue received stop signal")
|
||||
break
|
||||
self.translation.emit(next_translation, transcript_id)
|
||||
|
||||
logging.debug("Translation queue stopped")
|
||||
self.finished.emit()
|
||||
|
|
|
|||
|
|
@ -1,163 +0,0 @@
|
|||
import json
|
||||
import logging
|
||||
import platform
|
||||
from datetime import datetime
|
||||
from typing import Optional
|
||||
from dataclasses import dataclass
|
||||
|
||||
from PyQt6.QtCore import QObject, pyqtSignal, QUrl
|
||||
from PyQt6.QtNetwork import QNetworkAccessManager, QNetworkRequest, QNetworkReply
|
||||
from buzz.__version__ import VERSION
|
||||
from buzz.settings.settings import Settings
|
||||
|
||||
|
||||
@dataclass
|
||||
class UpdateInfo:
|
||||
version: str
|
||||
release_notes: str
|
||||
download_urls: list
|
||||
|
||||
class UpdateChecker(QObject):
|
||||
update_available = pyqtSignal(object)
|
||||
|
||||
VERSION_JSON_URL = "https://github.com/chidiwilliams/buzz/releases/latest/download/version_info.json"
|
||||
|
||||
CHECK_INTERVAL_DAYS = 7
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
settings: Settings,
|
||||
network_manager: Optional[QNetworkAccessManager] = None,
|
||||
parent: Optional[QObject] = None
|
||||
):
|
||||
super().__init__(parent)
|
||||
|
||||
self.settings = settings
|
||||
|
||||
if network_manager is None:
|
||||
network_manager = QNetworkAccessManager(self)
|
||||
self.network_manager = network_manager
|
||||
self.network_manager.finished.connect(self._on_reply_finished)
|
||||
|
||||
def should_check_for_updates(self) -> bool:
|
||||
"""Check if we are on Windows/macOS and if 7 days passed"""
|
||||
system = platform.system()
|
||||
if system not in ("Windows", "Darwin"):
|
||||
logging.debug("Skipping update check on linux")
|
||||
return False
|
||||
|
||||
last_check = self.settings.value(
|
||||
Settings.Key.LAST_UPDATE_CHECK,
|
||||
"",
|
||||
)
|
||||
|
||||
if last_check:
|
||||
try:
|
||||
last_check_date = datetime.fromisoformat(last_check)
|
||||
days_since_check = (datetime.now() - last_check_date).days
|
||||
if days_since_check < self.CHECK_INTERVAL_DAYS:
|
||||
logging.debug(
|
||||
f"Skipping update check, last checked {days_since_check} days ago"
|
||||
)
|
||||
return False
|
||||
except ValueError:
|
||||
#Invalid date format
|
||||
pass
|
||||
|
||||
return True
|
||||
|
||||
def check_for_updates(self) -> None:
|
||||
"""Start the network request"""
|
||||
if not self.should_check_for_updates():
|
||||
return
|
||||
|
||||
logging.info("Checking for updates...")
|
||||
|
||||
url = QUrl(self.VERSION_JSON_URL)
|
||||
request = QNetworkRequest(url)
|
||||
self.network_manager.get(request)
|
||||
|
||||
def _on_reply_finished(self, reply: QNetworkReply) -> None:
|
||||
"""Handles the network reply for version.json fetch"""
|
||||
self.settings.set_value(
|
||||
Settings.Key.LAST_UPDATE_CHECK,
|
||||
datetime.now().isoformat()
|
||||
)
|
||||
|
||||
if reply.error() != QNetworkReply.NetworkError.NoError:
|
||||
error_msg = f"Failed to check for updates: {reply.errorString()}"
|
||||
logging.error(error_msg)
|
||||
reply.deleteLater()
|
||||
return
|
||||
|
||||
try:
|
||||
data = json.loads(reply.readAll().data().decode("utf-8"))
|
||||
reply.deleteLater()
|
||||
|
||||
remote_version = data.get("version", "")
|
||||
release_notes = data.get("release_notes", "")
|
||||
download_urls = data.get("download_urls", {})
|
||||
|
||||
#Get the download url for current platform
|
||||
download_url = self._get_download_url(download_urls)
|
||||
|
||||
if self._is_newer_version(remote_version):
|
||||
logging.info(f"Update available: {remote_version}")
|
||||
|
||||
#Store the available version
|
||||
self.settings.set_value(
|
||||
Settings.Key.UPDATE_AVAILABLE_VERSION,
|
||||
remote_version
|
||||
)
|
||||
|
||||
update_info = UpdateInfo(
|
||||
version=remote_version,
|
||||
release_notes=release_notes,
|
||||
download_urls=download_url
|
||||
)
|
||||
self.update_available.emit(update_info)
|
||||
|
||||
else:
|
||||
logging.info("No update available")
|
||||
self.settings.set_value(
|
||||
Settings.Key.UPDATE_AVAILABLE_VERSION,
|
||||
""
|
||||
)
|
||||
|
||||
except (json.JSONDecodeError, KeyError) as e:
|
||||
error_msg = f"Failed to parse version info: {e}"
|
||||
logging.error(error_msg)
|
||||
|
||||
def _get_download_url(self, download_urls: dict) -> list:
|
||||
system = platform.system()
|
||||
machine = platform.machine().lower()
|
||||
|
||||
if system == "Windows":
|
||||
urls = download_urls.get("windows_x64", [])
|
||||
elif system == "Darwin":
|
||||
if machine in ("arm64", "aarch64"):
|
||||
urls = download_urls.get("macos_arm", [])
|
||||
else:
|
||||
urls = download_urls.get("macos_x86", [])
|
||||
else:
|
||||
urls = []
|
||||
|
||||
return urls if isinstance(urls, list) else [urls]
|
||||
|
||||
def _is_newer_version(self, remote_version: str) -> bool:
|
||||
"""Compare remote version with current version"""
|
||||
try:
|
||||
current_parts = [int(x) for x in VERSION.split(".")]
|
||||
remote_parts = [int(x) for x in remote_version.split(".")]
|
||||
|
||||
#pad with zeros if needed
|
||||
while len(current_parts) < len(remote_parts):
|
||||
current_parts.append(0)
|
||||
while len(remote_parts) < len(current_parts):
|
||||
remote_parts.append(0)
|
||||
|
||||
return remote_parts > current_parts
|
||||
|
||||
except ValueError:
|
||||
logging.error(f"Invalid version format: {VERSION} or {remote_version}")
|
||||
return False
|
||||
|
|
@ -34,7 +34,6 @@ class Application(QApplication):
|
|||
|
||||
if darkdetect.isDark():
|
||||
self.styleHints().setColorScheme(Qt.ColorScheme.Dark)
|
||||
self.setStyleSheet("QCheckBox::indicator:unchecked { border: 1px solid white; }")
|
||||
|
||||
if sys.platform.startswith("win"):
|
||||
self.setStyle(QStyleFactory.create("Fusion"))
|
||||
|
|
|
|||
|
|
@ -1,12 +1,10 @@
|
|||
from typing import Optional
|
||||
|
||||
from PyQt6 import QtGui
|
||||
from PyQt6.QtCore import Qt, QRect
|
||||
from PyQt6.QtCore import Qt
|
||||
from PyQt6.QtGui import QColor, QPainter
|
||||
from PyQt6.QtWidgets import QWidget
|
||||
|
||||
from buzz.locale import _
|
||||
|
||||
|
||||
class AudioMeterWidget(QWidget):
|
||||
current_amplitude: float
|
||||
|
|
@ -22,17 +20,13 @@ class AudioMeterWidget(QWidget):
|
|||
def __init__(self, parent: Optional[QWidget] = None):
|
||||
super().__init__(parent)
|
||||
self.setMinimumWidth(10)
|
||||
self.setFixedHeight(56)
|
||||
self.setFixedHeight(16)
|
||||
|
||||
self.BARS_HEIGHT = 28
|
||||
# Extra padding to fix layout
|
||||
self.PADDING_TOP = 14
|
||||
self.PADDING_TOP = 3
|
||||
|
||||
self.current_amplitude = 0.0
|
||||
|
||||
self.average_amplitude = 0.0
|
||||
self.queue_size = 0
|
||||
|
||||
self.MINIMUM_AMPLITUDE = 0.00005 # minimum amplitude to show the first bar
|
||||
self.AMPLITUDE_SCALE_FACTOR = 10 # scale the amplitudes such that 1/AMPLITUDE_SCALE_FACTOR will show all bars
|
||||
|
||||
|
|
@ -64,39 +58,18 @@ class AudioMeterWidget(QWidget):
|
|||
center_x - ((i + 1) * (self.BAR_MARGIN + self.BAR_WIDTH)),
|
||||
rect.top() + self.PADDING_TOP,
|
||||
self.BAR_WIDTH,
|
||||
self.BARS_HEIGHT - self.PADDING_TOP,
|
||||
rect.height() - self.PADDING_TOP,
|
||||
)
|
||||
# draw to right
|
||||
painter.drawRect(
|
||||
center_x + (self.BAR_MARGIN + (i * (self.BAR_MARGIN + self.BAR_WIDTH))),
|
||||
rect.top() + self.PADDING_TOP,
|
||||
self.BAR_WIDTH,
|
||||
self.BARS_HEIGHT - self.PADDING_TOP,
|
||||
rect.height() - self.PADDING_TOP,
|
||||
)
|
||||
|
||||
text_rect = QRect(rect.left(), self.BARS_HEIGHT, rect.width(), rect.height() - self.BARS_HEIGHT)
|
||||
painter.setPen(self.BAR_ACTIVE_COLOR)
|
||||
average_volume_label = _("Average volume")
|
||||
queue_label = _("Queue")
|
||||
painter.drawText(text_rect, Qt.AlignmentFlag.AlignCenter,
|
||||
f"{average_volume_label}: {self.average_amplitude:.4f} {queue_label}: {self.queue_size}")
|
||||
|
||||
def reset_amplitude(self):
|
||||
self.current_amplitude = 0.0
|
||||
self.average_amplitude = 0.0
|
||||
self.queue_size = 0
|
||||
self.repaint()
|
||||
|
||||
def update_amplitude(self, amplitude: float):
|
||||
self.current_amplitude = max(
|
||||
amplitude, self.current_amplitude * self.SMOOTHING_FACTOR
|
||||
)
|
||||
self.update()
|
||||
|
||||
def update_average_amplitude(self, amplitude: float):
|
||||
self.average_amplitude = amplitude
|
||||
self.update()
|
||||
|
||||
def update_queue_size(self, size: int):
|
||||
self.queue_size = size
|
||||
self.update()
|
||||
self.repaint()
|
||||
|
|
|
|||
|
|
@ -129,4 +129,3 @@ ADD_ICON_PATH = get_path("assets/add_FILL0_wght700_GRAD0_opsz48.svg")
|
|||
URL_ICON_PATH = get_path("assets/url.svg")
|
||||
TRASH_ICON_PATH = get_path("assets/delete_FILL0_wght700_GRAD0_opsz48.svg")
|
||||
CANCEL_ICON_PATH = get_path("assets/cancel_FILL0_wght700_GRAD0_opsz48.svg")
|
||||
UPDATE_ICON_PATH = get_path("assets/update_FILL0_wght700_GRAD0_opsz48.svg")
|
||||
|
|
@ -1,5 +1,6 @@
|
|||
import os
|
||||
import logging
|
||||
import keyring
|
||||
from typing import Tuple, List, Optional
|
||||
from uuid import UUID
|
||||
|
||||
|
|
@ -24,8 +25,6 @@ from buzz.db.service.transcription_service import TranscriptionService
|
|||
from buzz.file_transcriber_queue_worker import FileTranscriberQueueWorker
|
||||
from buzz.locale import _
|
||||
from buzz.settings.settings import APP_NAME, Settings
|
||||
from buzz.update_checker import UpdateChecker, UpdateInfo
|
||||
from buzz.widgets.update_dialog import UpdateDialog
|
||||
from buzz.settings.shortcuts import Shortcuts
|
||||
from buzz.store.keyring_store import set_password, Key
|
||||
from buzz.transcriber.transcriber import (
|
||||
|
|
@ -43,7 +42,6 @@ from buzz.widgets.preferences_dialog.models.preferences import Preferences
|
|||
from buzz.widgets.transcriber.file_transcriber_widget import FileTranscriberWidget
|
||||
from buzz.widgets.transcription_task_folder_watcher import (
|
||||
TranscriptionTaskFolderWatcher,
|
||||
SUPPORTED_EXTENSIONS,
|
||||
)
|
||||
from buzz.widgets.transcription_tasks_table_widget import (
|
||||
TranscriptionTasksTableWidget,
|
||||
|
|
@ -72,9 +70,6 @@ class MainWindow(QMainWindow):
|
|||
self.quit_on_complete = False
|
||||
self.transcription_service = transcription_service
|
||||
|
||||
#update checker
|
||||
self._update_info: Optional[UpdateInfo] = None
|
||||
|
||||
self.toolbar = MainWindowToolbar(shortcuts=self.shortcuts, parent=self)
|
||||
self.toolbar.new_transcription_action_triggered.connect(
|
||||
self.on_new_transcription_action_triggered
|
||||
|
|
@ -92,7 +87,6 @@ class MainWindow(QMainWindow):
|
|||
self.on_stop_transcription_action_triggered
|
||||
)
|
||||
self.addToolBar(self.toolbar)
|
||||
self.toolbar.update_action_triggered.connect(self.on_update_action_triggered)
|
||||
self.setUnifiedTitleAndToolBarOnMac(True)
|
||||
|
||||
self.preferences = self.load_preferences(settings=self.settings)
|
||||
|
|
@ -107,9 +101,6 @@ class MainWindow(QMainWindow):
|
|||
self.menu_bar.import_url_action_triggered.connect(
|
||||
self.on_new_url_transcription_action_triggered
|
||||
)
|
||||
self.menu_bar.import_folder_action_triggered.connect(
|
||||
self.on_import_folder_action_triggered
|
||||
)
|
||||
self.menu_bar.shortcuts_changed.connect(self.on_shortcuts_changed)
|
||||
self.menu_bar.openai_api_key_changed.connect(
|
||||
self.on_openai_access_token_changed
|
||||
|
|
@ -162,9 +153,6 @@ class MainWindow(QMainWindow):
|
|||
|
||||
self.transcription_viewer_widget = None
|
||||
|
||||
#Initialize and run update checker
|
||||
self._init_update_checker()
|
||||
|
||||
def on_preferences_changed(self, preferences: Preferences):
|
||||
self.preferences = preferences
|
||||
self.save_preferences(preferences)
|
||||
|
|
@ -268,20 +256,6 @@ class MainWindow(QMainWindow):
|
|||
if url is not None:
|
||||
self.open_file_transcriber_widget(url=url)
|
||||
|
||||
def on_import_folder_action_triggered(self):
|
||||
folder = QFileDialog.getExistingDirectory(self, _("Select folder"))
|
||||
if not folder:
|
||||
return
|
||||
file_paths = []
|
||||
for dirpath, _dirs, filenames in os.walk(folder):
|
||||
for filename in filenames:
|
||||
ext = os.path.splitext(filename)[1].lower()
|
||||
if ext in SUPPORTED_EXTENSIONS:
|
||||
file_paths.append(os.path.join(dirpath, filename))
|
||||
if not file_paths:
|
||||
return
|
||||
self.open_file_transcriber_widget(file_paths)
|
||||
|
||||
def open_file_transcriber_widget(
|
||||
self, file_paths: Optional[List[str]] = None, url: Optional[str] = None
|
||||
):
|
||||
|
|
@ -502,27 +476,3 @@ class MainWindow(QMainWindow):
|
|||
self.setBaseSize(1240, 600)
|
||||
self.resize(1240, 600)
|
||||
self.settings.end_group()
|
||||
|
||||
def _init_update_checker(self):
|
||||
"""Initializes and runs the update checker."""
|
||||
self.update_checker = UpdateChecker(settings=self.settings, parent=self)
|
||||
self.update_checker.update_available.connect(self._on_update_available)
|
||||
|
||||
# Check for updates on startup
|
||||
self.update_checker.check_for_updates()
|
||||
|
||||
def _on_update_available(self, update_info: UpdateInfo):
|
||||
"""Called when an update is available."""
|
||||
self._update_info = update_info
|
||||
self.toolbar.set_update_available(True)
|
||||
|
||||
def on_update_action_triggered(self):
|
||||
"""Called when user clicks the update action in toolbar."""
|
||||
if self._update_info is None:
|
||||
return
|
||||
|
||||
dialog = UpdateDialog(
|
||||
update_info=self._update_info,
|
||||
parent=self
|
||||
)
|
||||
dialog.exec()
|
||||
|
|
@ -16,7 +16,6 @@ from buzz.widgets.icon import (
|
|||
EXPAND_ICON_PATH,
|
||||
CANCEL_ICON_PATH,
|
||||
TRASH_ICON_PATH,
|
||||
UPDATE_ICON_PATH,
|
||||
)
|
||||
from buzz.widgets.recording_transcriber_widget import RecordingTranscriberWidget
|
||||
from buzz.widgets.toolbar import ToolBar
|
||||
|
|
@ -27,7 +26,6 @@ class MainWindowToolbar(ToolBar):
|
|||
new_url_transcription_action_triggered: pyqtSignal
|
||||
open_transcript_action_triggered: pyqtSignal
|
||||
clear_history_action_triggered: pyqtSignal
|
||||
update_action_triggered: pyqtSignal
|
||||
ICON_LIGHT_THEME_BACKGROUND = "#555"
|
||||
ICON_DARK_THEME_BACKGROUND = "#AAA"
|
||||
|
||||
|
|
@ -72,13 +70,6 @@ class MainWindowToolbar(ToolBar):
|
|||
self.clear_history_action = Action(
|
||||
Icon(TRASH_ICON_PATH, self), _("Clear History"), self
|
||||
)
|
||||
|
||||
self.update_action = Action(
|
||||
Icon(UPDATE_ICON_PATH, self), _("Update Available"), self
|
||||
)
|
||||
self.update_action_triggered = self.update_action.triggered
|
||||
self.update_action.setVisible(False)
|
||||
|
||||
self.clear_history_action_triggered = self.clear_history_action.triggered
|
||||
self.clear_history_action.setDisabled(True)
|
||||
|
||||
|
|
@ -95,10 +86,6 @@ class MainWindowToolbar(ToolBar):
|
|||
self.clear_history_action,
|
||||
]
|
||||
)
|
||||
|
||||
self.addSeparator()
|
||||
self.addAction(self.update_action)
|
||||
|
||||
self.setMovable(False)
|
||||
self.setToolButtonStyle(Qt.ToolButtonStyle.ToolButtonIconOnly)
|
||||
|
||||
|
|
@ -106,6 +93,12 @@ class MainWindowToolbar(ToolBar):
|
|||
self.record_action.setShortcut(
|
||||
QKeySequence.fromString(self.shortcuts.get(Shortcut.OPEN_RECORD_WINDOW))
|
||||
)
|
||||
self.new_transcription_action.setShortcut(
|
||||
QKeySequence.fromString(self.shortcuts.get(Shortcut.OPEN_IMPORT_WINDOW))
|
||||
)
|
||||
self.new_url_transcription_action.setShortcut(
|
||||
QKeySequence.fromString(self.shortcuts.get(Shortcut.OPEN_IMPORT_URL_WINDOW))
|
||||
)
|
||||
self.stop_transcription_action.setShortcut(
|
||||
QKeySequence.fromString(self.shortcuts.get(Shortcut.STOP_TRANSCRIPTION))
|
||||
)
|
||||
|
|
@ -127,7 +120,3 @@ class MainWindowToolbar(ToolBar):
|
|||
|
||||
def set_clear_history_action_enabled(self, enabled: bool):
|
||||
self.clear_history_action.setEnabled(enabled)
|
||||
|
||||
def set_update_available(self, available: bool):
|
||||
"""Shows or hides the update action in the toolbar."""
|
||||
self.update_action.setVisible(available)
|
||||
|
|
|
|||
|
|
@ -1,4 +1,3 @@
|
|||
import platform
|
||||
import webbrowser
|
||||
from typing import Optional
|
||||
|
||||
|
|
@ -20,7 +19,6 @@ from buzz.widgets.preferences_dialog.preferences_dialog import (
|
|||
class MenuBar(QMenuBar):
|
||||
import_action_triggered = pyqtSignal()
|
||||
import_url_action_triggered = pyqtSignal()
|
||||
import_folder_action_triggered = pyqtSignal()
|
||||
shortcuts_changed = pyqtSignal()
|
||||
openai_api_key_changed = pyqtSignal(str)
|
||||
preferences_changed = pyqtSignal(Preferences)
|
||||
|
|
@ -43,17 +41,12 @@ class MenuBar(QMenuBar):
|
|||
self.import_url_action = QAction(_("Import URL..."), self)
|
||||
self.import_url_action.triggered.connect(self.import_url_action_triggered)
|
||||
|
||||
self.import_folder_action = QAction(_("Import Folder..."), self)
|
||||
self.import_folder_action.triggered.connect(self.import_folder_action_triggered)
|
||||
|
||||
about_label = _("About")
|
||||
about_action = QAction(f'{about_label} {APP_NAME}', self)
|
||||
about_action.triggered.connect(self.on_about_action_triggered)
|
||||
about_action.setMenuRole(QAction.MenuRole.AboutRole)
|
||||
|
||||
self.preferences_action = QAction(_("Preferences..."), self)
|
||||
self.preferences_action.triggered.connect(self.on_preferences_action_triggered)
|
||||
self.preferences_action.setMenuRole(QAction.MenuRole.PreferencesRole)
|
||||
|
||||
help_label = _("Help")
|
||||
help_action = QAction(f'{help_label}', self)
|
||||
|
|
@ -64,10 +57,8 @@ class MenuBar(QMenuBar):
|
|||
file_menu = self.addMenu(_("File"))
|
||||
file_menu.addAction(self.import_action)
|
||||
file_menu.addAction(self.import_url_action)
|
||||
file_menu.addAction(self.import_folder_action)
|
||||
|
||||
help_menu_title = _("Help") + ("\u200B" if platform.system() == "Darwin" else "")
|
||||
help_menu = self.addMenu(help_menu_title)
|
||||
help_menu = self.addMenu(_("Help"))
|
||||
help_menu.addAction(about_action)
|
||||
help_menu.addAction(help_action)
|
||||
help_menu.addAction(self.preferences_action)
|
||||
|
|
|
|||
|
|
@ -44,16 +44,11 @@ class FolderWatchPreferencesWidget(QWidget):
|
|||
checkbox.setObjectName("EnableFolderWatchCheckbox")
|
||||
checkbox.stateChanged.connect(self.on_enable_changed)
|
||||
|
||||
delete_checkbox = QCheckBox(_("Delete processed files"))
|
||||
delete_checkbox.setChecked(config.delete_processed_files)
|
||||
delete_checkbox.setObjectName("DeleteProcessedFilesCheckbox")
|
||||
delete_checkbox.stateChanged.connect(self.on_delete_processed_files_changed)
|
||||
input_folder_browse_button = QPushButton(_("Browse"))
|
||||
input_folder_browse_button.clicked.connect(self.on_click_browse_input_folder)
|
||||
|
||||
self.input_folder_browse_button = QPushButton(_("Browse"))
|
||||
self.input_folder_browse_button.clicked.connect(self.on_click_browse_input_folder)
|
||||
|
||||
self.output_folder_browse_button = QPushButton(_("Browse"))
|
||||
self.output_folder_browse_button.clicked.connect(self.on_click_browse_output_folder)
|
||||
output_folder_browse_button = QPushButton(_("Browse"))
|
||||
output_folder_browse_button.clicked.connect(self.on_click_browse_output_folder)
|
||||
|
||||
input_folder_row = QHBoxLayout()
|
||||
self.input_folder_line_edit = LineEdit(config.input_directory, self)
|
||||
|
|
@ -62,7 +57,7 @@ class FolderWatchPreferencesWidget(QWidget):
|
|||
self.input_folder_line_edit.setObjectName("InputFolderLineEdit")
|
||||
|
||||
input_folder_row.addWidget(self.input_folder_line_edit)
|
||||
input_folder_row.addWidget(self.input_folder_browse_button)
|
||||
input_folder_row.addWidget(input_folder_browse_button)
|
||||
|
||||
output_folder_row = QHBoxLayout()
|
||||
self.output_folder_line_edit = LineEdit(config.output_directory, self)
|
||||
|
|
@ -71,7 +66,7 @@ class FolderWatchPreferencesWidget(QWidget):
|
|||
self.output_folder_line_edit.setObjectName("OutputFolderLineEdit")
|
||||
|
||||
output_folder_row.addWidget(self.output_folder_line_edit)
|
||||
output_folder_row.addWidget(self.output_folder_browse_button)
|
||||
output_folder_row.addWidget(output_folder_browse_button)
|
||||
|
||||
openai_access_token = get_password(Key.OPENAI_API_KEY)
|
||||
(
|
||||
|
|
@ -82,17 +77,15 @@ class FolderWatchPreferencesWidget(QWidget):
|
|||
file_paths=[],
|
||||
)
|
||||
|
||||
self.transcription_form_widget = FileTranscriptionFormWidget(
|
||||
transcription_form_widget = FileTranscriptionFormWidget(
|
||||
transcription_options=transcription_options,
|
||||
file_transcription_options=file_transcription_options,
|
||||
parent=self,
|
||||
)
|
||||
self.transcription_form_widget.transcription_options_changed.connect(
|
||||
transcription_form_widget.transcription_options_changed.connect(
|
||||
self.on_transcription_options_changed
|
||||
)
|
||||
|
||||
self.delete_checkbox = delete_checkbox
|
||||
|
||||
layout = QVBoxLayout(self)
|
||||
|
||||
folders_form_layout = QFormLayout()
|
||||
|
|
@ -100,17 +93,14 @@ class FolderWatchPreferencesWidget(QWidget):
|
|||
folders_form_layout.addRow("", checkbox)
|
||||
folders_form_layout.addRow(_("Input folder"), input_folder_row)
|
||||
folders_form_layout.addRow(_("Output folder"), output_folder_row)
|
||||
folders_form_layout.addRow("", delete_checkbox)
|
||||
folders_form_layout.addWidget(self.transcription_form_widget)
|
||||
folders_form_layout.addWidget(transcription_form_widget)
|
||||
|
||||
layout.addLayout(folders_form_layout)
|
||||
layout.addWidget(self.transcription_form_widget)
|
||||
layout.addWidget(transcription_form_widget)
|
||||
layout.addStretch()
|
||||
|
||||
self.setLayout(layout)
|
||||
|
||||
self._set_settings_enabled(config.enabled)
|
||||
|
||||
def on_click_browse_input_folder(self):
|
||||
folder = QFileDialog.getExistingDirectory(self, _("Select Input Folder"))
|
||||
self.input_folder_line_edit.setText(folder)
|
||||
|
|
@ -129,22 +119,8 @@ class FolderWatchPreferencesWidget(QWidget):
|
|||
self.config.output_directory = folder
|
||||
self.config_changed.emit(self.config)
|
||||
|
||||
def _set_settings_enabled(self, enabled: bool):
|
||||
self.input_folder_line_edit.setEnabled(enabled)
|
||||
self.input_folder_browse_button.setEnabled(enabled)
|
||||
self.output_folder_line_edit.setEnabled(enabled)
|
||||
self.output_folder_browse_button.setEnabled(enabled)
|
||||
self.delete_checkbox.setEnabled(enabled)
|
||||
self.transcription_form_widget.setEnabled(enabled)
|
||||
|
||||
def on_enable_changed(self, state: int):
|
||||
enabled = state == 2
|
||||
self.config.enabled = enabled
|
||||
self._set_settings_enabled(enabled)
|
||||
self.config_changed.emit(self.config)
|
||||
|
||||
def on_delete_processed_files_changed(self, state: int):
|
||||
self.config.delete_processed_files = state == 2
|
||||
self.config.enabled = state == 2
|
||||
self.config_changed.emit(self.config)
|
||||
|
||||
def on_transcription_options_changed(
|
||||
|
|
|
|||
|
|
@ -188,14 +188,6 @@ class GeneralPreferencesWidget(QWidget):
|
|||
|
||||
layout.addRow(_("Live recording mode"), self.recording_transcriber_mode)
|
||||
|
||||
export_note_label = QLabel(
|
||||
_("Note: Live recording export settings will be moved to the Advanced Settings in the Live Recording screen in a future version."),
|
||||
self,
|
||||
)
|
||||
export_note_label.setWordWrap(True)
|
||||
export_note_label.setSizePolicy(QSizePolicy.Policy.Expanding, QSizePolicy.Policy.Preferred)
|
||||
layout.addRow("", export_note_label)
|
||||
|
||||
self.reduce_gpu_memory_enabled = self.settings.value(
|
||||
key=Settings.Key.REDUCE_GPU_MEMORY, default_value=False
|
||||
)
|
||||
|
|
|
|||
|
|
@ -7,6 +7,7 @@ from buzz.model_loader import TranscriptionModel
|
|||
from buzz.transcriber.transcriber import (
|
||||
Task,
|
||||
OutputFormat,
|
||||
DEFAULT_WHISPER_TEMPERATURE,
|
||||
TranscriptionOptions,
|
||||
FileTranscriptionOptions,
|
||||
)
|
||||
|
|
@ -19,6 +20,7 @@ class FileTranscriptionPreferences:
|
|||
model: TranscriptionModel
|
||||
word_level_timings: bool
|
||||
extract_speech: bool
|
||||
temperature: Tuple[float, ...]
|
||||
initial_prompt: str
|
||||
enable_llm_translation: bool
|
||||
llm_prompt: str
|
||||
|
|
@ -31,6 +33,7 @@ class FileTranscriptionPreferences:
|
|||
settings.setValue("model", self.model)
|
||||
settings.setValue("word_level_timings", self.word_level_timings)
|
||||
settings.setValue("extract_speech", self.extract_speech)
|
||||
settings.setValue("temperature", self.temperature)
|
||||
settings.setValue("initial_prompt", self.initial_prompt)
|
||||
settings.setValue("enable_llm_translation", self.enable_llm_translation)
|
||||
settings.setValue("llm_model", self.llm_model)
|
||||
|
|
@ -56,6 +59,7 @@ class FileTranscriptionPreferences:
|
|||
extract_speech = False if extract_speech_value == "false" \
|
||||
else bool(extract_speech_value)
|
||||
|
||||
temperature = settings.value("temperature", DEFAULT_WHISPER_TEMPERATURE)
|
||||
initial_prompt = settings.value("initial_prompt", "")
|
||||
enable_llm_translation_value = settings.value("enable_llm_translation", False)
|
||||
enable_llm_translation = False if enable_llm_translation_value == "false" \
|
||||
|
|
@ -71,6 +75,7 @@ class FileTranscriptionPreferences:
|
|||
else TranscriptionModel.default(),
|
||||
word_level_timings=word_level_timings,
|
||||
extract_speech=extract_speech,
|
||||
temperature=temperature,
|
||||
initial_prompt=initial_prompt,
|
||||
enable_llm_translation=enable_llm_translation,
|
||||
llm_model=llm_model,
|
||||
|
|
@ -89,6 +94,7 @@ class FileTranscriptionPreferences:
|
|||
return FileTranscriptionPreferences(
|
||||
task=transcription_options.task,
|
||||
language=transcription_options.language,
|
||||
temperature=transcription_options.temperature,
|
||||
initial_prompt=transcription_options.initial_prompt,
|
||||
enable_llm_translation=transcription_options.enable_llm_translation,
|
||||
llm_model=transcription_options.llm_model,
|
||||
|
|
@ -109,6 +115,7 @@ class FileTranscriptionPreferences:
|
|||
TranscriptionOptions(
|
||||
task=self.task,
|
||||
language=self.language,
|
||||
temperature=self.temperature,
|
||||
initial_prompt=self.initial_prompt,
|
||||
enable_llm_translation=self.enable_llm_translation,
|
||||
llm_model=self.llm_model,
|
||||
|
|
|
|||
|
|
@ -13,13 +13,11 @@ class FolderWatchPreferences:
|
|||
input_directory: str
|
||||
output_directory: str
|
||||
file_transcription_options: FileTranscriptionPreferences
|
||||
delete_processed_files: bool = False
|
||||
|
||||
def save(self, settings: QSettings):
|
||||
settings.setValue("enabled", self.enabled)
|
||||
settings.setValue("input_folder", self.input_directory)
|
||||
settings.setValue("output_directory", self.output_directory)
|
||||
settings.setValue("delete_processed_files", self.delete_processed_files)
|
||||
settings.beginGroup("file_transcription_options")
|
||||
self.file_transcription_options.save(settings)
|
||||
settings.endGroup()
|
||||
|
|
@ -31,8 +29,6 @@ class FolderWatchPreferences:
|
|||
|
||||
input_folder = settings.value("input_folder", defaultValue="", type=str)
|
||||
output_folder = settings.value("output_directory", defaultValue="", type=str)
|
||||
delete_value = settings.value("delete_processed_files", False)
|
||||
delete_processed_files = False if delete_value == "false" else bool(delete_value)
|
||||
settings.beginGroup("file_transcription_options")
|
||||
file_transcription_options = FileTranscriptionPreferences.load(settings)
|
||||
settings.endGroup()
|
||||
|
|
@ -41,5 +37,4 @@ class FolderWatchPreferences:
|
|||
input_directory=input_folder,
|
||||
output_directory=output_folder,
|
||||
file_transcription_options=file_transcription_options,
|
||||
delete_processed_files=delete_processed_files,
|
||||
)
|
||||
|
|
|
|||
|
|
@ -7,7 +7,6 @@ from PyQt6.QtWidgets import QWidget, QFormLayout, QPushButton
|
|||
from buzz.locale import _
|
||||
from buzz.settings.shortcut import Shortcut
|
||||
from buzz.settings.shortcuts import Shortcuts
|
||||
from buzz.widgets.line_edit import LineEdit
|
||||
from buzz.widgets.sequence_edit import SequenceEdit
|
||||
|
||||
|
||||
|
|
@ -20,10 +19,8 @@ class ShortcutsEditorPreferencesWidget(QWidget):
|
|||
self.shortcuts = shortcuts
|
||||
|
||||
self.layout = QFormLayout(self)
|
||||
_field_height = LineEdit().sizeHint().height()
|
||||
for shortcut in Shortcut:
|
||||
sequence_edit = SequenceEdit(shortcuts.get(shortcut), self)
|
||||
sequence_edit.setFixedHeight(_field_height)
|
||||
sequence_edit.keySequenceChanged.connect(
|
||||
self.get_key_sequence_changed(shortcut)
|
||||
)
|
||||
|
|
|
|||
|
|
@ -1,9 +1,6 @@
|
|||
import csv
|
||||
import io
|
||||
import os
|
||||
import re
|
||||
import enum
|
||||
import time
|
||||
import requests
|
||||
import logging
|
||||
import datetime
|
||||
|
|
@ -11,7 +8,7 @@ import sounddevice
|
|||
from enum import auto
|
||||
from typing import Optional, Tuple, Any
|
||||
|
||||
from PyQt6.QtCore import QThread, Qt, QThreadPool, QTimer, pyqtSignal
|
||||
from PyQt6.QtCore import QThread, Qt, QThreadPool, QTimer
|
||||
from PyQt6.QtGui import QTextCursor, QCloseEvent, QColor
|
||||
from PyQt6.QtWidgets import (
|
||||
QWidget,
|
||||
|
|
@ -19,7 +16,6 @@ from PyQt6.QtWidgets import (
|
|||
QFormLayout,
|
||||
QHBoxLayout,
|
||||
QMessageBox,
|
||||
QApplication,
|
||||
QPushButton,
|
||||
QComboBox,
|
||||
QLabel,
|
||||
|
|
@ -42,6 +38,7 @@ from buzz.settings.recording_transcriber_mode import RecordingTranscriberMode
|
|||
from buzz.transcriber.recording_transcriber import RecordingTranscriber
|
||||
from buzz.transcriber.transcriber import (
|
||||
TranscriptionOptions,
|
||||
DEFAULT_WHISPER_TEMPERATURE,
|
||||
Task,
|
||||
)
|
||||
from buzz.translator import Translator
|
||||
|
|
@ -71,8 +68,6 @@ class RecordingTranscriberWidget(QWidget):
|
|||
recording_amplitude_listener: Optional[RecordingAmplitudeListener] = None
|
||||
device_sample_rate: Optional[int] = None
|
||||
|
||||
transcription_stopped = pyqtSignal()
|
||||
|
||||
class RecordingStatus(enum.Enum):
|
||||
STOPPED = auto()
|
||||
RECORDING = auto()
|
||||
|
|
@ -138,6 +133,10 @@ class RecordingTranscriberWidget(QWidget):
|
|||
initial_prompt=self.settings.value(
|
||||
key=Settings.Key.RECORDING_TRANSCRIBER_INITIAL_PROMPT, default_value=""
|
||||
),
|
||||
temperature=self.settings.value(
|
||||
key=Settings.Key.RECORDING_TRANSCRIBER_TEMPERATURE,
|
||||
default_value=DEFAULT_WHISPER_TEMPERATURE,
|
||||
),
|
||||
word_level_timings=False,
|
||||
enable_llm_translation=self.settings.value(
|
||||
key=Settings.Key.RECORDING_TRANSCRIBER_ENABLE_LLM_TRANSLATION,
|
||||
|
|
@ -149,18 +148,6 @@ class RecordingTranscriberWidget(QWidget):
|
|||
llm_prompt=self.settings.value(
|
||||
key=Settings.Key.RECORDING_TRANSCRIBER_LLM_PROMPT, default_value=""
|
||||
),
|
||||
silence_threshold=self.settings.value(
|
||||
key=Settings.Key.RECORDING_TRANSCRIBER_SILENCE_THRESHOLD,
|
||||
default_value=0.0025,
|
||||
),
|
||||
line_separator=self.settings.value(
|
||||
key=Settings.Key.RECORDING_TRANSCRIBER_LINE_SEPARATOR,
|
||||
default_value="\n\n",
|
||||
),
|
||||
transcription_step=self.settings.value(
|
||||
key=Settings.Key.RECORDING_TRANSCRIBER_TRANSCRIPTION_STEP,
|
||||
default_value=3.5,
|
||||
),
|
||||
)
|
||||
|
||||
self.audio_devices_combo_box = AudioDevicesComboBox(self)
|
||||
|
|
@ -181,27 +168,18 @@ class RecordingTranscriberWidget(QWidget):
|
|||
default_transcription_options=self.transcription_options,
|
||||
model_types=model_types,
|
||||
parent=self,
|
||||
show_recording_settings=True,
|
||||
)
|
||||
self.transcription_options_group_box.transcription_options_changed.connect(
|
||||
self.on_transcription_options_changed
|
||||
)
|
||||
self.transcription_options_group_box.advanced_settings_dialog.recording_mode_changed.connect(
|
||||
self.on_recording_mode_changed
|
||||
)
|
||||
self.transcription_options_group_box.advanced_settings_dialog.hide_unconfirmed_changed.connect(
|
||||
self.on_hide_unconfirmed_changed
|
||||
)
|
||||
|
||||
recording_options_layout = QFormLayout()
|
||||
self.microphone_label = QLabel(_("Microphone:"))
|
||||
recording_options_layout.addRow(self.microphone_label, self.audio_devices_combo_box)
|
||||
recording_options_layout.addRow(_("Microphone:"), self.audio_devices_combo_box)
|
||||
|
||||
self.audio_meter_widget = AudioMeterWidget(self)
|
||||
|
||||
record_button_layout = QHBoxLayout()
|
||||
record_button_layout.setContentsMargins(0, 4, 0, 8)
|
||||
record_button_layout.addWidget(self.audio_meter_widget, alignment=Qt.AlignmentFlag.AlignVCenter)
|
||||
record_button_layout.addWidget(self.audio_meter_widget)
|
||||
record_button_layout.addWidget(self.record_button)
|
||||
|
||||
layout.addWidget(self.transcription_options_group_box)
|
||||
|
|
@ -214,18 +192,12 @@ class RecordingTranscriberWidget(QWidget):
|
|||
self.translation_text_box.hide()
|
||||
|
||||
self.setLayout(layout)
|
||||
self.resize(700, 600)
|
||||
self.resize(450, 500)
|
||||
|
||||
self.reset_recording_amplitude_listener()
|
||||
|
||||
self._closing = False
|
||||
self.transcript_export_file = None
|
||||
self.translation_export_file = None
|
||||
self.export_file_type = "txt"
|
||||
self.export_max_entries = 0
|
||||
self.hide_unconfirmed = self.settings.value(
|
||||
Settings.Key.RECORDING_TRANSCRIBER_HIDE_UNCONFIRMED, True
|
||||
)
|
||||
self.export_enabled = self.settings.value(
|
||||
key=Settings.Key.RECORDING_TRANSCRIBER_EXPORT_ENABLED,
|
||||
default_value=False,
|
||||
|
|
@ -237,9 +209,6 @@ class RecordingTranscriberWidget(QWidget):
|
|||
self.presentation_options_bar = self.create_presentation_options_bar()
|
||||
layout.insertWidget(3, self.presentation_options_bar)
|
||||
self.presentation_options_bar.hide()
|
||||
self.copy_actions_bar = self.create_copy_actions_bar()
|
||||
layout.addWidget(self.copy_actions_bar) # Add at the bottom
|
||||
self.copy_actions_bar.hide()
|
||||
|
||||
def create_presentation_options_bar(self) -> QWidget:
|
||||
"""Crete the presentation options bar widget"""
|
||||
|
|
@ -261,7 +230,7 @@ class RecordingTranscriberWidget(QWidget):
|
|||
layout.addWidget(text_size_label)
|
||||
|
||||
self.text_size_spinbox = QSpinBox(bar)
|
||||
self.text_size_spinbox.setRange(10, 100) #10pt to 100pt
|
||||
self.text_size_spinbox.setRange(12, 72) #12pt to 72pt
|
||||
|
||||
saved_text_size = self.settings.value(
|
||||
Settings.Key.PRESENTATION_WINDOW_TEXT_SIZE,
|
||||
|
|
@ -317,56 +286,6 @@ class RecordingTranscriberWidget(QWidget):
|
|||
|
||||
return bar
|
||||
|
||||
def create_copy_actions_bar(self) -> QWidget:
|
||||
"""Create the copy actions bar widget"""
|
||||
bar = QWidget(self)
|
||||
layout = QHBoxLayout(bar)
|
||||
layout.setContentsMargins(5, 5, 5, 5)
|
||||
layout.setSpacing(10)
|
||||
|
||||
layout.addStretch() # Push button to the right
|
||||
|
||||
self.copy_transcript_button = QPushButton(_("Copy"), bar)
|
||||
self.copy_transcript_button.setToolTip(_("Copy transcription to clipboard"))
|
||||
self.copy_transcript_button.clicked.connect(self.on_copy_transcript_clicked)
|
||||
layout.addWidget(self.copy_transcript_button)
|
||||
|
||||
return bar
|
||||
|
||||
def on_copy_transcript_clicked(self):
|
||||
"""Handle copy transcript button click"""
|
||||
transcript_text = self.transcription_text_box.toPlainText().strip()
|
||||
|
||||
if not transcript_text:
|
||||
self.copy_transcript_button.setText(_("Nothing to copy!"))
|
||||
QTimer.singleShot(1500, lambda: self.copy_transcript_button.setText(_("Copy")))
|
||||
return
|
||||
|
||||
app = QApplication.instance()
|
||||
if app is None:
|
||||
logging.warning("QApplication instance not available; clipboard disabled")
|
||||
self.copy_transcript_button.setText(_("Copy failed"))
|
||||
QTimer.singleShot(1500, lambda: self.copy_transcript_button.setText(_("Copy")))
|
||||
return
|
||||
|
||||
clipboard = app.clipboard()
|
||||
if clipboard is None:
|
||||
logging.warning("Clipboard not available")
|
||||
self.copy_transcript_button.setText(_("Copy failed"))
|
||||
QTimer.singleShot(1500, lambda: self.copy_transcript_button.setText(_("Copy")))
|
||||
return
|
||||
|
||||
try:
|
||||
clipboard.setText(transcript_text)
|
||||
except Exception as e:
|
||||
logging.warning("Clipboard error: %s", e)
|
||||
self.copy_transcript_button.setText(_("Copy failed"))
|
||||
QTimer.singleShot(1500, lambda: self.copy_transcript_button.setText(_("Copy")))
|
||||
return
|
||||
|
||||
self.copy_transcript_button.setText(_("Copied!"))
|
||||
QTimer.singleShot(2000, lambda: self.copy_transcript_button.setText(_("Copy")))
|
||||
|
||||
def on_show_presentation_clicked(self):
|
||||
"""Handle click on 'Show in new window' button"""
|
||||
if self.presentation_window is None or not self.presentation_window.isVisible():
|
||||
|
|
@ -466,23 +385,7 @@ class RecordingTranscriberWidget(QWidget):
|
|||
|
||||
date_time_now = datetime.datetime.now().strftime("%d-%b-%Y %H-%M-%S")
|
||||
|
||||
custom_template = self.settings.value(
|
||||
key=Settings.Key.RECORDING_TRANSCRIBER_EXPORT_FILE_NAME,
|
||||
default_value="",
|
||||
)
|
||||
export_file_name_template = custom_template if custom_template else Settings().get_default_export_file_template()
|
||||
|
||||
self.export_file_type = self.settings.value(
|
||||
key=Settings.Key.RECORDING_TRANSCRIBER_EXPORT_FILE_TYPE,
|
||||
default_value="txt",
|
||||
)
|
||||
self.export_max_entries = self.settings.value(
|
||||
Settings.Key.RECORDING_TRANSCRIBER_EXPORT_MAX_ENTRIES, 0, int
|
||||
)
|
||||
self.hide_unconfirmed = self.settings.value(
|
||||
Settings.Key.RECORDING_TRANSCRIBER_HIDE_UNCONFIRMED, True
|
||||
)
|
||||
ext = ".csv" if self.export_file_type == "csv" else ".txt"
|
||||
export_file_name_template = Settings().get_default_export_file_template()
|
||||
|
||||
export_file_name = (
|
||||
export_file_name_template.replace("{{ input_file_name }}", "live recording")
|
||||
|
|
@ -491,27 +394,14 @@ class RecordingTranscriberWidget(QWidget):
|
|||
.replace("{{ model_type }}", self.transcription_options.model.model_type.value)
|
||||
.replace("{{ model_size }}", self.transcription_options.model.whisper_model_size or "")
|
||||
.replace("{{ date_time }}", date_time_now)
|
||||
+ ext
|
||||
+ ".txt"
|
||||
)
|
||||
|
||||
translated_ext = ".translated" + ext
|
||||
|
||||
if not os.path.isdir(export_folder):
|
||||
self.export_enabled = False
|
||||
|
||||
self.transcript_export_file = os.path.join(export_folder, export_file_name)
|
||||
self.translation_export_file = self.transcript_export_file.replace(ext, translated_ext)
|
||||
|
||||
# Clear export files at the start of each recording session
|
||||
for path in (self.transcript_export_file, self.translation_export_file):
|
||||
if os.path.isfile(path):
|
||||
self.write_to_export_file(path, "", mode="w")
|
||||
|
||||
def on_recording_mode_changed(self, mode: RecordingTranscriberMode):
|
||||
self.transcriber_mode = mode
|
||||
|
||||
def on_hide_unconfirmed_changed(self, value: bool):
|
||||
self.hide_unconfirmed = value
|
||||
self.translation_export_file = self.transcript_export_file.replace(".txt", ".translated.txt")
|
||||
|
||||
def on_transcription_options_changed(
|
||||
self, transcription_options: TranscriptionOptions
|
||||
|
|
@ -564,34 +454,16 @@ class RecordingTranscriberWidget(QWidget):
|
|||
self.recording_amplitude_listener.amplitude_changed.connect(
|
||||
self.on_recording_amplitude_changed, Qt.ConnectionType.QueuedConnection
|
||||
)
|
||||
self.recording_amplitude_listener.average_amplitude_changed.connect(
|
||||
self.audio_meter_widget.update_average_amplitude, Qt.ConnectionType.QueuedConnection
|
||||
)
|
||||
self.recording_amplitude_listener.start_recording()
|
||||
|
||||
def on_record_button_clicked(self):
|
||||
if self.current_status == self.RecordingStatus.STOPPED:
|
||||
# Stop amplitude listener and disconnect its signal before resetting
|
||||
# to prevent queued amplitude events from overriding the reset
|
||||
if self.recording_amplitude_listener is not None:
|
||||
self.recording_amplitude_listener.amplitude_changed.disconnect(
|
||||
self.on_recording_amplitude_changed
|
||||
)
|
||||
self.recording_amplitude_listener.average_amplitude_changed.disconnect(
|
||||
self.audio_meter_widget.update_average_amplitude
|
||||
)
|
||||
self.recording_amplitude_listener.stop_recording()
|
||||
self.recording_amplitude_listener = None
|
||||
self.audio_meter_widget.reset_amplitude()
|
||||
self.start_recording()
|
||||
self.current_status = self.RecordingStatus.RECORDING
|
||||
self.record_button.set_recording()
|
||||
self.transcription_options_group_box.setEnabled(False)
|
||||
self.audio_devices_combo_box.setEnabled(False)
|
||||
self.microphone_label.setEnabled(False)
|
||||
self.presentation_options_bar.show()
|
||||
self.copy_actions_bar.hide()
|
||||
|
||||
else: # RecordingStatus.RECORDING
|
||||
self.stop_recording()
|
||||
self.set_recording_status_stopped()
|
||||
|
|
@ -630,6 +502,7 @@ class RecordingTranscriberWidget(QWidget):
|
|||
|
||||
self.transcription_thread = QThread()
|
||||
|
||||
# TODO: make runnable
|
||||
self.transcriber = RecordingTranscriber(
|
||||
input_device_index=self.selected_device_id,
|
||||
sample_rate=self.device_sample_rate,
|
||||
|
|
@ -646,19 +519,6 @@ class RecordingTranscriberWidget(QWidget):
|
|||
)
|
||||
|
||||
self.transcriber.transcription.connect(self.on_next_transcription)
|
||||
self.transcriber.amplitude_changed.connect(
|
||||
self.on_recording_amplitude_changed, Qt.ConnectionType.QueuedConnection
|
||||
)
|
||||
self.transcriber.average_amplitude_changed.connect(
|
||||
self.audio_meter_widget.update_average_amplitude, Qt.ConnectionType.QueuedConnection
|
||||
)
|
||||
self.transcriber.queue_size_changed.connect(
|
||||
self.audio_meter_widget.update_queue_size, Qt.ConnectionType.QueuedConnection
|
||||
)
|
||||
|
||||
# Stop the separate amplitude listener to avoid two streams on the same device
|
||||
if self.recording_amplitude_listener is not None:
|
||||
self.recording_amplitude_listener.stop_recording()
|
||||
|
||||
self.transcriber.finished.connect(self.on_transcriber_finished)
|
||||
self.transcriber.finished.connect(self.transcription_thread.quit)
|
||||
|
|
@ -682,15 +542,9 @@ class RecordingTranscriberWidget(QWidget):
|
|||
self.translation_thread.finished.connect(
|
||||
self.translation_thread.deleteLater
|
||||
)
|
||||
self.translation_thread.finished.connect(
|
||||
lambda: setattr(self, "translation_thread", None)
|
||||
)
|
||||
|
||||
self.translator.finished.connect(self.translation_thread.quit)
|
||||
self.translator.finished.connect(self.translator.deleteLater)
|
||||
self.translator.finished.connect(
|
||||
lambda: setattr(self, "translator", None)
|
||||
)
|
||||
|
||||
self.translator.translation.connect(self.on_next_translation)
|
||||
|
||||
|
|
@ -719,16 +573,13 @@ class RecordingTranscriberWidget(QWidget):
|
|||
self.current_status = self.RecordingStatus.STOPPED
|
||||
self.transcription_options_group_box.setEnabled(True)
|
||||
self.audio_devices_combo_box.setEnabled(True)
|
||||
self.microphone_label.setEnabled(True)
|
||||
self.presentation_options_bar.hide()
|
||||
self.copy_actions_bar.show() #added this here
|
||||
|
||||
def on_download_model_error(self, error: str):
|
||||
self.reset_model_download()
|
||||
show_model_download_error_dialog(self, error)
|
||||
self.stop_recording()
|
||||
self.set_recording_status_stopped()
|
||||
self.reset_recording_amplitude_listener()
|
||||
self.record_button.setDisabled(False)
|
||||
|
||||
@staticmethod
|
||||
|
|
@ -744,102 +595,6 @@ class RecordingTranscriberWidget(QWidget):
|
|||
|
||||
return text
|
||||
|
||||
@staticmethod
|
||||
def write_to_export_file(file_path: str, content: str, mode: str = "a", retries: int = 5, delay: float = 0.2):
|
||||
"""Write to an export file with retry logic for Windows file locking."""
|
||||
for attempt in range(retries):
|
||||
try:
|
||||
with open(file_path, mode, encoding='utf-8') as f:
|
||||
f.write(content)
|
||||
return
|
||||
except PermissionError:
|
||||
if attempt < retries - 1:
|
||||
time.sleep(delay)
|
||||
else:
|
||||
logging.warning("Export write failed after %d retries: %s", retries, file_path)
|
||||
except OSError as e:
|
||||
logging.warning("Export write failed: %s", e)
|
||||
return
|
||||
|
||||
@staticmethod
|
||||
def write_csv_export(file_path: str, text: str, max_entries: int):
|
||||
"""Append a new column to a single-row CSV export file, applying max_entries limit."""
|
||||
existing_columns = []
|
||||
if os.path.isfile(file_path):
|
||||
try:
|
||||
with open(file_path, "r", encoding="utf-8-sig") as f:
|
||||
raw = f.read()
|
||||
if raw.strip():
|
||||
reader = csv.reader(io.StringIO(raw))
|
||||
for row in reader:
|
||||
existing_columns = row
|
||||
break
|
||||
except OSError:
|
||||
pass
|
||||
existing_columns.append(text)
|
||||
if max_entries > 0:
|
||||
existing_columns = existing_columns[-max_entries:]
|
||||
buf = io.StringIO()
|
||||
writer = csv.writer(buf)
|
||||
writer.writerow(existing_columns)
|
||||
for attempt in range(5):
|
||||
try:
|
||||
with open(file_path, "w", encoding='utf-8-sig') as f:
|
||||
f.write(buf.getvalue())
|
||||
return
|
||||
except PermissionError:
|
||||
if attempt < 4:
|
||||
time.sleep(0.2)
|
||||
else:
|
||||
logging.warning("CSV export write failed after retries: %s", file_path)
|
||||
except OSError as e:
|
||||
logging.warning("CSV export write failed: %s", e)
|
||||
return
|
||||
|
||||
@staticmethod
|
||||
def write_txt_export(file_path: str, text: str, mode: str, max_entries: int, line_separator: str):
|
||||
"""Write to a TXT export file, applying max_entries limit when needed."""
|
||||
if mode == "a":
|
||||
RecordingTranscriberWidget.write_to_export_file(file_path, text + line_separator)
|
||||
if max_entries > 0 and os.path.isfile(file_path):
|
||||
raw = RecordingTranscriberWidget.read_export_file(file_path)
|
||||
parts = [p for p in raw.split(line_separator) if p]
|
||||
if len(parts) > max_entries:
|
||||
parts = parts[-max_entries:]
|
||||
RecordingTranscriberWidget.write_to_export_file(
|
||||
file_path, line_separator.join(parts) + line_separator, mode="w"
|
||||
)
|
||||
elif mode == "prepend":
|
||||
existing_content = ""
|
||||
if os.path.isfile(file_path):
|
||||
existing_content = RecordingTranscriberWidget.read_export_file(file_path)
|
||||
new_content = text + line_separator + existing_content
|
||||
if max_entries > 0:
|
||||
parts = [p for p in new_content.split(line_separator) if p]
|
||||
if len(parts) > max_entries:
|
||||
parts = parts[:max_entries]
|
||||
new_content = line_separator.join(parts) + line_separator
|
||||
RecordingTranscriberWidget.write_to_export_file(file_path, new_content, mode="w")
|
||||
else:
|
||||
RecordingTranscriberWidget.write_to_export_file(file_path, text, mode=mode)
|
||||
|
||||
@staticmethod
|
||||
def read_export_file(file_path: str, retries: int = 5, delay: float = 0.2) -> str:
|
||||
"""Read an export file with retry logic for Windows file locking."""
|
||||
for attempt in range(retries):
|
||||
try:
|
||||
with open(file_path, "r", encoding='utf-8') as f:
|
||||
return f.read()
|
||||
except PermissionError:
|
||||
if attempt < retries - 1:
|
||||
time.sleep(delay)
|
||||
else:
|
||||
logging.warning("Export read failed after %d retries: %s", retries, file_path)
|
||||
except OSError as e:
|
||||
logging.warning("Export read failed: %s", e)
|
||||
return ""
|
||||
return ""
|
||||
|
||||
# Copilot magic implementation of a sliding window approach to find the longest common substring between two texts,
|
||||
# ignoring the initial differences.
|
||||
@staticmethod
|
||||
|
|
@ -876,36 +631,16 @@ class RecordingTranscriberWidget(QWidget):
|
|||
def process_transcription_merge(self, text: str, texts, text_box, export_file):
|
||||
texts.append(text)
|
||||
|
||||
# Possibly in future we want to tie this to some setting, to limit amount of data that needs
|
||||
# to be processed and exported. Value should not be less than ~10, so we have enough data to
|
||||
# work with.
|
||||
# if len(texts) > 20:
|
||||
# del texts[:len(texts) - 20]
|
||||
|
||||
# Remove possibly errorous parts from overlapping audio chunks
|
||||
last_common_length = None
|
||||
for i in range(len(texts) - 1):
|
||||
common_part = self.find_common_part(texts[i], texts[i + 1])
|
||||
if common_part:
|
||||
common_length = len(common_part)
|
||||
texts[i] = texts[i][:texts[i].rfind(common_part) + common_length]
|
||||
texts[i + 1] = texts[i + 1][texts[i + 1].find(common_part):]
|
||||
if i == len(texts) - 2:
|
||||
last_common_length = common_length
|
||||
elif i == len(texts) - 2:
|
||||
last_common_length = None
|
||||
|
||||
# When hiding unconfirmed: trim the last text to only the part confirmed by overlap
|
||||
# with the previous chunk. If no overlap found, drop the last text entirely.
|
||||
display_texts = list(texts)
|
||||
if self.hide_unconfirmed and len(display_texts) > 1:
|
||||
if last_common_length is not None:
|
||||
display_texts[-1] = display_texts[-1][:last_common_length]
|
||||
else:
|
||||
display_texts = display_texts[:-1]
|
||||
|
||||
merged_texts = ""
|
||||
for text in display_texts:
|
||||
for text in texts:
|
||||
merged_texts = self.merge_text_no_overlap(merged_texts, text)
|
||||
|
||||
merged_texts = NO_SPACE_BETWEEN_SENTENCES.sub(r'\1 \2', merged_texts)
|
||||
|
|
@ -914,12 +649,8 @@ class RecordingTranscriberWidget(QWidget):
|
|||
text_box.moveCursor(QTextCursor.MoveOperation.End)
|
||||
|
||||
if self.export_enabled and export_file:
|
||||
if self.export_file_type == "csv":
|
||||
# For APPEND_AND_CORRECT mode, rewrite the whole CSV with all merged text as a single entry
|
||||
self.write_to_export_file(export_file, "", mode="w")
|
||||
self.write_csv_export(export_file, merged_texts, 0)
|
||||
else:
|
||||
self.write_to_export_file(export_file, merged_texts, mode="w")
|
||||
with open(export_file, "w") as f:
|
||||
f.write(merged_texts)
|
||||
|
||||
def on_next_transcription(self, text: str):
|
||||
text = self.filter_text(text)
|
||||
|
|
@ -933,42 +664,28 @@ class RecordingTranscriberWidget(QWidget):
|
|||
if self.transcriber_mode == RecordingTranscriberMode.APPEND_BELOW:
|
||||
self.transcription_text_box.moveCursor(QTextCursor.MoveOperation.End)
|
||||
if len(self.transcription_text_box.toPlainText()) > 0:
|
||||
self.transcription_text_box.insertPlainText(self.transcription_options.line_separator)
|
||||
self.transcription_text_box.insertPlainText("\n\n")
|
||||
self.transcription_text_box.insertPlainText(text)
|
||||
self.transcription_text_box.moveCursor(QTextCursor.MoveOperation.End)
|
||||
|
||||
if self.export_enabled and self.transcript_export_file:
|
||||
if self.export_file_type == "csv":
|
||||
self.write_csv_export(self.transcript_export_file, text, self.export_max_entries)
|
||||
else:
|
||||
self.write_txt_export(self.transcript_export_file, text, "a", self.export_max_entries, self.transcription_options.line_separator)
|
||||
with open(self.transcript_export_file, "a") as f:
|
||||
f.write(text + "\n\n")
|
||||
|
||||
elif self.transcriber_mode == RecordingTranscriberMode.APPEND_ABOVE:
|
||||
self.transcription_text_box.moveCursor(QTextCursor.MoveOperation.Start)
|
||||
self.transcription_text_box.insertPlainText(text)
|
||||
self.transcription_text_box.insertPlainText(self.transcription_options.line_separator)
|
||||
self.transcription_text_box.insertPlainText("\n\n")
|
||||
self.transcription_text_box.moveCursor(QTextCursor.MoveOperation.Start)
|
||||
|
||||
if self.export_enabled and self.transcript_export_file:
|
||||
if self.export_file_type == "csv":
|
||||
# For APPEND_ABOVE, prepend in CSV means inserting at beginning of columns
|
||||
existing_columns = []
|
||||
if os.path.isfile(self.transcript_export_file):
|
||||
raw = self.read_export_file(self.transcript_export_file)
|
||||
if raw.strip():
|
||||
reader = csv.reader(io.StringIO(raw))
|
||||
for row in reader:
|
||||
existing_columns = row
|
||||
break
|
||||
new_columns = [text] + existing_columns
|
||||
if self.export_max_entries > 0:
|
||||
new_columns = new_columns[:self.export_max_entries]
|
||||
buf = io.StringIO()
|
||||
writer = csv.writer(buf)
|
||||
writer.writerow(new_columns)
|
||||
self.write_to_export_file(self.transcript_export_file, buf.getvalue(), mode="w")
|
||||
else:
|
||||
self.write_txt_export(self.transcript_export_file, text, "prepend", self.export_max_entries, self.transcription_options.line_separator)
|
||||
with open(self.transcript_export_file, "r") as f:
|
||||
existing_content = f.read()
|
||||
|
||||
new_content = text + "\n\n" + existing_content
|
||||
|
||||
with open(self.transcript_export_file, "w") as f:
|
||||
f.write(new_content)
|
||||
|
||||
elif self.transcriber_mode == RecordingTranscriberMode.APPEND_AND_CORRECT:
|
||||
self.process_transcription_merge(text, self.transcripts, self.transcription_text_box, self.transcript_export_file)
|
||||
|
|
@ -998,41 +715,28 @@ class RecordingTranscriberWidget(QWidget):
|
|||
if self.transcriber_mode == RecordingTranscriberMode.APPEND_BELOW:
|
||||
self.translation_text_box.moveCursor(QTextCursor.MoveOperation.End)
|
||||
if len(self.translation_text_box.toPlainText()) > 0:
|
||||
self.translation_text_box.insertPlainText(self.transcription_options.line_separator)
|
||||
self.translation_text_box.insertPlainText("\n\n")
|
||||
self.translation_text_box.insertPlainText(self.strip_newlines(text))
|
||||
self.translation_text_box.moveCursor(QTextCursor.MoveOperation.End)
|
||||
|
||||
if self.export_enabled and self.translation_export_file:
|
||||
if self.export_file_type == "csv":
|
||||
self.write_csv_export(self.translation_export_file, text, self.export_max_entries)
|
||||
else:
|
||||
self.write_txt_export(self.translation_export_file, text, "a", self.export_max_entries, self.transcription_options.line_separator)
|
||||
if self.export_enabled:
|
||||
with open(self.translation_export_file, "a") as f:
|
||||
f.write(text + "\n\n")
|
||||
|
||||
elif self.transcriber_mode == RecordingTranscriberMode.APPEND_ABOVE:
|
||||
self.translation_text_box.moveCursor(QTextCursor.MoveOperation.Start)
|
||||
self.translation_text_box.insertPlainText(self.strip_newlines(text))
|
||||
self.translation_text_box.insertPlainText(self.transcription_options.line_separator)
|
||||
self.translation_text_box.insertPlainText("\n\n")
|
||||
self.translation_text_box.moveCursor(QTextCursor.MoveOperation.Start)
|
||||
|
||||
if self.export_enabled and self.translation_export_file:
|
||||
if self.export_file_type == "csv":
|
||||
existing_columns = []
|
||||
if os.path.isfile(self.translation_export_file):
|
||||
raw = self.read_export_file(self.translation_export_file)
|
||||
if raw.strip():
|
||||
reader = csv.reader(io.StringIO(raw))
|
||||
for row in reader:
|
||||
existing_columns = row
|
||||
break
|
||||
new_columns = [text] + existing_columns
|
||||
if self.export_max_entries > 0:
|
||||
new_columns = new_columns[:self.export_max_entries]
|
||||
buf = io.StringIO()
|
||||
writer = csv.writer(buf)
|
||||
writer.writerow(new_columns)
|
||||
self.write_to_export_file(self.translation_export_file, buf.getvalue(), mode="w")
|
||||
else:
|
||||
self.write_txt_export(self.translation_export_file, text, "prepend", self.export_max_entries, self.transcription_options.line_separator)
|
||||
if self.export_enabled:
|
||||
with open(self.translation_export_file, "r") as f:
|
||||
existing_content = f.read()
|
||||
|
||||
new_content = text + "\n\n" + existing_content
|
||||
|
||||
with open(self.translation_export_file, "w") as f:
|
||||
f.write(new_content)
|
||||
|
||||
elif self.transcriber_mode == RecordingTranscriberMode.APPEND_AND_CORRECT:
|
||||
self.process_transcription_merge(text, self.translations, self.translation_text_box, self.translation_export_file)
|
||||
|
|
@ -1065,14 +769,10 @@ class RecordingTranscriberWidget(QWidget):
|
|||
|
||||
def on_transcriber_finished(self):
|
||||
self.reset_record_button()
|
||||
# Restart amplitude listener now that the transcription stream is closed
|
||||
self.reset_recording_amplitude_listener()
|
||||
self.transcription_stopped.emit()
|
||||
|
||||
def on_transcriber_error(self, error: str):
|
||||
self.reset_record_button()
|
||||
self.set_recording_status_stopped()
|
||||
self.reset_recording_amplitude_listener()
|
||||
QMessageBox.critical(
|
||||
self,
|
||||
"",
|
||||
|
|
@ -1089,7 +789,6 @@ class RecordingTranscriberWidget(QWidget):
|
|||
self.model_loader.cancel()
|
||||
self.reset_model_download()
|
||||
self.set_recording_status_stopped()
|
||||
self.reset_recording_amplitude_listener()
|
||||
self.record_button.setDisabled(False)
|
||||
|
||||
def reset_model_download(self):
|
||||
|
|
@ -1113,51 +812,17 @@ class RecordingTranscriberWidget(QWidget):
|
|||
self.audio_meter_widget.update_amplitude(amplitude)
|
||||
|
||||
def closeEvent(self, event: QCloseEvent) -> None:
|
||||
if self._closing:
|
||||
# Second call after deferred close — proceed normally
|
||||
self._do_close()
|
||||
super().closeEvent(event)
|
||||
return
|
||||
|
||||
if self.current_status == self.RecordingStatus.RECORDING:
|
||||
# Defer the close until the transcription thread finishes to avoid
|
||||
# blocking the GUI thread with a synchronous wait.
|
||||
event.ignore()
|
||||
self._closing = True
|
||||
|
||||
if self.model_loader is not None:
|
||||
self.model_loader.cancel()
|
||||
|
||||
self.stop_recording()
|
||||
|
||||
# Connect to QThread.finished — the transcriber C++ object may already
|
||||
# be scheduled for deletion via deleteLater() by this point.
|
||||
thread = self.transcription_thread
|
||||
if thread is not None:
|
||||
try:
|
||||
if thread.isRunning():
|
||||
thread.finished.connect(self._on_close_transcriber_finished)
|
||||
else:
|
||||
self._on_close_transcriber_finished()
|
||||
except RuntimeError:
|
||||
self._on_close_transcriber_finished()
|
||||
else:
|
||||
self._on_close_transcriber_finished()
|
||||
return
|
||||
|
||||
self._do_close()
|
||||
super().closeEvent(event)
|
||||
|
||||
def _on_close_transcriber_finished(self):
|
||||
self.transcription_thread = None
|
||||
self.close()
|
||||
|
||||
def _do_close(self):
|
||||
#Close presentation window if open
|
||||
if self.presentation_window:
|
||||
self.presentation_window.close()
|
||||
self.presentation_window = None
|
||||
|
||||
self.fullscreen_button.setEnabled(False)
|
||||
|
||||
if self.model_loader is not None:
|
||||
self.model_loader.cancel()
|
||||
|
||||
self.stop_recording()
|
||||
if self.recording_amplitude_listener is not None:
|
||||
self.recording_amplitude_listener.stop_recording()
|
||||
self.recording_amplitude_listener.deleteLater()
|
||||
|
|
@ -1167,8 +832,11 @@ class RecordingTranscriberWidget(QWidget):
|
|||
self.translator.stop()
|
||||
|
||||
if self.translation_thread is not None:
|
||||
# Just request quit — do not block the GUI thread waiting for it
|
||||
self.translation_thread.quit()
|
||||
# Only wait if thread is actually running
|
||||
if self.translation_thread.isRunning():
|
||||
if not self.translation_thread.wait(45_000):
|
||||
logging.warning("Translation thread did not finish within timeout")
|
||||
|
||||
self.settings.set_value(
|
||||
Settings.Key.RECORDING_TRANSCRIBER_LANGUAGE,
|
||||
|
|
@ -1177,6 +845,10 @@ class RecordingTranscriberWidget(QWidget):
|
|||
self.settings.set_value(
|
||||
Settings.Key.RECORDING_TRANSCRIBER_TASK, self.transcription_options.task
|
||||
)
|
||||
self.settings.set_value(
|
||||
Settings.Key.RECORDING_TRANSCRIBER_TEMPERATURE,
|
||||
self.transcription_options.temperature,
|
||||
)
|
||||
self.settings.set_value(
|
||||
Settings.Key.RECORDING_TRANSCRIBER_INITIAL_PROMPT,
|
||||
self.transcription_options.initial_prompt,
|
||||
|
|
@ -1196,15 +868,5 @@ class RecordingTranscriberWidget(QWidget):
|
|||
Settings.Key.RECORDING_TRANSCRIBER_LLM_PROMPT,
|
||||
self.transcription_options.llm_prompt,
|
||||
)
|
||||
self.settings.set_value(
|
||||
Settings.Key.RECORDING_TRANSCRIBER_SILENCE_THRESHOLD,
|
||||
self.transcription_options.silence_threshold,
|
||||
)
|
||||
self.settings.set_value(
|
||||
Settings.Key.RECORDING_TRANSCRIBER_LINE_SEPARATOR,
|
||||
self.transcription_options.line_separator,
|
||||
)
|
||||
self.settings.set_value(
|
||||
Settings.Key.RECORDING_TRANSCRIBER_TRANSCRIPTION_STEP,
|
||||
self.transcription_options.transcription_step,
|
||||
)
|
||||
|
||||
return super().closeEvent(event)
|
||||
|
|
|
|||
|
|
@ -7,34 +7,23 @@ from PyQt6.QtWidgets import (
|
|||
QPlainTextEdit,
|
||||
QFormLayout,
|
||||
QLabel,
|
||||
QDoubleSpinBox,
|
||||
QLineEdit,
|
||||
QComboBox,
|
||||
QHBoxLayout,
|
||||
QPushButton,
|
||||
QSpinBox,
|
||||
QFileDialog,
|
||||
)
|
||||
|
||||
from buzz.locale import _
|
||||
from buzz.model_loader import ModelType
|
||||
from buzz.transcriber.transcriber import TranscriptionOptions
|
||||
from buzz.settings.settings import Settings
|
||||
from buzz.settings.recording_transcriber_mode import RecordingTranscriberMode
|
||||
from buzz.widgets.line_edit import LineEdit
|
||||
from buzz.widgets.transcriber.initial_prompt_text_edit import InitialPromptTextEdit
|
||||
from buzz.widgets.transcriber.temperature_validator import TemperatureValidator
|
||||
|
||||
|
||||
class AdvancedSettingsDialog(QDialog):
|
||||
transcription_options: TranscriptionOptions
|
||||
transcription_options_changed = pyqtSignal(TranscriptionOptions)
|
||||
recording_mode_changed = pyqtSignal(RecordingTranscriberMode)
|
||||
hide_unconfirmed_changed = pyqtSignal(bool)
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
transcription_options: TranscriptionOptions,
|
||||
parent: QWidget | None = None,
|
||||
show_recording_settings: bool = False,
|
||||
self, transcription_options: TranscriptionOptions, parent: QWidget | None = None
|
||||
):
|
||||
super().__init__(parent)
|
||||
|
||||
|
|
@ -42,15 +31,29 @@ class AdvancedSettingsDialog(QDialog):
|
|||
self.settings = Settings()
|
||||
|
||||
self.setWindowTitle(_("Advanced Settings"))
|
||||
self.setMinimumWidth(800)
|
||||
|
||||
layout = QFormLayout(self)
|
||||
layout.setFieldGrowthPolicy(QFormLayout.FieldGrowthPolicy.ExpandingFieldsGrow)
|
||||
|
||||
transcription_settings_title= _("Speech recognition settings")
|
||||
transcription_settings_title_label = QLabel(f"<h4>{transcription_settings_title}</h4>", self)
|
||||
layout.addRow("", transcription_settings_title_label)
|
||||
|
||||
default_temperature_text = ", ".join(
|
||||
[str(temp) for temp in transcription_options.temperature]
|
||||
)
|
||||
self.temperature_line_edit = LineEdit(default_temperature_text, self)
|
||||
self.temperature_line_edit.setPlaceholderText(
|
||||
_('Comma-separated, e.g. "0.0, 0.2, 0.4, 0.6, 0.8, 1.0"')
|
||||
)
|
||||
self.temperature_line_edit.setMinimumWidth(250)
|
||||
self.temperature_line_edit.textChanged.connect(self.on_temperature_changed)
|
||||
self.temperature_line_edit.setValidator(TemperatureValidator(self))
|
||||
self.temperature_line_edit.setEnabled(
|
||||
transcription_options.model.model_type == ModelType.WHISPER
|
||||
)
|
||||
|
||||
layout.addRow(_("Temperature:"), self.temperature_line_edit)
|
||||
|
||||
self.initial_prompt_text_edit = InitialPromptTextEdit(
|
||||
transcription_options.initial_prompt,
|
||||
transcription_options.model.model_type,
|
||||
|
|
@ -71,160 +74,22 @@ class AdvancedSettingsDialog(QDialog):
|
|||
self.enable_llm_translation_checkbox.stateChanged.connect(self.on_enable_llm_translation_changed)
|
||||
layout.addRow("", self.enable_llm_translation_checkbox)
|
||||
|
||||
llm_model = self.transcription_options.llm_model or "gpt-4.1-mini"
|
||||
self.llm_model_line_edit = LineEdit(llm_model, self)
|
||||
self.llm_model_line_edit.textChanged.connect(self.on_llm_model_changed)
|
||||
self.llm_model_line_edit = LineEdit(self.transcription_options.llm_model, self)
|
||||
self.llm_model_line_edit.textChanged.connect(
|
||||
self.on_llm_model_changed
|
||||
)
|
||||
self.llm_model_line_edit.setMinimumWidth(170)
|
||||
self.llm_model_line_edit.setEnabled(self.transcription_options.enable_llm_translation)
|
||||
self.llm_model_label = QLabel(_("AI model:"))
|
||||
self.llm_model_label.setEnabled(self.transcription_options.enable_llm_translation)
|
||||
layout.addRow(self.llm_model_label, self.llm_model_line_edit)
|
||||
self.llm_model_line_edit.setPlaceholderText("gpt-4.1-mini")
|
||||
layout.addRow(_("AI model:"), self.llm_model_line_edit)
|
||||
|
||||
default_llm_prompt = self.transcription_options.llm_prompt or _(
|
||||
"Please translate each text sent to you from English to Spanish. Translation will be used in an automated system, please do not add any comments or notes, just the translation."
|
||||
)
|
||||
self.llm_prompt_text_edit = QPlainTextEdit(default_llm_prompt)
|
||||
self.llm_prompt_text_edit = QPlainTextEdit(self.transcription_options.llm_prompt)
|
||||
self.llm_prompt_text_edit.setEnabled(self.transcription_options.enable_llm_translation)
|
||||
self.llm_prompt_text_edit.setPlaceholderText(_("Enter instructions for AI on how to translate, for example 'Please translate each text sent to you from English to Spanish.'"))
|
||||
self.llm_prompt_text_edit.setMinimumWidth(170)
|
||||
self.llm_prompt_text_edit.setFixedHeight(80)
|
||||
self.llm_prompt_text_edit.setFixedHeight(115)
|
||||
self.llm_prompt_text_edit.textChanged.connect(self.on_llm_prompt_changed)
|
||||
self.llm_prompt_label = QLabel(_("Instructions for AI:"))
|
||||
self.llm_prompt_label.setEnabled(self.transcription_options.enable_llm_translation)
|
||||
layout.addRow(self.llm_prompt_label, self.llm_prompt_text_edit)
|
||||
|
||||
if show_recording_settings:
|
||||
recording_settings_title = _("Recording settings")
|
||||
recording_settings_title_label = QLabel(f"<h4>{recording_settings_title}</h4>", self)
|
||||
layout.addRow("", recording_settings_title_label)
|
||||
|
||||
self.silence_threshold_spin_box = QDoubleSpinBox(self)
|
||||
self.silence_threshold_spin_box.setRange(0.0, 1.0)
|
||||
self.silence_threshold_spin_box.setSingleStep(0.0005)
|
||||
self.silence_threshold_spin_box.setDecimals(4)
|
||||
self.silence_threshold_spin_box.setValue(transcription_options.silence_threshold)
|
||||
self.silence_threshold_spin_box.valueChanged.connect(self.on_silence_threshold_changed)
|
||||
self.silence_threshold_spin_box.setFixedWidth(90)
|
||||
layout.addRow(_("Silence threshold:"), self.silence_threshold_spin_box)
|
||||
|
||||
# Live recording mode
|
||||
self.recording_mode_combo = QComboBox(self)
|
||||
for mode in RecordingTranscriberMode:
|
||||
self.recording_mode_combo.addItem(mode.value)
|
||||
self.recording_mode_combo.setCurrentIndex(
|
||||
self.settings.value(Settings.Key.RECORDING_TRANSCRIBER_MODE, 0)
|
||||
)
|
||||
self.recording_mode_combo.currentIndexChanged.connect(self.on_recording_mode_changed)
|
||||
self.recording_mode_combo.setFixedWidth(250)
|
||||
layout.addRow(_("Live recording mode") + ":", self.recording_mode_combo)
|
||||
|
||||
self.line_separator_line_edit = QLineEdit(self)
|
||||
line_sep_display = repr(transcription_options.line_separator)[1:-1] or r"\n\n"
|
||||
self.line_separator_line_edit.setText(line_sep_display)
|
||||
self.line_separator_line_edit.textChanged.connect(self.on_line_separator_changed)
|
||||
self.line_separator_label = QLabel(_("Line separator:"))
|
||||
layout.addRow(self.line_separator_label, self.line_separator_line_edit)
|
||||
|
||||
self.transcription_step_spin_box = QDoubleSpinBox(self)
|
||||
self.transcription_step_spin_box.setRange(2.0, 5.0)
|
||||
self.transcription_step_spin_box.setSingleStep(0.1)
|
||||
self.transcription_step_spin_box.setDecimals(1)
|
||||
self.transcription_step_spin_box.setValue(transcription_options.transcription_step)
|
||||
self.transcription_step_spin_box.valueChanged.connect(self.on_transcription_step_changed)
|
||||
self.transcription_step_spin_box.setFixedWidth(80)
|
||||
self.transcription_step_label = QLabel(_("Transcription step:"))
|
||||
layout.addRow(self.transcription_step_label, self.transcription_step_spin_box)
|
||||
|
||||
hide_unconfirmed = self.settings.value(
|
||||
Settings.Key.RECORDING_TRANSCRIBER_HIDE_UNCONFIRMED, True
|
||||
)
|
||||
self.hide_unconfirmed_checkbox = QCheckBox(_("Hide unconfirmed"))
|
||||
self.hide_unconfirmed_checkbox.setChecked(hide_unconfirmed)
|
||||
self.hide_unconfirmed_checkbox.stateChanged.connect(self.on_hide_unconfirmed_changed)
|
||||
self.hide_unconfirmed_label = QLabel("")
|
||||
layout.addRow(self.hide_unconfirmed_label, self.hide_unconfirmed_checkbox)
|
||||
|
||||
self._update_recording_mode_visibility(
|
||||
RecordingTranscriberMode(self.recording_mode_combo.currentText())
|
||||
)
|
||||
|
||||
# Export enabled checkbox
|
||||
self._export_enabled = self.settings.value(
|
||||
Settings.Key.RECORDING_TRANSCRIBER_EXPORT_ENABLED, False
|
||||
)
|
||||
self.export_enabled_checkbox = QCheckBox(_("Enable live recording export"))
|
||||
self.export_enabled_checkbox.setChecked(self._export_enabled)
|
||||
self.export_enabled_checkbox.stateChanged.connect(self.on_export_enabled_changed)
|
||||
layout.addRow("", self.export_enabled_checkbox)
|
||||
|
||||
# Export folder
|
||||
export_folder = self.settings.value(
|
||||
Settings.Key.RECORDING_TRANSCRIBER_EXPORT_FOLDER, ""
|
||||
)
|
||||
self.export_folder_line_edit = LineEdit(export_folder, self)
|
||||
self.export_folder_line_edit.setEnabled(self._export_enabled)
|
||||
self.export_folder_line_edit.textChanged.connect(self.on_export_folder_changed)
|
||||
self.export_folder_browse_button = QPushButton(_("Browse"), self)
|
||||
self.export_folder_browse_button.setEnabled(self._export_enabled)
|
||||
self.export_folder_browse_button.clicked.connect(self.on_browse_export_folder)
|
||||
export_folder_row = QHBoxLayout()
|
||||
export_folder_row.addWidget(self.export_folder_line_edit)
|
||||
export_folder_row.addWidget(self.export_folder_browse_button)
|
||||
self.export_folder_label = QLabel(_("Export folder:"))
|
||||
self.export_folder_label.setEnabled(self._export_enabled)
|
||||
layout.addRow(self.export_folder_label, export_folder_row)
|
||||
|
||||
# Export file name template
|
||||
export_file_name = self.settings.value(
|
||||
Settings.Key.RECORDING_TRANSCRIBER_EXPORT_FILE_NAME, ""
|
||||
)
|
||||
self.export_file_name_line_edit = LineEdit(export_file_name, self)
|
||||
self.export_file_name_line_edit.setEnabled(self._export_enabled)
|
||||
self.export_file_name_line_edit.textChanged.connect(self.on_export_file_name_changed)
|
||||
self.export_file_name_label = QLabel(_("Export file name:"))
|
||||
self.export_file_name_label.setEnabled(self._export_enabled)
|
||||
layout.addRow(self.export_file_name_label, self.export_file_name_line_edit)
|
||||
|
||||
# Export file type
|
||||
self.export_file_type_combo = QComboBox(self)
|
||||
self.export_file_type_combo.addItem(_("Text file (.txt)"), "txt")
|
||||
self.export_file_type_combo.addItem(_("CSV (.csv)"), "csv")
|
||||
current_type = self.settings.value(
|
||||
Settings.Key.RECORDING_TRANSCRIBER_EXPORT_FILE_TYPE, "txt"
|
||||
)
|
||||
type_index = self.export_file_type_combo.findData(current_type)
|
||||
if type_index >= 0:
|
||||
self.export_file_type_combo.setCurrentIndex(type_index)
|
||||
self.export_file_type_combo.setEnabled(self._export_enabled)
|
||||
self.export_file_type_combo.currentIndexChanged.connect(self.on_export_file_type_changed)
|
||||
self.export_file_type_combo.setFixedWidth(200)
|
||||
self.export_file_type_label = QLabel(_("Export file type:"))
|
||||
self.export_file_type_label.setEnabled(self._export_enabled)
|
||||
layout.addRow(self.export_file_type_label, self.export_file_type_combo)
|
||||
|
||||
# Max entries
|
||||
max_entries = self.settings.value(
|
||||
Settings.Key.RECORDING_TRANSCRIBER_EXPORT_MAX_ENTRIES, 0, int
|
||||
)
|
||||
self.export_max_entries_spin = QSpinBox(self)
|
||||
self.export_max_entries_spin.setRange(0, 99)
|
||||
self.export_max_entries_spin.setValue(max_entries)
|
||||
self.export_max_entries_spin.setEnabled(self._export_enabled)
|
||||
self.export_max_entries_spin.valueChanged.connect(self.on_export_max_entries_changed)
|
||||
self.export_max_entries_spin.setFixedWidth(90)
|
||||
self.export_max_entries_label = QLabel(_("Limit export entries\n(0 = export all):"))
|
||||
self.export_max_entries_label.setEnabled(self._export_enabled)
|
||||
layout.addRow(self.export_max_entries_label, self.export_max_entries_spin)
|
||||
|
||||
_field_height = self.llm_model_line_edit.sizeHint().height()
|
||||
for widget in (
|
||||
self.line_separator_line_edit,
|
||||
self.silence_threshold_spin_box,
|
||||
self.recording_mode_combo,
|
||||
self.transcription_step_spin_box,
|
||||
self.export_file_type_combo,
|
||||
self.export_max_entries_spin,
|
||||
):
|
||||
widget.setFixedHeight(_field_height)
|
||||
layout.addRow(_("Instructions for AI:"), self.llm_prompt_text_edit)
|
||||
|
||||
button_box = QDialogButtonBox(
|
||||
QDialogButtonBox.StandardButton(QDialogButtonBox.StandardButton.Ok), self
|
||||
|
|
@ -235,6 +100,15 @@ class AdvancedSettingsDialog(QDialog):
|
|||
layout.addWidget(button_box)
|
||||
|
||||
self.setLayout(layout)
|
||||
self.resize(self.sizeHint())
|
||||
|
||||
def on_temperature_changed(self, text: str):
|
||||
try:
|
||||
temperatures = [float(temp.strip()) for temp in text.split(",")]
|
||||
self.transcription_options.temperature = tuple(temperatures)
|
||||
self.transcription_options_changed.emit(self.transcription_options)
|
||||
except ValueError:
|
||||
pass
|
||||
|
||||
def on_initial_prompt_changed(self):
|
||||
self.transcription_options.initial_prompt = (
|
||||
|
|
@ -246,11 +120,8 @@ class AdvancedSettingsDialog(QDialog):
|
|||
self.transcription_options.enable_llm_translation = state == 2
|
||||
self.transcription_options_changed.emit(self.transcription_options)
|
||||
|
||||
enabled = self.transcription_options.enable_llm_translation
|
||||
self.llm_model_label.setEnabled(enabled)
|
||||
self.llm_model_line_edit.setEnabled(enabled)
|
||||
self.llm_prompt_label.setEnabled(enabled)
|
||||
self.llm_prompt_text_edit.setEnabled(enabled)
|
||||
self.llm_model_line_edit.setEnabled(self.transcription_options.enable_llm_translation)
|
||||
self.llm_prompt_text_edit.setEnabled(self.transcription_options.enable_llm_translation)
|
||||
|
||||
def on_llm_model_changed(self, text: str):
|
||||
self.transcription_options.llm_model = text
|
||||
|
|
@ -261,72 +132,3 @@ class AdvancedSettingsDialog(QDialog):
|
|||
self.llm_prompt_text_edit.toPlainText()
|
||||
)
|
||||
self.transcription_options_changed.emit(self.transcription_options)
|
||||
|
||||
def on_silence_threshold_changed(self, value: float):
|
||||
self.transcription_options.silence_threshold = value
|
||||
self.transcription_options_changed.emit(self.transcription_options)
|
||||
|
||||
def on_line_separator_changed(self, text: str):
|
||||
try:
|
||||
self.transcription_options.line_separator = text.encode().decode("unicode_escape")
|
||||
except UnicodeDecodeError:
|
||||
return
|
||||
self.transcription_options_changed.emit(self.transcription_options)
|
||||
|
||||
def on_recording_mode_changed(self, index: int):
|
||||
self.settings.set_value(Settings.Key.RECORDING_TRANSCRIBER_MODE, index)
|
||||
mode = list(RecordingTranscriberMode)[index]
|
||||
self._update_recording_mode_visibility(mode)
|
||||
self.recording_mode_changed.emit(mode)
|
||||
|
||||
def _update_recording_mode_visibility(self, mode: RecordingTranscriberMode):
|
||||
is_append_and_correct = mode == RecordingTranscriberMode.APPEND_AND_CORRECT
|
||||
self.line_separator_label.setVisible(not is_append_and_correct)
|
||||
self.line_separator_line_edit.setVisible(not is_append_and_correct)
|
||||
self.transcription_step_label.setVisible(is_append_and_correct)
|
||||
self.transcription_step_spin_box.setVisible(is_append_and_correct)
|
||||
self.hide_unconfirmed_label.setVisible(is_append_and_correct)
|
||||
self.hide_unconfirmed_checkbox.setVisible(is_append_and_correct)
|
||||
|
||||
def on_transcription_step_changed(self, value: float):
|
||||
self.transcription_options.transcription_step = round(value, 1)
|
||||
self.transcription_options_changed.emit(self.transcription_options)
|
||||
|
||||
def on_hide_unconfirmed_changed(self, state: int):
|
||||
value = state == 2
|
||||
self.settings.set_value(Settings.Key.RECORDING_TRANSCRIBER_HIDE_UNCONFIRMED, value)
|
||||
self.hide_unconfirmed_changed.emit(value)
|
||||
|
||||
def on_export_enabled_changed(self, state: int):
|
||||
self._export_enabled = state == 2
|
||||
self.settings.set_value(Settings.Key.RECORDING_TRANSCRIBER_EXPORT_ENABLED, self._export_enabled)
|
||||
for widget in (
|
||||
self.export_folder_label,
|
||||
self.export_folder_line_edit,
|
||||
self.export_folder_browse_button,
|
||||
self.export_file_name_label,
|
||||
self.export_file_name_line_edit,
|
||||
self.export_file_type_label,
|
||||
self.export_file_type_combo,
|
||||
self.export_max_entries_label,
|
||||
self.export_max_entries_spin,
|
||||
):
|
||||
widget.setEnabled(self._export_enabled)
|
||||
|
||||
def on_export_folder_changed(self, text: str):
|
||||
self.settings.set_value(Settings.Key.RECORDING_TRANSCRIBER_EXPORT_FOLDER, text)
|
||||
|
||||
def on_browse_export_folder(self):
|
||||
folder = QFileDialog.getExistingDirectory(self, _("Select Export Folder"))
|
||||
if folder:
|
||||
self.export_folder_line_edit.setText(folder)
|
||||
|
||||
def on_export_file_name_changed(self, text: str):
|
||||
self.settings.set_value(Settings.Key.RECORDING_TRANSCRIBER_EXPORT_FILE_NAME, text)
|
||||
|
||||
def on_export_file_type_changed(self, index: int):
|
||||
file_type = self.export_file_type_combo.itemData(index)
|
||||
self.settings.set_value(Settings.Key.RECORDING_TRANSCRIBER_EXPORT_FILE_TYPE, file_type)
|
||||
|
||||
def on_export_max_entries_changed(self, value: int):
|
||||
self.settings.set_value(Settings.Key.RECORDING_TRANSCRIBER_EXPORT_MAX_ENTRIES, value)
|
||||
|
|
|
|||
|
|
@ -10,4 +10,4 @@ class InitialPromptTextEdit(QPlainTextEdit):
|
|||
self.setPlaceholderText(_("Enter prompt..."))
|
||||
self.setEnabled(model_type.supports_initial_prompt)
|
||||
self.setMinimumWidth(350)
|
||||
self.setFixedHeight(80)
|
||||
self.setFixedHeight(115)
|
||||
|
|
|
|||
21
buzz/widgets/transcriber/temperature_validator.py
Normal file
21
buzz/widgets/transcriber/temperature_validator.py
Normal file
|
|
@ -0,0 +1,21 @@
|
|||
from typing import Optional, Tuple
|
||||
|
||||
from PyQt6.QtCore import QObject
|
||||
from PyQt6.QtGui import QValidator
|
||||
|
||||
|
||||
class TemperatureValidator(QValidator):
|
||||
def __init__(self, parent: Optional[QObject] = ...) -> None:
|
||||
super().__init__(parent)
|
||||
|
||||
def validate(
|
||||
self, text: str, cursor_position: int
|
||||
) -> Tuple["QValidator.State", str, int]:
|
||||
try:
|
||||
temp_strings = [temp.strip() for temp in text.split(",")]
|
||||
if temp_strings[-1] == "":
|
||||
return QValidator.State.Intermediate, text, cursor_position
|
||||
_ = [float(temp) for temp in temp_strings]
|
||||
return QValidator.State.Acceptable, text, cursor_position
|
||||
except ValueError:
|
||||
return QValidator.State.Invalid, text, cursor_position
|
||||
|
|
@ -33,7 +33,6 @@ class TranscriptionOptionsGroupBox(QGroupBox):
|
|||
default_transcription_options: TranscriptionOptions = TranscriptionOptions(),
|
||||
model_types: Optional[List[ModelType]] = None,
|
||||
parent: Optional[QWidget] = None,
|
||||
show_recording_settings: bool = False,
|
||||
):
|
||||
super().__init__(title="", parent=parent)
|
||||
self.settings = Settings()
|
||||
|
|
@ -50,9 +49,7 @@ class TranscriptionOptionsGroupBox(QGroupBox):
|
|||
self.model_type_combo_box.changed.connect(self.on_model_type_changed)
|
||||
|
||||
self.advanced_settings_dialog = AdvancedSettingsDialog(
|
||||
transcription_options=self.transcription_options,
|
||||
parent=self,
|
||||
show_recording_settings=show_recording_settings,
|
||||
transcription_options=self.transcription_options, parent=self
|
||||
)
|
||||
self.advanced_settings_dialog.transcription_options_changed.connect(
|
||||
self.on_transcription_options_changed
|
||||
|
|
|
|||
|
|
@ -111,7 +111,6 @@ class TranscriptionTaskFolderWatcher(QFileSystemWatcher):
|
|||
model_path=model_path,
|
||||
output_directory=output_directory,
|
||||
source=FileTranscriptionTask.Source.FOLDER_WATCH,
|
||||
delete_source_file=self.preferences.delete_processed_files,
|
||||
)
|
||||
self.task_found.emit(task)
|
||||
self.paths_emitted.add(file_path)
|
||||
|
|
|
|||
|
|
@ -45,6 +45,23 @@ from buzz.settings.settings import Settings
|
|||
from buzz.widgets.line_edit import LineEdit
|
||||
from buzz.transcriber.transcriber import Segment
|
||||
|
||||
from ctc_forced_aligner.ctc_forced_aligner import (
|
||||
generate_emissions,
|
||||
get_alignments,
|
||||
get_spans,
|
||||
load_alignment_model,
|
||||
postprocess_results,
|
||||
preprocess_text,
|
||||
)
|
||||
from whisper_diarization.helpers import (
|
||||
get_realigned_ws_mapping_with_punctuation,
|
||||
get_sentences_speaker_mapping,
|
||||
get_words_speaker_mapping,
|
||||
langs_to_iso,
|
||||
punct_model_langs,
|
||||
)
|
||||
from deepmultilingualpunctuation.deepmultilingualpunctuation import PunctuationModel
|
||||
from whisper_diarization.diarization import MSDDDiarizer
|
||||
|
||||
|
||||
def process_in_batches(
|
||||
|
|
@ -150,32 +167,6 @@ class IdentificationWorker(QObject):
|
|||
}
|
||||
|
||||
def run(self):
|
||||
try:
|
||||
from ctc_forced_aligner.ctc_forced_aligner import (
|
||||
generate_emissions,
|
||||
get_alignments,
|
||||
get_spans,
|
||||
load_alignment_model,
|
||||
postprocess_results,
|
||||
preprocess_text,
|
||||
)
|
||||
from whisper_diarization.helpers import (
|
||||
get_realigned_ws_mapping_with_punctuation,
|
||||
get_sentences_speaker_mapping,
|
||||
get_words_speaker_mapping,
|
||||
langs_to_iso,
|
||||
punct_model_langs,
|
||||
)
|
||||
from deepmultilingualpunctuation.deepmultilingualpunctuation import PunctuationModel
|
||||
from whisper_diarization.diarization import MSDDDiarizer
|
||||
except ImportError as e:
|
||||
logging.exception("Failed to import speaker identification libraries: %s", e)
|
||||
self.error.emit(
|
||||
_("Speaker identification is not available: failed to load required libraries.")
|
||||
+ f"\n\n{e}"
|
||||
)
|
||||
return
|
||||
|
||||
diarizer_model = None
|
||||
alignment_model = None
|
||||
|
||||
|
|
@ -259,15 +250,13 @@ class IdentificationWorker(QObject):
|
|||
return
|
||||
|
||||
self.progress_update.emit(_("4/8 Processing audio"))
|
||||
logging.debug("Speaker identification worker: Generating emissions")
|
||||
emissions, stride = generate_emissions(
|
||||
alignment_model,
|
||||
torch.from_numpy(audio_waveform)
|
||||
.to(alignment_model.dtype)
|
||||
.to(alignment_model.device),
|
||||
batch_size=1 if device == "cpu" else 8,
|
||||
batch_size=8,
|
||||
)
|
||||
logging.debug("Speaker identification worker: Emissions generated")
|
||||
|
||||
# Clean up alignment model
|
||||
del alignment_model
|
||||
|
|
@ -313,14 +302,10 @@ class IdentificationWorker(QObject):
|
|||
|
||||
logging.debug("Speaker identification worker: Creating diarizer model")
|
||||
diarizer_model = MSDDDiarizer(device)
|
||||
logging.debug("Speaker identification worker: Running diarization (this may take a while on CPU)")
|
||||
logging.debug("Speaker identification worker: Running diarization")
|
||||
speaker_ts = diarizer_model.diarize(torch.from_numpy(audio_waveform).unsqueeze(0))
|
||||
logging.debug("Speaker identification worker: Diarization complete")
|
||||
|
||||
if self._is_cancelled:
|
||||
logging.debug("Speaker identification worker: Cancelled after diarization")
|
||||
return
|
||||
|
||||
# Clean up diarizer model immediately after use
|
||||
del diarizer_model
|
||||
diarizer_model = None
|
||||
|
|
@ -459,11 +444,6 @@ class SpeakerIdentificationWidget(QWidget):
|
|||
self.step_1_button.setMinimumWidth(200)
|
||||
self.step_1_button.clicked.connect(self.on_identify_button_clicked)
|
||||
|
||||
self.cancel_button = QPushButton(_("Cancel"))
|
||||
self.cancel_button.setMinimumWidth(200)
|
||||
self.cancel_button.setVisible(False)
|
||||
self.cancel_button.clicked.connect(self.on_cancel_button_clicked)
|
||||
|
||||
# Progress container with label and bar
|
||||
progress_container = QVBoxLayout()
|
||||
|
||||
|
|
@ -484,10 +464,7 @@ class SpeakerIdentificationWidget(QWidget):
|
|||
|
||||
self.step_1_row.addLayout(progress_container)
|
||||
|
||||
button_container = QVBoxLayout()
|
||||
button_container.addWidget(self.step_1_button)
|
||||
button_container.addWidget(self.cancel_button)
|
||||
self.step_1_row.addLayout(button_container)
|
||||
self.step_1_row.addWidget(self.step_1_button, alignment=Qt.AlignmentFlag.AlignTop)
|
||||
|
||||
step_1_layout.addLayout(self.step_1_row)
|
||||
|
||||
|
|
@ -552,8 +529,6 @@ class SpeakerIdentificationWidget(QWidget):
|
|||
|
||||
def on_identify_button_clicked(self):
|
||||
self.step_1_button.setEnabled(False)
|
||||
self.step_1_button.setVisible(False)
|
||||
self.cancel_button.setVisible(True)
|
||||
|
||||
# Clean up any existing thread before starting a new one
|
||||
self._cleanup_thread()
|
||||
|
|
@ -573,36 +548,18 @@ class SpeakerIdentificationWidget(QWidget):
|
|||
|
||||
self.thread.start()
|
||||
|
||||
def on_cancel_button_clicked(self):
|
||||
"""Handle cancel button click."""
|
||||
logging.debug("Speaker identification: Cancel requested by user")
|
||||
self.cancel_button.setEnabled(False)
|
||||
self.progress_label.setText(_("Cancelling..."))
|
||||
self._cleanup_thread()
|
||||
self._reset_buttons()
|
||||
self.progress_label.setText(_("Cancelled"))
|
||||
self.progress_bar.setValue(0)
|
||||
|
||||
def _reset_buttons(self):
|
||||
"""Reset identify/cancel buttons to initial state."""
|
||||
self.step_1_button.setVisible(True)
|
||||
self.step_1_button.setEnabled(True)
|
||||
self.cancel_button.setVisible(False)
|
||||
self.cancel_button.setEnabled(True)
|
||||
|
||||
def _on_thread_finished(self, result):
|
||||
"""Handle thread completion and cleanup."""
|
||||
logging.debug("Speaker identification: Thread finished")
|
||||
if self.thread is not None:
|
||||
self.thread.quit()
|
||||
self.thread.wait(5000)
|
||||
self._reset_buttons()
|
||||
self.on_identification_finished(result)
|
||||
|
||||
def on_identification_error(self, error_message):
|
||||
"""Handle identification error."""
|
||||
logging.error(f"Speaker identification error: {error_message}")
|
||||
self._reset_buttons()
|
||||
self.step_1_button.setEnabled(True)
|
||||
self.progress_bar.setValue(0)
|
||||
|
||||
def on_progress_update(self, progress):
|
||||
|
|
|
|||
|
|
@ -1,262 +0,0 @@
|
|||
import logging
|
||||
import os
|
||||
import platform
|
||||
import subprocess
|
||||
import tempfile
|
||||
from typing import Optional
|
||||
|
||||
from PyQt6.QtCore import Qt, QUrl
|
||||
from PyQt6.QtWidgets import QApplication
|
||||
from PyQt6.QtGui import QIcon
|
||||
from PyQt6.QtNetwork import QNetworkAccessManager, QNetworkRequest, QNetworkReply
|
||||
from PyQt6.QtWidgets import (
|
||||
QDialog,
|
||||
QVBoxLayout,
|
||||
QHBoxLayout,
|
||||
QLabel,
|
||||
QPushButton,
|
||||
QProgressBar,
|
||||
QMessageBox,
|
||||
QWidget,
|
||||
QTextEdit,
|
||||
)
|
||||
|
||||
from buzz.__version__ import VERSION
|
||||
from buzz.locale import _
|
||||
from buzz.update_checker import UpdateInfo
|
||||
from buzz.widgets.icon import BUZZ_ICON_PATH
|
||||
|
||||
class UpdateDialog(QDialog):
|
||||
"""Dialog shows when an update is available"""
|
||||
def __init__(
|
||||
self,
|
||||
update_info: UpdateInfo,
|
||||
network_manager: Optional[QNetworkAccessManager] = None,
|
||||
parent: Optional[QWidget] = None
|
||||
):
|
||||
super().__init__(parent)
|
||||
|
||||
self.update_info = update_info
|
||||
|
||||
if network_manager is None:
|
||||
network_manager = QNetworkAccessManager(self)
|
||||
self.network_manager = network_manager
|
||||
|
||||
self._download_reply: Optional[QNetworkReply] = None
|
||||
self._temp_file_paths: list = []
|
||||
self._pending_urls: list = []
|
||||
self._temp_dir: Optional[str] = None
|
||||
|
||||
self._setup_ui()
|
||||
|
||||
def _setup_ui(self):
|
||||
self.setWindowTitle(_("Update Available"))
|
||||
self.setWindowIcon(QIcon(BUZZ_ICON_PATH))
|
||||
self.setMinimumWidth(450)
|
||||
|
||||
layout = QVBoxLayout(self)
|
||||
layout.setSpacing(16)
|
||||
|
||||
#header
|
||||
header_label = QLabel(
|
||||
_("A new version of Buzz is available!")
|
||||
)
|
||||
|
||||
header_label.setStyleSheet("font-size: 16px; font-weight: bold;")
|
||||
layout.addWidget(header_label)
|
||||
|
||||
#Version info
|
||||
version_layout = QHBoxLayout()
|
||||
|
||||
current_version_label = QLabel(_("Current version:"))
|
||||
current_version_value = QLabel(f"<b>{VERSION}</b>")
|
||||
|
||||
new_version_label = QLabel(_("New version:"))
|
||||
new_version_value = QLabel(f"<b>{self.update_info.version}</b>")
|
||||
|
||||
version_layout.addWidget(current_version_label)
|
||||
version_layout.addWidget(current_version_value)
|
||||
version_layout.addStretch()
|
||||
version_layout.addWidget(new_version_label)
|
||||
version_layout.addWidget(new_version_value)
|
||||
|
||||
layout.addLayout(version_layout)
|
||||
|
||||
#Release notes
|
||||
if self.update_info.release_notes:
|
||||
notes_label = QLabel(_("Release Notes:"))
|
||||
notes_label.setStyleSheet("font-weight: bold;")
|
||||
layout.addWidget(notes_label)
|
||||
|
||||
notes_text = QTextEdit()
|
||||
notes_text.setReadOnly(True)
|
||||
notes_text.setMarkdown(self.update_info.release_notes)
|
||||
notes_text.setMaximumHeight(150)
|
||||
layout.addWidget(notes_text)
|
||||
|
||||
#progress bar
|
||||
self.progress_bar = QProgressBar()
|
||||
self.progress_bar.setVisible(False)
|
||||
self.progress_bar.setTextVisible(True)
|
||||
layout.addWidget(self.progress_bar)
|
||||
|
||||
#Status label
|
||||
self.status_label = QLabel("")
|
||||
self.status_label.setAlignment(Qt.AlignmentFlag.AlignCenter)
|
||||
layout.addWidget(self.status_label)
|
||||
|
||||
#Buttons
|
||||
button_layout = QVBoxLayout()
|
||||
|
||||
self.download_button = QPushButton(_("Download and Install"))
|
||||
self.download_button.clicked.connect(self._on_download_clicked)
|
||||
self.download_button.setDefault(True)
|
||||
|
||||
button_layout.addStretch()
|
||||
button_layout.addWidget(self.download_button)
|
||||
|
||||
layout.addLayout(button_layout)
|
||||
|
||||
def _on_download_clicked(self):
|
||||
"""Starts downloading the installer"""
|
||||
if not self.update_info.download_urls:
|
||||
QMessageBox.warning(
|
||||
self,
|
||||
_("Error"),
|
||||
_("No download URL available for your platform.")
|
||||
)
|
||||
return
|
||||
|
||||
self.download_button.setEnabled(False)
|
||||
self.progress_bar.setVisible(True)
|
||||
self.progress_bar.setValue(0)
|
||||
self._temp_file_paths = []
|
||||
self._pending_urls = list(self.update_info.download_urls)
|
||||
self._temp_dir = tempfile.mkdtemp()
|
||||
self._download_next_file()
|
||||
|
||||
def _download_next_file(self):
|
||||
"""Download the next file in the queue"""
|
||||
if not self._pending_urls:
|
||||
self._all_downloads_finished()
|
||||
return
|
||||
|
||||
url_str = self._pending_urls[0]
|
||||
file_index = len(self.update_info.download_urls) - len(self._pending_urls) + 1
|
||||
total_files = len(self.update_info.download_urls)
|
||||
self.status_label.setText(
|
||||
_("Downloading file {} of {}...").format(file_index, total_files)
|
||||
)
|
||||
|
||||
url = QUrl(url_str)
|
||||
request = QNetworkRequest(url)
|
||||
|
||||
self._download_reply = self.network_manager.get(request)
|
||||
self._download_reply.downloadProgress.connect(self._on_download_progress)
|
||||
self._download_reply.finished.connect(self._on_download_finished)
|
||||
|
||||
def _on_download_progress(self, bytes_received: int, bytes_total: int):
|
||||
"""Update the progress bar during download"""
|
||||
if bytes_total > 0:
|
||||
progress = int((bytes_received / bytes_total) * 100)
|
||||
self.progress_bar.setValue(progress)
|
||||
|
||||
mb_received = bytes_received / (1024 * 1024)
|
||||
mb_total = bytes_total / (1024 * 1024)
|
||||
file_index = len(self.update_info.download_urls) - len(self._pending_urls) + 1
|
||||
total_files = len(self.update_info.download_urls)
|
||||
self.status_label.setText(
|
||||
_("Downloading file {} of {} ({:.1f} MB / {:.1f} MB)...").format(
|
||||
file_index, total_files, mb_received, mb_total
|
||||
)
|
||||
)
|
||||
|
||||
def _on_download_finished(self):
|
||||
"""Handles download completion for one file"""
|
||||
if self._download_reply is None:
|
||||
return
|
||||
|
||||
if self._download_reply.error() != QNetworkReply.NetworkError.NoError:
|
||||
error_msg = self._download_reply.errorString()
|
||||
logging.error(f"Download failed: {error_msg}")
|
||||
|
||||
QMessageBox.critical(
|
||||
self,
|
||||
_("Download Failed"),
|
||||
_("Failed to download the update: {}").format(error_msg)
|
||||
)
|
||||
|
||||
self._reset_ui()
|
||||
self._download_reply.deleteLater()
|
||||
self._download_reply = None
|
||||
return
|
||||
|
||||
data = self._download_reply.readAll().data()
|
||||
self._download_reply.deleteLater()
|
||||
self._download_reply = None
|
||||
|
||||
url_str = self._pending_urls.pop(0)
|
||||
|
||||
# Extract original filename from URL to preserve it
|
||||
original_filename = QUrl(url_str).fileName()
|
||||
if not original_filename:
|
||||
original_filename = f"download_{len(self._temp_file_paths)}"
|
||||
|
||||
try:
|
||||
temp_path = os.path.join(self._temp_dir, original_filename)
|
||||
with open(temp_path, "wb") as f:
|
||||
f.write(data)
|
||||
self._temp_file_paths.append(temp_path)
|
||||
logging.info(f"File saved to: {temp_path}")
|
||||
except Exception as e:
|
||||
logging.error(f"Failed to save file: {e}")
|
||||
QMessageBox.critical(
|
||||
self,
|
||||
_("Error"),
|
||||
_("Failed to save the installer: {}").format(str(e))
|
||||
)
|
||||
self._reset_ui()
|
||||
return
|
||||
|
||||
self._download_next_file()
|
||||
|
||||
def _all_downloads_finished(self):
|
||||
"""All files downloaded, run the installer"""
|
||||
self.progress_bar.setValue(100)
|
||||
self.status_label.setText(_("Download complete!"))
|
||||
self._run_installer()
|
||||
|
||||
def _run_installer(self):
|
||||
"""Run the downloaded installer"""
|
||||
if not self._temp_file_paths:
|
||||
return
|
||||
|
||||
installer_path = self._temp_file_paths[0]
|
||||
system = platform.system()
|
||||
|
||||
try:
|
||||
if system == "Windows":
|
||||
subprocess.Popen([installer_path], shell=True)
|
||||
|
||||
elif system == "Darwin":
|
||||
#open the DMG file
|
||||
subprocess.Popen(["open", installer_path])
|
||||
|
||||
# Close the app so the installer can replace files
|
||||
self.accept()
|
||||
QApplication.quit()
|
||||
|
||||
except Exception as e:
|
||||
logging.error(f"Failed to run installer: {e}")
|
||||
QMessageBox.critical(
|
||||
self,
|
||||
_("Error"),
|
||||
_("Failed to run the installer: {}").format(str(e))
|
||||
)
|
||||
|
||||
def _reset_ui(self):
|
||||
"""Reset the UI to initial state after an error"""
|
||||
self.download_button.setEnabled(True)
|
||||
self.progress_bar.setVisible(False)
|
||||
self.status_label.setText("")
|
||||
|
||||
|
|
@ -16,11 +16,11 @@ title: File Import
|
|||
To reduce misspellings you can pass some commonly misspelled words in an `Initial prompt` that is available under `Advanced...` button. See this [guide on prompting](https://cookbook.openai.com/examples/whisper_prompting_guide#pass-names-in-the-prompt-to-prevent-misspellings).
|
||||
|
||||
|
||||
| Field | Options | Default | Description |
|
||||
| ------------------ | ------------------- | ------- |--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| Export As | "TXT", "SRT", "VTT" | "TXT" | Export file format |
|
||||
| Word-Level Timings | Off / On | Off | If checked, the transcription will generate a separate subtitle line for each word in the audio. Combine words into subtitles afterwards with the [resize option](https://chidiwilliams.github.io/buzz/docs/usage/edit_and_resize). |
|
||||
| Extract speech | Off / On | Off | If checked, speech will be extracted to a separate audio tack to improve accuracy. |
|
||||
| Field | Options | Default | Description |
|
||||
| ------------------ | ------------------- | ------- |---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| Export As | "TXT", "SRT", "VTT" | "TXT" | Export file format |
|
||||
| Word-Level Timings | Off / On | Off | If checked, the transcription will generate a separate subtitle line for each word in the audio. Combine words into subtitles afterwards with the [resize option](https://chidiwilliams.github.io/buzz/docs/usage/edit_and_resize). |
|
||||
| Extract speech | Off / On | Off | If checked, speech will be extracted to a separate audio tack to improve accuracy. Available since 1.3.0. |
|
||||
|
||||
(See the [Live Recording section](https://chidiwilliams.github.io/buzz/docs/usage/live_recording) for more information about the task, language, and quality settings.)
|
||||
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@ To start a live recording:
|
|||
- Click Record.
|
||||
|
||||
> **Note:** Transcribing audio using the default Whisper model is resource-intensive. Consider using the Whisper.cpp.
|
||||
> It supports GPU acceleration, if the model fits in GPU memory. Use smaller models for real-time performance.
|
||||
> Since 1.3.0 it supports GPU acceleration, if the model fits in GPU memory. Use smaller models for real-time performance.
|
||||
|
||||
| Field | Options | Default | Description |
|
||||
|------------|------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
|
|
@ -18,18 +18,7 @@ To start a live recording:
|
|||
|
||||
[](https://www.loom.com/share/564b753eb4d44b55b985b8abd26b55f7 "Live Recording on Buzz")
|
||||
|
||||
#### Advanced preferences
|
||||
**Silence threshold** Set threshold to for transcriptions to be processed. If average volume level is under this setting the sentence will not be transcribed. Available since 1.4.4.
|
||||
|
||||
**Line separator** Marking to add to the transcription and translation lines. Default value is two new lines (`\n\n`) that result in an empty space between translation or transcription lines. To have no empty line use `\n`. Available since 1.4.4.
|
||||
|
||||
**Transcription step** If live recording mode is set to `Append and correct`, you can also set a transcription step. Shorter steps will reduce latency but cause larger load on the system. Monitor the `Queue` while transcribing in this mode, if it grows too much, increase the transcription step, to reduce load. Available since 1.4.4.
|
||||
|
||||
**Hide unconfirmed** If live recording mode is set to `Append and correct`, you can also hide the unconfirmed part of the last transcript. This part may be incorrect as the Buzz has seen it only in one overlapping transcription segment. Hiding it will increase latency, but result will show only the correct transcripts. Available since 1.4.4.
|
||||
|
||||
#### Presentation Window
|
||||
|
||||
Buzz has an easy to use presentation window you can use to show live transcriptions during events and presentations. To open it start the recording and new options for the `Presentation window` will appear.
|
||||
**Presentation Window** Since 1.4.2 Buzz has an easy to use presentation window you can use to show live transcriptions during events and presentations. To open it start the recording and new options for the `Presentation window` will appear.
|
||||
|
||||
### Record audio playing from computer (macOS)
|
||||
|
||||
|
|
|
|||
|
|
@ -2,7 +2,7 @@
|
|||
title: Translations
|
||||
---
|
||||
|
||||
Default `Translation` task uses Whisper model ability to translate to English, however `Large-V3-Turbo` is not compatible with this standard. Buzz supports additional AI translations to any other language.
|
||||
Default `Translation` task uses Whisper model ability to translate to English, however `Large-V3-Turbo` is not compatible with this standard. Since version `1.0.0` Buzz supports additional AI translations to any other language.
|
||||
|
||||
To use translation feature you will need to configure OpenAI API key and translation settings. Set OpenAI API ket in Preferences. Buzz also supports custom locally running translation AIs that support OpenAI API. For more information on locally running AIs see [ollama](https://ollama.com/blog/openai-compatibility) or [LM Studio](https://lmstudio.ai/). For information on available custom APIs see this [discussion thread](https://github.com/chidiwilliams/buzz/discussions/827).
|
||||
|
||||
|
|
|
|||
|
|
@ -8,6 +8,6 @@ When transcript of some audio or video file is generated you can edit it and exp
|
|||
|
||||
Transcription view screen has option to resize the transcripts. Click on the "Resize" button so see available options. Transcripts that have been generated **with word-level timings** setting enabled can be combined into subtitles specifying different options, like maximum length of a subtitle and if subtitles should be split on punctuation. For transcripts that have been generated **without word-level timings** setting enabled can only be recombined specifying desired max length of a subtitle.
|
||||
|
||||
If audio file is still present on the system word-level timing merge will also analyze the audio for silences to improve subtitle accuracy.
|
||||
If audio file is still present on the system word-level timing merge will also analyze the audio for silences to improve subtitle accuracy. Subtitle generation from transcripts with word-level timings is available since version 1.3.0.
|
||||
|
||||
The resize tool also has an option to extend end time of segments if you want the subtitles to be on the screen for longer. You can specify the amount of time in seconds to extend each subtitle segment. Buzz will add this amount of time to the end of each subtitle segment making sure that the end of a segment does not go over start of the next segment. This feature is available since 1.4.3.
|
||||
|
|
@ -6,4 +6,4 @@ When transcript of some audio or video file is generated you can identify speake
|
|||
|
||||
Transcription view screen has option to identify speakers. Click on the "Identify speakers" button so see available options.
|
||||
|
||||
If audio file is still present on the system speaker identification will mark each speakers sentences with appropriate label. You can preview 10 seconds of some random sentence of the identified speaker and rename the automatically identified label to speakers real name. If "Merge speaker sentences" checkbox is selected when you save the speaker labels, all consecutive sentences of the same speaker will be merged into one segment. Speaker identification is not available on Intel macOS.
|
||||
If audio file is still present on the system speaker identification will mark each speakers sentences with appropriate label. You can preview 10 seconds of some random sentence of the identified speaker and rename the automatically identified label to speakers real name. If "Merge speaker sentences" checkbox is selected when you save the speaker labels, all consecutive sentences of the same speaker will be merged into one segment. Speaker identification is available since version 1.4.0 on all platforms except Intel macOS.
|
||||
|
|
@ -9,7 +9,7 @@ The transcription viewer is organized into several key sections:
|
|||
- **Top Toolbar**: Contains view mode, export, translate, resize, and search
|
||||
- **Search Bar**: Find and navigate through transcript text
|
||||
- **Transcription Segments**: Table view of all transcription segments with timestamps
|
||||
- **Playback Controls**: Audio playback settings and speed controls
|
||||
- **Playback Controls**: Audio playback settings and speed controls (since version 1.3.0)
|
||||
- **Audio Player**: Standard media player with progress bar
|
||||
- **Current Segment Display**: Shows the currently selected or playing segment
|
||||
|
||||
|
|
@ -37,21 +37,25 @@ The transcription viewer is organized into several key sections:
|
|||
- **More information**: See [Edit and Resize](https://chidiwilliams.github.io/buzz/docs/usage/edit_and_resize) section
|
||||
|
||||
### Playback Controls Button
|
||||
(since version 1.3.0)
|
||||
- **Function**: Show/hide playback control panel
|
||||
- **Shortcut**: `Ctrl+Alt+P` (Windows/Linux) or `Cmd+Alt+P` (macOS)
|
||||
- **Behavior**: Toggle button that shows/hides the playback controls below
|
||||
|
||||
### Find Button
|
||||
(since version 1.3.0)
|
||||
- **Function**: Show/hide search functionality
|
||||
- **Shortcut**: `Ctrl+F` (Windows/Linux) or `Cmd+F` (macOS)
|
||||
- **Behavior**: Toggle button that shows/hides the search bar
|
||||
|
||||
### Scroll to Current Button
|
||||
(since version 1.3.0)
|
||||
- **Function**: Automatically scroll to the currently playing text
|
||||
- **Shortcut**: `Ctrl+G` (Windows/Linux) or `Cmd+G` (macOS)
|
||||
- **Usage**: Click to jump to the current audio position in the transcript
|
||||
|
||||
## Search Functionality
|
||||
(since version 1.3.0)
|
||||
|
||||
### Search Bar
|
||||
The search bar appears below the toolbar when activated and provides:
|
||||
|
|
@ -76,6 +80,7 @@ The search bar appears below the toolbar when activated and provides:
|
|||
- **Cross-view Search**: Works in all view modes (Timestamps, Text, Translation)
|
||||
|
||||
## Playback Controls
|
||||
(since version 1.3.0)
|
||||
|
||||
### Loop Segment
|
||||
- **Function**: Automatically loop playback of selected segments
|
||||
|
|
@ -100,6 +105,7 @@ The search bar appears below the toolbar when activated and provides:
|
|||
- **Button Sizing**: Speed control buttons match the size of search navigation buttons for visual consistency
|
||||
|
||||
## Keyboard Shortcuts
|
||||
(since version 1.3.0)
|
||||
|
||||
### Audio Playback
|
||||
- **`Ctrl+P` / `Cmd+P`**: Play/Pause audio
|
||||
|
|
|
|||
|
|
@ -82,42 +82,6 @@ class CustomBuildHook(BuildHookInterface):
|
|||
# Build ctc_forced_aligner C++ extension in-place
|
||||
print("Building ctc_forced_aligner C++ extension...")
|
||||
ctc_aligner_dir = project_root / "ctc_forced_aligner"
|
||||
|
||||
# Apply local patches before building.
|
||||
# Uses --check first to avoid touching the working tree unnecessarily,
|
||||
# which is safer in a detached-HEAD submodule.
|
||||
patches_dir = project_root / "patches"
|
||||
for patch_file in sorted(patches_dir.glob("ctc_forced_aligner_*.patch")):
|
||||
# Dry-run forward: succeeds only if patch is NOT yet applied.
|
||||
check_forward = subprocess.run(
|
||||
["git", "apply", "--check", "--ignore-whitespace", str(patch_file)],
|
||||
cwd=ctc_aligner_dir,
|
||||
capture_output=True,
|
||||
text=True,
|
||||
)
|
||||
if check_forward.returncode == 0:
|
||||
# Patch can be applied — do it for real.
|
||||
subprocess.run(
|
||||
["git", "apply", "--ignore-whitespace", str(patch_file)],
|
||||
cwd=ctc_aligner_dir,
|
||||
check=True,
|
||||
capture_output=True,
|
||||
text=True,
|
||||
)
|
||||
print(f"Applied patch: {patch_file.name}")
|
||||
else:
|
||||
# Dry-run failed — either already applied or genuinely broken.
|
||||
check_reverse = subprocess.run(
|
||||
["git", "apply", "--check", "--reverse", "--ignore-whitespace", str(patch_file)],
|
||||
cwd=ctc_aligner_dir,
|
||||
capture_output=True,
|
||||
text=True,
|
||||
)
|
||||
if check_reverse.returncode == 0:
|
||||
print(f"Patch already applied (skipping): {patch_file.name}")
|
||||
else:
|
||||
print(f"WARNING: could not apply patch {patch_file.name}: {check_forward.stderr}", file=sys.stderr)
|
||||
|
||||
result = subprocess.run(
|
||||
[sys.executable, "setup.py", "build_ext", "--inplace"],
|
||||
cwd=ctc_aligner_dir,
|
||||
|
|
|
|||
|
|
@ -1,16 +0,0 @@
|
|||
diff --git a/setup.py b/setup.py
|
||||
index de84a25..386f662 100644
|
||||
--- a/setup.py
|
||||
+++ b/setup.py
|
||||
@@ -6,7 +6,10 @@ ext_modules = [
|
||||
Pybind11Extension(
|
||||
"ctc_forced_aligner.ctc_forced_aligner",
|
||||
["ctc_forced_aligner/forced_align_impl.cpp"],
|
||||
- extra_compile_args=["/O2"] if sys.platform == "win32" else ["-O3"],
|
||||
+ # /D_DISABLE_CONSTEXPR_MUTEX_CONSTRUCTOR prevents MSVC runtime mutex
|
||||
+ # static-initializer crash on newer GitHub Actions Windows runners.
|
||||
+ # See: https://github.com/actions/runner-images/issues/10004
|
||||
+ extra_compile_args=["/O2", "/D_DISABLE_CONSTEXPR_MUTEX_CONSTRUCTOR"] if sys.platform == "win32" else ["-O3"],
|
||||
)
|
||||
]
|
||||
|
||||
|
|
@ -1,7 +1,7 @@
|
|||
[project]
|
||||
name = "buzz-captions"
|
||||
# Change also in Makefile and buzz/__version__.py
|
||||
version = "1.4.4"
|
||||
version = "1.4.3"
|
||||
description = ""
|
||||
authors = [{ name = "Chidi Williams", email = "williamschidi1@gmail.com" }]
|
||||
requires-python = ">=3.12,<3.13"
|
||||
|
|
@ -20,7 +20,7 @@ dependencies = [
|
|||
"dataclasses-json>=0.6.4,<0.7",
|
||||
"numpy>=1.21.2,<2",
|
||||
"requests>=2.31.0,<3",
|
||||
"yt-dlp>=2026.2.21",
|
||||
"yt-dlp>=2025.11.12,<2026",
|
||||
"stable-ts>=2.19.1,<3",
|
||||
"faster-whisper>=1.2.1,<2",
|
||||
"openai-whisper==20250625",
|
||||
|
|
@ -184,14 +184,6 @@ sources = {"demucs_repo/demucs" = "demucs"}
|
|||
requires = ["hatchling", "cmake>=4.2.0,<5", "polib>=1.2.0,<2", "pybind11", "setuptools>=80.9.0"]
|
||||
build-backend = "hatchling.build"
|
||||
|
||||
[tool.coverage.report]
|
||||
exclude_also = [
|
||||
"if sys.platform == \"win32\":",
|
||||
"if platform.system\\(\\) == \"Windows\":",
|
||||
"if platform.system\\(\\) == \"Linux\":",
|
||||
"if platform.system\\(\\) == \"Darwin\":",
|
||||
]
|
||||
|
||||
[tool.ruff]
|
||||
exclude = [
|
||||
"**/whisper.cpp",
|
||||
|
|
|
|||
|
|
@ -65,20 +65,6 @@
|
|||
<content_rating type="oars-1.1"/>
|
||||
|
||||
<releases>
|
||||
<release version="1.4.4" date="2026-03-08">
|
||||
<url type="details">https://github.com/chidiwilliams/buzz/releases/tag/v1.4.4</url>
|
||||
<description>
|
||||
<p>Bug fixes and minor improvements.</p>
|
||||
<ul>
|
||||
<li>Fixed Youtube link downloading</li>
|
||||
<li>Added option to import folder</li>
|
||||
<li>Extra settings for live recordings</li>
|
||||
<li>Adjusted live recording batching process to avoid min-word cuts</li>
|
||||
<li>Update checker for Windows and Macs</li>
|
||||
<li>Added voice activity detection to whisper.cpp</li>
|
||||
</ul>
|
||||
</description>
|
||||
</release>
|
||||
<release version="1.4.3" date="2026-01-26">
|
||||
<url type="details">https://github.com/chidiwilliams/buzz/releases/tag/v1.4.3</url>
|
||||
<description>
|
||||
|
|
|
|||
|
|
@ -50,23 +50,8 @@ parts:
|
|||
prime:
|
||||
- etc/asound.conf
|
||||
|
||||
portaudio:
|
||||
after: [ alsa-pulseaudio ]
|
||||
plugin: autotools
|
||||
source: https://files.portaudio.com/archives/pa_stable_v190700_20210406.tgz
|
||||
build-packages:
|
||||
- libasound2-dev
|
||||
- libpulse-dev
|
||||
autotools-configure-parameters:
|
||||
- --enable-shared
|
||||
- --disable-static
|
||||
stage:
|
||||
- usr/local/lib/libportaudio*
|
||||
prime:
|
||||
- usr/local/lib/libportaudio*
|
||||
|
||||
buzz:
|
||||
after: [ alsa-pulseaudio, portaudio ]
|
||||
after: [ alsa-pulseaudio ]
|
||||
plugin: uv
|
||||
source: .
|
||||
build-snaps:
|
||||
|
|
@ -93,8 +78,9 @@ parts:
|
|||
- libproxy1v5
|
||||
# Audio
|
||||
- ffmpeg
|
||||
- libportaudio2
|
||||
- libpulse0
|
||||
- libasound2t64
|
||||
- libasound2
|
||||
- libasound2-dev
|
||||
- libasound2-plugins
|
||||
- libasound2-plugins-extra
|
||||
|
|
@ -129,12 +115,6 @@ parts:
|
|||
# Clean caches
|
||||
uv cache clean
|
||||
|
||||
# Create launcher wrapper to ensure the snap's own portaudio and libasound are found
|
||||
# before gnome content snap libraries (which desktop-launch prepends to LD_LIBRARY_PATH)
|
||||
mkdir -p $CRAFT_PART_INSTALL/bin
|
||||
printf '#!/bin/sh\nexport LD_LIBRARY_PATH="$SNAP/usr/local/lib:$SNAP/usr/lib/x86_64-linux-gnu:$LD_LIBRARY_PATH"\nexec "$SNAP/bin/python" -m buzz "$@"\n' > $CRAFT_PART_INSTALL/bin/buzz-launcher
|
||||
chmod +x $CRAFT_PART_INSTALL/bin/buzz-launcher
|
||||
|
||||
# Copy source files
|
||||
cp -r $CRAFT_PART_BUILD/buzz $CRAFT_PART_INSTALL/
|
||||
cp -r $CRAFT_PART_BUILD/ctc_forced_aligner $CRAFT_PART_INSTALL/
|
||||
|
|
@ -168,11 +148,11 @@ apps:
|
|||
- gnome
|
||||
command-chain:
|
||||
- bin/gpu-2404-wrapper
|
||||
command: snap/command-chain/desktop-launch $SNAP/bin/buzz-launcher
|
||||
command: snap/command-chain/desktop-launch $SNAP/bin/python -m buzz
|
||||
desktop: usr/share/applications/buzz.desktop
|
||||
environment:
|
||||
PATH: $SNAP/usr/bin:$SNAP/bin:$PATH
|
||||
LD_LIBRARY_PATH: $SNAP/usr/local/lib:$SNAP/lib/python3.12/site-packages/nvidia/cudnn/lib:$SNAP/lib/python3.12/site-packages/PyQt6:$SNAP/lib/python3.12/site-packages/PyQt6/Qt6/lib:$SNAP/usr/lib/$CRAFT_ARCH_TRIPLET_BUILD_FOR/lapack:$SNAP/usr/lib/$CRAFT_ARCH_TRIPLET_BUILD_FOR/blas:$SNAP/usr/lib/$CRAFT_ARCH_TRIPLET_BUILD_FOR/oss4-libsalsa:$SNAP/usr/lib/$CRAFT_ARCH_TRIPLET_BUILD_FOR/libproxy:$SNAP/usr/lib/$CRAFT_ARCH_TRIPLET_BUILD_FOR/alsa-lib:$SNAP:$LD_LIBRARY_PATH
|
||||
LD_LIBRARY_PATH: $SNAP/lib/python3.12/site-packages/nvidia/cudnn/lib:$SNAP/lib/python3.12/site-packages/PyQt6:$SNAP/lib/python3.12/site-packages/PyQt6/Qt6/lib:$SNAP/usr/lib/$CRAFT_ARCH_TRIPLET_BUILD_FOR/lapack:$SNAP/usr/lib/$CRAFT_ARCH_TRIPLET_BUILD_FOR/blas:$SNAP/usr/lib/$CRAFT_ARCH_TRIPLET_BUILD_FOR/oss4-libsalsa:$SNAP/usr/lib/$CRAFT_ARCH_TRIPLET_BUILD_FOR/libproxy:$SNAP:$LD_LIBRARY_PATH
|
||||
PYTHONPATH: $SNAP:$SNAP/lib/python3.12/site-packages/PyQt6:$SNAP/lib/python3.12/site-packages/PyQt6/Qt6/lib:$SNAP/usr/lib/python3/dist-packages:$SNAP/usr/lib/python3.12/site-packages:$SNAP/usr/local/lib/python3.12/dist-packages:$SNAP/usr/lib/python3.12/dist-packages:$PYTHONPATH
|
||||
QT_MEDIA_BACKEND: ffmpeg
|
||||
PULSE_LATENCY_MSEC: "30"
|
||||
|
|
@ -196,4 +176,4 @@ apps:
|
|||
|
||||
layout:
|
||||
/usr/lib/$CRAFT_ARCH_TRIPLET_BUILD_FOR/alsa-lib:
|
||||
bind: $SNAP/usr/lib/$CRAFT_ARCH_TRIPLET_BUILD_FOR/alsa-lib
|
||||
bind: $SNAP/usr/lib/$CRAFT_ARCH_TRIPLET_BUILD_FOR/alsa-lib
|
||||
|
|
@ -6,7 +6,7 @@ from unittest.mock import Mock, patch
|
|||
import pytest
|
||||
import sounddevice
|
||||
from PyQt6.QtCore import Qt
|
||||
from PyQt6.QtGui import QKeyEvent
|
||||
from PyQt6.QtGui import QValidator, QKeyEvent
|
||||
from PyQt6.QtWidgets import (
|
||||
QApplication,
|
||||
QMessageBox,
|
||||
|
|
@ -21,6 +21,7 @@ from buzz.widgets.transcriber.hugging_face_search_line_edit import (
|
|||
HuggingFaceSearchLineEdit,
|
||||
)
|
||||
from buzz.widgets.transcriber.languages_combo_box import LanguagesComboBox
|
||||
from buzz.widgets.transcriber.temperature_validator import TemperatureValidator
|
||||
from buzz.widgets.about_dialog import AboutDialog
|
||||
from buzz.settings.settings import Settings
|
||||
from buzz.transcriber.transcriber import (
|
||||
|
|
@ -114,6 +115,7 @@ class TestAdvancedSettingsDialog:
|
|||
def test_should_update_advanced_settings(self, qtbot: QtBot):
|
||||
dialog = AdvancedSettingsDialog(
|
||||
transcription_options=TranscriptionOptions(
|
||||
temperature=(0.0, 0.8),
|
||||
initial_prompt="prompt",
|
||||
enable_llm_translation=False,
|
||||
llm_model="",
|
||||
|
|
@ -126,22 +128,40 @@ class TestAdvancedSettingsDialog:
|
|||
dialog.transcription_options_changed.connect(transcription_options_mock)
|
||||
|
||||
assert dialog.windowTitle() == _("Advanced Settings")
|
||||
assert dialog.temperature_line_edit.text() == "0.0, 0.8"
|
||||
assert dialog.initial_prompt_text_edit.toPlainText() == "prompt"
|
||||
assert dialog.enable_llm_translation_checkbox.isChecked() is False
|
||||
assert dialog.llm_model_line_edit.text() == "gpt-4.1-mini"
|
||||
assert dialog.llm_prompt_text_edit.toPlainText() == _("Please translate each text sent to you from English to Spanish. Translation will be used in an automated system, please do not add any comments or notes, just the translation.")
|
||||
assert dialog.llm_model_line_edit.text() == ""
|
||||
assert dialog.llm_prompt_text_edit.toPlainText() == ""
|
||||
|
||||
dialog.temperature_line_edit.setText("0.0, 0.8, 1.0")
|
||||
dialog.initial_prompt_text_edit.setPlainText("new prompt")
|
||||
dialog.enable_llm_translation_checkbox.setChecked(True)
|
||||
dialog.llm_model_line_edit.setText("model")
|
||||
dialog.llm_prompt_text_edit.setPlainText("Please translate this text")
|
||||
|
||||
assert transcription_options_mock.call_args[0][0].temperature == (0.0, 0.8, 1.0)
|
||||
assert transcription_options_mock.call_args[0][0].initial_prompt == "new prompt"
|
||||
assert transcription_options_mock.call_args[0][0].enable_llm_translation is True
|
||||
assert transcription_options_mock.call_args[0][0].llm_model == "model"
|
||||
assert transcription_options_mock.call_args[0][0].llm_prompt == "Please translate this text"
|
||||
|
||||
|
||||
class TestTemperatureValidator:
|
||||
validator = TemperatureValidator(None)
|
||||
|
||||
@pytest.mark.parametrize(
|
||||
"text,state",
|
||||
[
|
||||
("0.0,0.5,1.0", QValidator.State.Acceptable),
|
||||
("0.0,0.5,", QValidator.State.Intermediate),
|
||||
("0.0,0.5,p", QValidator.State.Invalid),
|
||||
],
|
||||
)
|
||||
def test_should_validate_temperature(self, text: str, state: QValidator.State):
|
||||
assert self.validator.validate(text, 0)[0] == state
|
||||
|
||||
|
||||
@pytest.mark.skipif(
|
||||
platform.system() == "Linux" and os.environ.get("XDG_SESSION_TYPE") == "wayland",
|
||||
reason="Skipping on Wayland sessions due to Qt popup issues"
|
||||
|
|
|
|||
|
|
@ -15,9 +15,6 @@ class MockNetworkReply(QNetworkReply):
|
|||
def error(self) -> "QNetworkReply.NetworkError":
|
||||
return QNetworkReply.NetworkError.NoError
|
||||
|
||||
def deleteLater(self) -> None:
|
||||
pass
|
||||
|
||||
|
||||
class MockNetworkAccessManager(QNetworkAccessManager):
|
||||
finished = pyqtSignal(object)
|
||||
|
|
@ -32,61 +29,3 @@ class MockNetworkAccessManager(QNetworkAccessManager):
|
|||
def get(self, _: "QNetworkRequest") -> "QNetworkReply":
|
||||
self.finished.emit(self.reply)
|
||||
return self.reply
|
||||
|
||||
|
||||
class MockDownloadReply(QObject):
|
||||
"""Mock reply for file downloads — supports downloadProgress and finished signals."""
|
||||
downloadProgress = pyqtSignal(int, int)
|
||||
finished = pyqtSignal()
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
data: bytes = b"fake-installer-data",
|
||||
network_error: "QNetworkReply.NetworkError" = QNetworkReply.NetworkError.NoError,
|
||||
error_string: str = "",
|
||||
parent: Optional[QObject] = None,
|
||||
) -> None:
|
||||
super().__init__(parent)
|
||||
self._data = data
|
||||
self._network_error = network_error
|
||||
self._error_string = error_string
|
||||
self._aborted = False
|
||||
|
||||
def readAll(self) -> QByteArray:
|
||||
return QByteArray(self._data)
|
||||
|
||||
def error(self) -> "QNetworkReply.NetworkError":
|
||||
return self._network_error
|
||||
|
||||
def errorString(self) -> str:
|
||||
return self._error_string
|
||||
|
||||
def abort(self) -> None:
|
||||
self._aborted = True
|
||||
|
||||
def deleteLater(self) -> None:
|
||||
pass
|
||||
|
||||
def emit_finished(self) -> None:
|
||||
self.finished.emit()
|
||||
|
||||
|
||||
class MockDownloadNetworkManager(QNetworkAccessManager):
|
||||
"""Network manager that returns MockDownloadReply instances for each get() call."""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
replies: Optional[list] = None,
|
||||
parent: Optional[QObject] = None,
|
||||
) -> None:
|
||||
super().__init__(parent)
|
||||
self._replies = list(replies) if replies else []
|
||||
self._index = 0
|
||||
|
||||
def get(self, _: "QNetworkRequest") -> "MockDownloadReply":
|
||||
if self._index < len(self._replies):
|
||||
reply = self._replies[self._index]
|
||||
else:
|
||||
reply = MockDownloadReply()
|
||||
self._index += 1
|
||||
return reply
|
||||
|
|
|
|||
|
|
@ -1,8 +1,12 @@
|
|||
import os
|
||||
from threading import Thread, Event
|
||||
import time
|
||||
import logging
|
||||
from threading import Thread
|
||||
from typing import Callable, Any
|
||||
from unittest.mock import MagicMock
|
||||
|
||||
import numpy as np
|
||||
import sounddevice
|
||||
|
||||
from buzz import whisper_audio
|
||||
|
||||
|
|
@ -95,52 +99,38 @@ mock_query_devices = [
|
|||
|
||||
|
||||
class MockInputStream:
|
||||
running = False
|
||||
thread: Thread
|
||||
samplerate = whisper_audio.SAMPLE_RATE
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
callback: Callable[[np.ndarray, int, Any, Any], None],
|
||||
callback: Callable[[np.ndarray, int, Any, sounddevice.CallbackFlags], None],
|
||||
*args,
|
||||
**kwargs,
|
||||
):
|
||||
self._stop_event = Event()
|
||||
self.callback = callback
|
||||
|
||||
# Pre-load audio on the calling (main) thread to avoid calling
|
||||
# subprocess.run (fork) from a background thread on macOS, which
|
||||
# can cause a segfault when Qt is running.
|
||||
sample_rate = whisper_audio.SAMPLE_RATE
|
||||
file_path = os.path.join(
|
||||
os.path.dirname(__file__), "../testdata/whisper-french.mp3"
|
||||
)
|
||||
self._audio = whisper_audio.load_audio(file_path, sr=sample_rate)
|
||||
|
||||
self.thread = Thread(target=self.target)
|
||||
self.callback = callback
|
||||
|
||||
def start(self):
|
||||
self.thread.start()
|
||||
|
||||
def target(self):
|
||||
sample_rate = whisper_audio.SAMPLE_RATE
|
||||
audio = self._audio
|
||||
file_path = os.path.join(
|
||||
os.path.dirname(__file__), "../testdata/whisper-french.mp3"
|
||||
)
|
||||
audio = whisper_audio.load_audio(file_path, sr=sample_rate)
|
||||
|
||||
chunk_duration_secs = 1
|
||||
|
||||
self.running = True
|
||||
seek = 0
|
||||
num_samples_in_chunk = chunk_duration_secs * sample_rate
|
||||
|
||||
while not self._stop_event.is_set():
|
||||
self._stop_event.wait(timeout=chunk_duration_secs)
|
||||
if self._stop_event.is_set():
|
||||
break
|
||||
while self.running:
|
||||
time.sleep(chunk_duration_secs)
|
||||
chunk = audio[seek : seek + num_samples_in_chunk]
|
||||
try:
|
||||
self.callback(chunk, 0, None, None)
|
||||
except RuntimeError:
|
||||
# Qt object was deleted between the stop-event check and
|
||||
# the callback invocation; treat it as a stop signal.
|
||||
break
|
||||
self.callback(chunk, 0, None, sounddevice.CallbackFlags())
|
||||
seek += num_samples_in_chunk
|
||||
|
||||
# loop back around
|
||||
|
|
@ -148,9 +138,8 @@ class MockInputStream:
|
|||
seek = 0
|
||||
|
||||
def stop(self):
|
||||
self._stop_event.set()
|
||||
if self.thread.is_alive():
|
||||
self.thread.join(timeout=5)
|
||||
self.running = False
|
||||
self.thread.join()
|
||||
|
||||
def close(self):
|
||||
self.stop()
|
||||
|
|
|
|||
|
|
@ -1,24 +1,7 @@
|
|||
import io
|
||||
import os
|
||||
import threading
|
||||
import time
|
||||
import pytest
|
||||
from unittest.mock import patch, MagicMock, call
|
||||
|
||||
from buzz.model_loader import (
|
||||
ModelDownloader,
|
||||
HuggingfaceDownloadMonitor,
|
||||
TranscriptionModel,
|
||||
ModelType,
|
||||
WhisperModelSize,
|
||||
map_language_to_mms,
|
||||
is_mms_model,
|
||||
get_expected_whisper_model_size,
|
||||
get_whisper_file_path,
|
||||
WHISPER_MODEL_SIZES,
|
||||
WHISPER_CPP_REPO_ID,
|
||||
WHISPER_CPP_LUMII_REPO_ID,
|
||||
)
|
||||
from buzz.model_loader import ModelDownloader,TranscriptionModel, ModelType, WhisperModelSize
|
||||
|
||||
|
||||
class TestModelLoader:
|
||||
|
|
@ -40,730 +23,3 @@ class TestModelLoader:
|
|||
assert model_path is not None, "Model path is None"
|
||||
assert os.path.isdir(model_path), "Model path is not a directory"
|
||||
assert len(os.listdir(model_path)) > 0, "Model directory is empty"
|
||||
|
||||
|
||||
class TestMapLanguageToMms:
|
||||
def test_empty_returns_english(self):
|
||||
assert map_language_to_mms("") == "eng"
|
||||
|
||||
def test_two_letter_known_code(self):
|
||||
assert map_language_to_mms("en") == "eng"
|
||||
assert map_language_to_mms("fr") == "fra"
|
||||
assert map_language_to_mms("lv") == "lav"
|
||||
|
||||
def test_three_letter_code_returned_as_is(self):
|
||||
assert map_language_to_mms("eng") == "eng"
|
||||
assert map_language_to_mms("fra") == "fra"
|
||||
|
||||
def test_unknown_two_letter_code_returned_as_is(self):
|
||||
assert map_language_to_mms("xx") == "xx"
|
||||
|
||||
@pytest.mark.parametrize(
|
||||
"code,expected",
|
||||
[
|
||||
("de", "deu"),
|
||||
("es", "spa"),
|
||||
("ja", "jpn"),
|
||||
("zh", "cmn"),
|
||||
("ar", "ara"),
|
||||
],
|
||||
)
|
||||
def test_various_language_codes(self, code, expected):
|
||||
assert map_language_to_mms(code) == expected
|
||||
|
||||
|
||||
class TestIsMmsModel:
|
||||
def test_empty_string(self):
|
||||
assert is_mms_model("") is False
|
||||
|
||||
def test_mms_in_model_id(self):
|
||||
assert is_mms_model("facebook/mms-1b-all") is True
|
||||
|
||||
def test_mms_case_insensitive(self):
|
||||
assert is_mms_model("facebook/MMS-1b-all") is True
|
||||
|
||||
def test_non_mms_model(self):
|
||||
assert is_mms_model("openai/whisper-tiny") is False
|
||||
|
||||
|
||||
class TestWhisperModelSize:
|
||||
def test_to_faster_whisper_model_size_large(self):
|
||||
assert WhisperModelSize.LARGE.to_faster_whisper_model_size() == "large-v1"
|
||||
|
||||
def test_to_faster_whisper_model_size_tiny(self):
|
||||
assert WhisperModelSize.TINY.to_faster_whisper_model_size() == "tiny"
|
||||
|
||||
def test_to_faster_whisper_model_size_largev3(self):
|
||||
assert WhisperModelSize.LARGEV3.to_faster_whisper_model_size() == "large-v3"
|
||||
|
||||
def test_to_whisper_cpp_model_size_large(self):
|
||||
assert WhisperModelSize.LARGE.to_whisper_cpp_model_size() == "large-v1"
|
||||
|
||||
def test_to_whisper_cpp_model_size_tiny(self):
|
||||
assert WhisperModelSize.TINY.to_whisper_cpp_model_size() == "tiny"
|
||||
|
||||
def test_str(self):
|
||||
assert str(WhisperModelSize.TINY) == "Tiny"
|
||||
assert str(WhisperModelSize.LARGE) == "Large"
|
||||
assert str(WhisperModelSize.LARGEV3TURBO) == "Large-v3-turbo"
|
||||
assert str(WhisperModelSize.CUSTOM) == "Custom"
|
||||
|
||||
|
||||
class TestModelType:
|
||||
def test_supports_initial_prompt(self):
|
||||
assert ModelType.WHISPER.supports_initial_prompt is True
|
||||
assert ModelType.WHISPER_CPP.supports_initial_prompt is True
|
||||
assert ModelType.OPEN_AI_WHISPER_API.supports_initial_prompt is True
|
||||
assert ModelType.FASTER_WHISPER.supports_initial_prompt is True
|
||||
assert ModelType.HUGGING_FACE.supports_initial_prompt is False
|
||||
|
||||
@pytest.mark.parametrize(
|
||||
"platform_system,platform_machine,expected_faster_whisper",
|
||||
[
|
||||
("Linux", "x86_64", True),
|
||||
("Windows", "AMD64", True),
|
||||
("Darwin", "arm64", True),
|
||||
("Darwin", "x86_64", False), # Faster Whisper not available on macOS x86_64
|
||||
],
|
||||
)
|
||||
def test_is_available(self, platform_system, platform_machine, expected_faster_whisper):
|
||||
with patch("platform.system", return_value=platform_system), \
|
||||
patch("platform.machine", return_value=platform_machine):
|
||||
# These should always be available
|
||||
assert ModelType.WHISPER.is_available() is True
|
||||
assert ModelType.HUGGING_FACE.is_available() is True
|
||||
assert ModelType.OPEN_AI_WHISPER_API.is_available() is True
|
||||
assert ModelType.WHISPER_CPP.is_available() is True
|
||||
|
||||
# Faster Whisper depends on platform
|
||||
assert ModelType.FASTER_WHISPER.is_available() == expected_faster_whisper
|
||||
|
||||
def test_is_manually_downloadable(self):
|
||||
assert ModelType.WHISPER.is_manually_downloadable() is True
|
||||
assert ModelType.WHISPER_CPP.is_manually_downloadable() is True
|
||||
assert ModelType.FASTER_WHISPER.is_manually_downloadable() is True
|
||||
assert ModelType.HUGGING_FACE.is_manually_downloadable() is False
|
||||
assert ModelType.OPEN_AI_WHISPER_API.is_manually_downloadable() is False
|
||||
|
||||
|
||||
class TestTranscriptionModel:
|
||||
def test_str_whisper(self):
|
||||
model = TranscriptionModel(
|
||||
model_type=ModelType.WHISPER, whisper_model_size=WhisperModelSize.TINY
|
||||
)
|
||||
assert str(model) == "Whisper (Tiny)"
|
||||
|
||||
def test_str_whisper_cpp(self):
|
||||
model = TranscriptionModel(
|
||||
model_type=ModelType.WHISPER_CPP, whisper_model_size=WhisperModelSize.BASE
|
||||
)
|
||||
assert str(model) == "Whisper.cpp (Base)"
|
||||
|
||||
def test_str_hugging_face(self):
|
||||
model = TranscriptionModel(
|
||||
model_type=ModelType.HUGGING_FACE,
|
||||
hugging_face_model_id="openai/whisper-tiny",
|
||||
)
|
||||
assert str(model) == "Hugging Face (openai/whisper-tiny)"
|
||||
|
||||
def test_str_faster_whisper(self):
|
||||
model = TranscriptionModel(
|
||||
model_type=ModelType.FASTER_WHISPER,
|
||||
whisper_model_size=WhisperModelSize.SMALL,
|
||||
)
|
||||
assert str(model) == "Faster Whisper (Small)"
|
||||
|
||||
def test_str_openai_api(self):
|
||||
model = TranscriptionModel(model_type=ModelType.OPEN_AI_WHISPER_API)
|
||||
assert str(model) == "OpenAI Whisper API"
|
||||
|
||||
def test_default(self):
|
||||
model = TranscriptionModel.default()
|
||||
assert model.model_type in list(ModelType)
|
||||
assert model.model_type.is_available() is True
|
||||
|
||||
def test_get_local_model_path_openai_api(self):
|
||||
model = TranscriptionModel(model_type=ModelType.OPEN_AI_WHISPER_API)
|
||||
assert model.get_local_model_path() == ""
|
||||
|
||||
|
||||
class TestGetExpectedWhisperModelSize:
|
||||
def test_known_sizes(self):
|
||||
assert get_expected_whisper_model_size(WhisperModelSize.TINY) == 72 * 1024 * 1024
|
||||
assert get_expected_whisper_model_size(WhisperModelSize.LARGE) == 2870 * 1024 * 1024
|
||||
|
||||
def test_unknown_size_returns_none(self):
|
||||
assert get_expected_whisper_model_size(WhisperModelSize.CUSTOM) is None
|
||||
assert get_expected_whisper_model_size(WhisperModelSize.LUMII) is None
|
||||
|
||||
def test_all_defined_sizes_have_values(self):
|
||||
for size in WHISPER_MODEL_SIZES:
|
||||
assert WHISPER_MODEL_SIZES[size] > 0
|
||||
|
||||
|
||||
class TestGetWhisperFilePath:
|
||||
def test_custom_size(self):
|
||||
path = get_whisper_file_path(WhisperModelSize.CUSTOM)
|
||||
assert path.endswith("custom")
|
||||
assert "whisper" in path
|
||||
|
||||
def test_tiny_size(self):
|
||||
path = get_whisper_file_path(WhisperModelSize.TINY)
|
||||
assert "whisper" in path
|
||||
assert path.endswith(".pt")
|
||||
|
||||
|
||||
class TestTranscriptionModelIsDeletable:
|
||||
def test_whisper_model_not_downloaded(self):
|
||||
model = TranscriptionModel(model_type=ModelType.WHISPER, whisper_model_size=WhisperModelSize.TINY)
|
||||
with patch.object(model, 'get_local_model_path', return_value=None):
|
||||
assert model.is_deletable() is False
|
||||
|
||||
def test_whisper_model_downloaded(self):
|
||||
model = TranscriptionModel(model_type=ModelType.WHISPER, whisper_model_size=WhisperModelSize.TINY)
|
||||
with patch.object(model, 'get_local_model_path', return_value="/some/path/model.pt"):
|
||||
assert model.is_deletable() is True
|
||||
|
||||
def test_openai_api_not_deletable(self):
|
||||
model = TranscriptionModel(model_type=ModelType.OPEN_AI_WHISPER_API)
|
||||
assert model.is_deletable() is False
|
||||
|
||||
def test_hugging_face_not_deletable(self):
|
||||
model = TranscriptionModel(
|
||||
model_type=ModelType.HUGGING_FACE,
|
||||
hugging_face_model_id="openai/whisper-tiny"
|
||||
)
|
||||
assert model.is_deletable() is False
|
||||
|
||||
|
||||
class TestTranscriptionModelGetLocalModelPath:
|
||||
def test_whisper_cpp_file_not_exists(self):
|
||||
model = TranscriptionModel(model_type=ModelType.WHISPER_CPP, whisper_model_size=WhisperModelSize.TINY)
|
||||
with patch('os.path.exists', return_value=False), \
|
||||
patch('os.path.isfile', return_value=False):
|
||||
assert model.get_local_model_path() is None
|
||||
|
||||
def test_whisper_file_not_exists(self):
|
||||
model = TranscriptionModel(model_type=ModelType.WHISPER, whisper_model_size=WhisperModelSize.TINY)
|
||||
with patch('os.path.exists', return_value=False):
|
||||
assert model.get_local_model_path() is None
|
||||
|
||||
def test_whisper_file_too_small(self):
|
||||
model = TranscriptionModel(model_type=ModelType.WHISPER, whisper_model_size=WhisperModelSize.TINY)
|
||||
with patch('os.path.exists', return_value=True), \
|
||||
patch('os.path.isfile', return_value=True), \
|
||||
patch('os.path.getsize', return_value=1024): # 1KB, much smaller than expected
|
||||
assert model.get_local_model_path() is None
|
||||
|
||||
def test_whisper_file_valid(self):
|
||||
model = TranscriptionModel(model_type=ModelType.WHISPER, whisper_model_size=WhisperModelSize.TINY)
|
||||
expected_size = 72 * 1024 * 1024 # 72MB
|
||||
with patch('os.path.exists', return_value=True), \
|
||||
patch('os.path.isfile', return_value=True), \
|
||||
patch('os.path.getsize', return_value=expected_size):
|
||||
result = model.get_local_model_path()
|
||||
assert result is not None
|
||||
|
||||
def test_faster_whisper_not_found(self):
|
||||
model = TranscriptionModel(model_type=ModelType.FASTER_WHISPER, whisper_model_size=WhisperModelSize.TINY)
|
||||
with patch('buzz.model_loader.download_faster_whisper_model', side_effect=FileNotFoundError):
|
||||
assert model.get_local_model_path() is None
|
||||
|
||||
def test_hugging_face_not_found(self):
|
||||
model = TranscriptionModel(
|
||||
model_type=ModelType.HUGGING_FACE,
|
||||
hugging_face_model_id="some/model"
|
||||
)
|
||||
import huggingface_hub
|
||||
with patch.object(huggingface_hub, 'snapshot_download', side_effect=FileNotFoundError):
|
||||
assert model.get_local_model_path() is None
|
||||
|
||||
|
||||
class TestTranscriptionModelOpenPath:
|
||||
def test_open_path_linux(self):
|
||||
with patch('sys.platform', 'linux'), \
|
||||
patch('subprocess.call') as mock_call:
|
||||
TranscriptionModel.open_path("/some/path")
|
||||
mock_call.assert_called_once_with(['xdg-open', '/some/path'])
|
||||
|
||||
def test_open_path_darwin(self):
|
||||
with patch('sys.platform', 'darwin'), \
|
||||
patch('subprocess.call') as mock_call:
|
||||
TranscriptionModel.open_path("/some/path")
|
||||
mock_call.assert_called_once_with(['open', '/some/path'])
|
||||
|
||||
|
||||
class TestTranscriptionModelOpenFileLocation:
|
||||
def test_whisper_opens_parent_directory(self):
|
||||
model = TranscriptionModel(model_type=ModelType.WHISPER, whisper_model_size=WhisperModelSize.TINY)
|
||||
with patch.object(model, 'get_local_model_path', return_value="/some/path/model.pt"), \
|
||||
patch.object(TranscriptionModel, 'open_path') as mock_open:
|
||||
model.open_file_location()
|
||||
mock_open.assert_called_once_with(path="/some/path")
|
||||
|
||||
def test_hugging_face_opens_grandparent_directory(self):
|
||||
model = TranscriptionModel(
|
||||
model_type=ModelType.HUGGING_FACE,
|
||||
hugging_face_model_id="openai/whisper-tiny"
|
||||
)
|
||||
with patch.object(model, 'get_local_model_path', return_value="/cache/models/snapshot/model.safetensors"), \
|
||||
patch.object(TranscriptionModel, 'open_path') as mock_open:
|
||||
model.open_file_location()
|
||||
# For HF: dirname(path) -> /cache/models/snapshot, then open_path(dirname(...)) -> /cache/models
|
||||
mock_open.assert_called_once_with(path="/cache/models")
|
||||
|
||||
def test_faster_whisper_opens_grandparent_directory(self):
|
||||
model = TranscriptionModel(model_type=ModelType.FASTER_WHISPER, whisper_model_size=WhisperModelSize.TINY)
|
||||
with patch.object(model, 'get_local_model_path', return_value="/cache/models/snapshot/model.bin"), \
|
||||
patch.object(TranscriptionModel, 'open_path') as mock_open:
|
||||
model.open_file_location()
|
||||
# For FW: dirname(path) -> /cache/models/snapshot, then open_path(dirname(...)) -> /cache/models
|
||||
mock_open.assert_called_once_with(path="/cache/models")
|
||||
|
||||
def test_no_model_path_does_nothing(self):
|
||||
model = TranscriptionModel(model_type=ModelType.WHISPER, whisper_model_size=WhisperModelSize.TINY)
|
||||
with patch.object(model, 'get_local_model_path', return_value=None), \
|
||||
patch.object(TranscriptionModel, 'open_path') as mock_open:
|
||||
model.open_file_location()
|
||||
mock_open.assert_not_called()
|
||||
|
||||
|
||||
class TestTranscriptionModelDeleteLocalFile:
|
||||
def test_whisper_model_removes_file(self, tmp_path):
|
||||
model_file = tmp_path / "model.pt"
|
||||
model_file.write_bytes(b"fake model data")
|
||||
model = TranscriptionModel(model_type=ModelType.WHISPER, whisper_model_size=WhisperModelSize.TINY)
|
||||
with patch.object(model, 'get_local_model_path', return_value=str(model_file)):
|
||||
model.delete_local_file()
|
||||
assert not model_file.exists()
|
||||
|
||||
def test_whisper_cpp_custom_removes_file(self, tmp_path):
|
||||
model_file = tmp_path / "ggml-model-whisper-custom.bin"
|
||||
model_file.write_bytes(b"fake model data")
|
||||
model = TranscriptionModel(model_type=ModelType.WHISPER_CPP, whisper_model_size=WhisperModelSize.CUSTOM)
|
||||
with patch.object(model, 'get_local_model_path', return_value=str(model_file)):
|
||||
model.delete_local_file()
|
||||
assert not model_file.exists()
|
||||
|
||||
def test_whisper_cpp_non_custom_removes_bin_file(self, tmp_path):
|
||||
model_file = tmp_path / "ggml-tiny.bin"
|
||||
model_file.write_bytes(b"fake model data")
|
||||
model = TranscriptionModel(model_type=ModelType.WHISPER_CPP, whisper_model_size=WhisperModelSize.TINY)
|
||||
with patch.object(model, 'get_local_model_path', return_value=str(model_file)):
|
||||
model.delete_local_file()
|
||||
assert not model_file.exists()
|
||||
|
||||
def test_whisper_cpp_non_custom_removes_coreml_files(self, tmp_path):
|
||||
model_file = tmp_path / "ggml-tiny.bin"
|
||||
model_file.write_bytes(b"fake model data")
|
||||
coreml_zip = tmp_path / "ggml-tiny-encoder.mlmodelc.zip"
|
||||
coreml_zip.write_bytes(b"fake zip")
|
||||
coreml_dir = tmp_path / "ggml-tiny-encoder.mlmodelc"
|
||||
coreml_dir.mkdir()
|
||||
model = TranscriptionModel(model_type=ModelType.WHISPER_CPP, whisper_model_size=WhisperModelSize.TINY)
|
||||
with patch.object(model, 'get_local_model_path', return_value=str(model_file)):
|
||||
model.delete_local_file()
|
||||
assert not model_file.exists()
|
||||
assert not coreml_zip.exists()
|
||||
assert not coreml_dir.exists()
|
||||
|
||||
def test_hugging_face_removes_directory_tree(self, tmp_path):
|
||||
# Structure: models--repo/snapshots/abc/model.safetensors
|
||||
# delete_local_file does dirname(dirname(model_path)) = snapshots_dir
|
||||
repo_dir = tmp_path / "models--repo"
|
||||
snapshots_dir = repo_dir / "snapshots"
|
||||
snapshot_dir = snapshots_dir / "abc123"
|
||||
snapshot_dir.mkdir(parents=True)
|
||||
model_file = snapshot_dir / "model.safetensors"
|
||||
model_file.write_bytes(b"fake model")
|
||||
|
||||
model = TranscriptionModel(
|
||||
model_type=ModelType.HUGGING_FACE,
|
||||
hugging_face_model_id="some/repo"
|
||||
)
|
||||
with patch.object(model, 'get_local_model_path', return_value=str(model_file)):
|
||||
model.delete_local_file()
|
||||
# Two dirs up from model_file: dirname(dirname(model_file)) = snapshots_dir
|
||||
assert not snapshots_dir.exists()
|
||||
|
||||
def test_faster_whisper_removes_directory_tree(self, tmp_path):
|
||||
repo_dir = tmp_path / "faster-whisper-tiny"
|
||||
snapshots_dir = repo_dir / "snapshots"
|
||||
snapshot_dir = snapshots_dir / "abc123"
|
||||
snapshot_dir.mkdir(parents=True)
|
||||
model_file = snapshot_dir / "model.bin"
|
||||
model_file.write_bytes(b"fake model")
|
||||
|
||||
model = TranscriptionModel(model_type=ModelType.FASTER_WHISPER, whisper_model_size=WhisperModelSize.TINY)
|
||||
with patch.object(model, 'get_local_model_path', return_value=str(model_file)):
|
||||
model.delete_local_file()
|
||||
# Two dirs up from model_file: dirname(dirname(model_file)) = snapshots_dir
|
||||
assert not snapshots_dir.exists()
|
||||
|
||||
|
||||
class TestHuggingfaceDownloadMonitorFileSize:
|
||||
def _make_monitor(self, tmp_path):
|
||||
model_root = str(tmp_path / "models--test" / "snapshots" / "abc")
|
||||
os.makedirs(model_root, exist_ok=True)
|
||||
progress = MagicMock()
|
||||
progress.emit = MagicMock()
|
||||
monitor = HuggingfaceDownloadMonitor(
|
||||
model_root=model_root,
|
||||
progress=progress,
|
||||
total_file_size=100 * 1024 * 1024
|
||||
)
|
||||
return monitor
|
||||
|
||||
def test_emits_progress_for_tmp_files(self, tmp_path):
|
||||
from buzz.model_loader import model_root_dir as orig_root
|
||||
monitor = self._make_monitor(tmp_path)
|
||||
|
||||
# Create a tmp file in model_root_dir
|
||||
with patch('buzz.model_loader.model_root_dir', str(tmp_path)):
|
||||
tmp_file = tmp_path / "tmpXYZ123"
|
||||
tmp_file.write_bytes(b"x" * 1024)
|
||||
|
||||
monitor.stop_event.clear()
|
||||
# Run one iteration
|
||||
monitor.monitor_file_size.__func__ if hasattr(monitor.monitor_file_size, '__func__') else None
|
||||
|
||||
# Manually call internal logic once
|
||||
emitted = []
|
||||
original_emit = monitor.progress.emit
|
||||
monitor.progress.emit = lambda x: emitted.append(x)
|
||||
|
||||
import buzz.model_loader as ml
|
||||
old_root = ml.model_root_dir
|
||||
ml.model_root_dir = str(tmp_path)
|
||||
try:
|
||||
monitor.stop_event.set() # stop after one iteration
|
||||
monitor.stop_event.clear()
|
||||
# call once manually by running the loop body
|
||||
for filename in os.listdir(str(tmp_path)):
|
||||
if filename.startswith("tmp"):
|
||||
file_size = os.path.getsize(os.path.join(str(tmp_path), filename))
|
||||
monitor.progress.emit((file_size, monitor.total_file_size))
|
||||
assert len(emitted) > 0
|
||||
assert emitted[0][0] == 1024
|
||||
finally:
|
||||
ml.model_root_dir = old_root
|
||||
|
||||
def test_emits_progress_for_incomplete_files(self, tmp_path):
|
||||
monitor = self._make_monitor(tmp_path)
|
||||
|
||||
blobs_dir = tmp_path / "blobs"
|
||||
blobs_dir.mkdir()
|
||||
incomplete_file = blobs_dir / "somefile.incomplete"
|
||||
incomplete_file.write_bytes(b"y" * 2048)
|
||||
|
||||
emitted = []
|
||||
monitor.incomplete_download_root = str(blobs_dir)
|
||||
monitor.progress.emit = lambda x: emitted.append(x)
|
||||
|
||||
for filename in os.listdir(str(blobs_dir)):
|
||||
if filename.endswith(".incomplete"):
|
||||
file_size = os.path.getsize(os.path.join(str(blobs_dir), filename))
|
||||
monitor.progress.emit((file_size, monitor.total_file_size))
|
||||
|
||||
assert len(emitted) > 0
|
||||
assert emitted[0][0] == 2048
|
||||
|
||||
def test_stop_monitoring_emits_100_percent(self, tmp_path):
|
||||
monitor = self._make_monitor(tmp_path)
|
||||
monitor.monitor_thread = MagicMock()
|
||||
monitor.stop_monitoring()
|
||||
monitor.progress.emit.assert_called_with(
|
||||
(monitor.total_file_size, monitor.total_file_size)
|
||||
)
|
||||
|
||||
|
||||
class TestModelDownloaderDownloadModel:
|
||||
def _make_downloader(self, model):
|
||||
downloader = ModelDownloader(model=model)
|
||||
downloader.signals = MagicMock()
|
||||
downloader.signals.progress = MagicMock()
|
||||
downloader.signals.progress.emit = MagicMock()
|
||||
return downloader
|
||||
|
||||
def test_download_model_fresh_success(self, tmp_path):
|
||||
model = TranscriptionModel(model_type=ModelType.WHISPER, whisper_model_size=WhisperModelSize.TINY)
|
||||
downloader = self._make_downloader(model)
|
||||
|
||||
file_path = str(tmp_path / "model.pt")
|
||||
fake_content = b"fake model data" * 100
|
||||
|
||||
mock_response = MagicMock()
|
||||
mock_response.__enter__ = lambda s: s
|
||||
mock_response.__exit__ = MagicMock(return_value=False)
|
||||
mock_response.status_code = 200
|
||||
mock_response.headers = {"Content-Length": str(len(fake_content))}
|
||||
mock_response.iter_content = MagicMock(return_value=[fake_content])
|
||||
mock_response.raise_for_status = MagicMock()
|
||||
|
||||
with patch('requests.get', return_value=mock_response), \
|
||||
patch('requests.head') as mock_head:
|
||||
result = downloader.download_model(url="http://example.com/model.pt", file_path=file_path, expected_sha256=None)
|
||||
|
||||
assert result is True
|
||||
assert os.path.exists(file_path)
|
||||
assert open(file_path, 'rb').read() == fake_content
|
||||
|
||||
def test_download_model_already_downloaded_sha256_match(self, tmp_path):
|
||||
import hashlib
|
||||
content = b"complete model content"
|
||||
sha256 = hashlib.sha256(content).hexdigest()
|
||||
model_file = tmp_path / "model.pt"
|
||||
model_file.write_bytes(content)
|
||||
|
||||
model = TranscriptionModel(model_type=ModelType.WHISPER, whisper_model_size=WhisperModelSize.TINY)
|
||||
downloader = self._make_downloader(model)
|
||||
|
||||
mock_head = MagicMock()
|
||||
mock_head.headers = {"Content-Length": str(len(content)), "Accept-Ranges": "bytes"}
|
||||
mock_head.raise_for_status = MagicMock()
|
||||
|
||||
with patch('requests.head', return_value=mock_head):
|
||||
result = downloader.download_model(
|
||||
url="http://example.com/model.pt",
|
||||
file_path=str(model_file),
|
||||
expected_sha256=sha256
|
||||
)
|
||||
|
||||
assert result is True
|
||||
|
||||
def test_download_model_sha256_mismatch_redownloads(self, tmp_path):
|
||||
import hashlib
|
||||
content = b"complete model content"
|
||||
bad_sha256 = "0" * 64
|
||||
model_file = tmp_path / "model.pt"
|
||||
model_file.write_bytes(content)
|
||||
|
||||
model = TranscriptionModel(model_type=ModelType.WHISPER, whisper_model_size=WhisperModelSize.TINY)
|
||||
downloader = self._make_downloader(model)
|
||||
|
||||
new_content = b"new model data"
|
||||
mock_head = MagicMock()
|
||||
mock_head.headers = {"Content-Length": str(len(content)), "Accept-Ranges": "bytes"}
|
||||
mock_head.raise_for_status = MagicMock()
|
||||
|
||||
mock_response = MagicMock()
|
||||
mock_response.__enter__ = lambda s: s
|
||||
mock_response.__exit__ = MagicMock(return_value=False)
|
||||
mock_response.status_code = 200
|
||||
mock_response.headers = {"Content-Length": str(len(new_content))}
|
||||
mock_response.iter_content = MagicMock(return_value=[new_content])
|
||||
mock_response.raise_for_status = MagicMock()
|
||||
|
||||
with patch('requests.head', return_value=mock_head), \
|
||||
patch('requests.get', return_value=mock_response):
|
||||
with pytest.raises(RuntimeError, match="SHA256 checksum does not match"):
|
||||
downloader.download_model(
|
||||
url="http://example.com/model.pt",
|
||||
file_path=str(model_file),
|
||||
expected_sha256=bad_sha256
|
||||
)
|
||||
|
||||
# File is deleted after SHA256 mismatch
|
||||
assert not model_file.exists()
|
||||
|
||||
def test_download_model_stopped_mid_download(self, tmp_path):
|
||||
model = TranscriptionModel(model_type=ModelType.WHISPER, whisper_model_size=WhisperModelSize.TINY)
|
||||
downloader = self._make_downloader(model)
|
||||
downloader.stopped = True
|
||||
|
||||
file_path = str(tmp_path / "model.pt")
|
||||
|
||||
def iter_content_gen(chunk_size):
|
||||
yield b"chunk1"
|
||||
|
||||
mock_response = MagicMock()
|
||||
mock_response.__enter__ = lambda s: s
|
||||
mock_response.__exit__ = MagicMock(return_value=False)
|
||||
mock_response.status_code = 200
|
||||
mock_response.headers = {"Content-Length": "6"}
|
||||
mock_response.iter_content = iter_content_gen
|
||||
mock_response.raise_for_status = MagicMock()
|
||||
|
||||
with patch('requests.get', return_value=mock_response):
|
||||
result = downloader.download_model(
|
||||
url="http://example.com/model.pt",
|
||||
file_path=file_path,
|
||||
expected_sha256=None
|
||||
)
|
||||
|
||||
assert result is False
|
||||
|
||||
def test_download_model_resumes_partial(self, tmp_path):
|
||||
model = TranscriptionModel(model_type=ModelType.WHISPER, whisper_model_size=WhisperModelSize.TINY)
|
||||
downloader = self._make_downloader(model)
|
||||
|
||||
existing_content = b"partial"
|
||||
model_file = tmp_path / "model.pt"
|
||||
model_file.write_bytes(existing_content)
|
||||
resume_content = b" completed"
|
||||
total_size = len(existing_content) + len(resume_content)
|
||||
|
||||
mock_head_size = MagicMock()
|
||||
mock_head_size.headers = {"Content-Length": str(total_size), "Accept-Ranges": "bytes"}
|
||||
mock_head_size.raise_for_status = MagicMock()
|
||||
|
||||
mock_head_range = MagicMock()
|
||||
mock_head_range.headers = {"Accept-Ranges": "bytes"}
|
||||
mock_head_range.raise_for_status = MagicMock()
|
||||
|
||||
mock_response = MagicMock()
|
||||
mock_response.__enter__ = lambda s: s
|
||||
mock_response.__exit__ = MagicMock(return_value=False)
|
||||
mock_response.status_code = 206
|
||||
mock_response.headers = {
|
||||
"Content-Range": f"bytes {len(existing_content)}-{total_size - 1}/{total_size}",
|
||||
"Content-Length": str(len(resume_content))
|
||||
}
|
||||
mock_response.iter_content = MagicMock(return_value=[resume_content])
|
||||
mock_response.raise_for_status = MagicMock()
|
||||
|
||||
with patch('requests.head', side_effect=[mock_head_size, mock_head_range]), \
|
||||
patch('requests.get', return_value=mock_response):
|
||||
result = downloader.download_model(
|
||||
url="http://example.com/model.pt",
|
||||
file_path=str(model_file),
|
||||
expected_sha256=None
|
||||
)
|
||||
|
||||
assert result is True
|
||||
assert open(str(model_file), 'rb').read() == existing_content + resume_content
|
||||
|
||||
|
||||
class TestModelDownloaderWhisperCpp:
|
||||
def _make_downloader(self, model, custom_url=None):
|
||||
downloader = ModelDownloader(model=model, custom_model_url=custom_url)
|
||||
downloader.signals = MagicMock()
|
||||
downloader.signals.progress = MagicMock()
|
||||
downloader.signals.finished = MagicMock()
|
||||
downloader.signals.error = MagicMock()
|
||||
return downloader
|
||||
|
||||
def test_standard_model_calls_download_from_huggingface(self):
|
||||
model = TranscriptionModel(
|
||||
model_type=ModelType.WHISPER_CPP,
|
||||
whisper_model_size=WhisperModelSize.TINY,
|
||||
)
|
||||
downloader = self._make_downloader(model)
|
||||
model_name = WhisperModelSize.TINY.to_whisper_cpp_model_size()
|
||||
|
||||
with patch("buzz.model_loader.download_from_huggingface", return_value="/fake/path") as mock_dl, \
|
||||
patch.object(downloader, "is_coreml_supported", False):
|
||||
downloader.run()
|
||||
|
||||
mock_dl.assert_called_once_with(
|
||||
repo_id=WHISPER_CPP_REPO_ID,
|
||||
allow_patterns=[f"ggml-{model_name}.bin", "README.md"],
|
||||
progress=downloader.signals.progress,
|
||||
num_large_files=1,
|
||||
)
|
||||
downloader.signals.finished.emit.assert_called_once_with(
|
||||
os.path.join("/fake/path", f"ggml-{model_name}.bin")
|
||||
)
|
||||
|
||||
def test_lumii_model_uses_lumii_repo(self):
|
||||
model = TranscriptionModel(
|
||||
model_type=ModelType.WHISPER_CPP,
|
||||
whisper_model_size=WhisperModelSize.LUMII,
|
||||
)
|
||||
downloader = self._make_downloader(model)
|
||||
model_name = WhisperModelSize.LUMII.to_whisper_cpp_model_size()
|
||||
|
||||
with patch("buzz.model_loader.download_from_huggingface", return_value="/lumii/path") as mock_dl, \
|
||||
patch.object(downloader, "is_coreml_supported", False):
|
||||
downloader.run()
|
||||
|
||||
mock_dl.assert_called_once()
|
||||
assert mock_dl.call_args.kwargs["repo_id"] == WHISPER_CPP_LUMII_REPO_ID
|
||||
downloader.signals.finished.emit.assert_called_once_with(
|
||||
os.path.join("/lumii/path", f"ggml-{model_name}.bin")
|
||||
)
|
||||
|
||||
def test_custom_url_calls_download_model_to_path(self):
|
||||
model = TranscriptionModel(
|
||||
model_type=ModelType.WHISPER_CPP,
|
||||
whisper_model_size=WhisperModelSize.TINY,
|
||||
)
|
||||
custom_url = "https://example.com/my-model.bin"
|
||||
downloader = self._make_downloader(model, custom_url=custom_url)
|
||||
|
||||
with patch.object(downloader, "download_model_to_path") as mock_dtp:
|
||||
downloader.run()
|
||||
|
||||
mock_dtp.assert_called_once()
|
||||
call_kwargs = mock_dtp.call_args.kwargs
|
||||
assert call_kwargs["url"] == custom_url
|
||||
|
||||
def test_coreml_model_includes_mlmodelc_in_file_list(self):
|
||||
model = TranscriptionModel(
|
||||
model_type=ModelType.WHISPER_CPP,
|
||||
whisper_model_size=WhisperModelSize.TINY,
|
||||
)
|
||||
downloader = self._make_downloader(model)
|
||||
model_name = WhisperModelSize.TINY.to_whisper_cpp_model_size()
|
||||
|
||||
with patch("buzz.model_loader.download_from_huggingface", return_value="/fake/path") as mock_dl, \
|
||||
patch.object(downloader, "is_coreml_supported", True), \
|
||||
patch("zipfile.ZipFile"), \
|
||||
patch("shutil.rmtree"), \
|
||||
patch("shutil.move"), \
|
||||
patch("os.path.exists", return_value=False), \
|
||||
patch("os.listdir", return_value=[f"ggml-{model_name}-encoder.mlmodelc"]), \
|
||||
patch("os.path.isdir", return_value=True):
|
||||
downloader.run()
|
||||
|
||||
mock_dl.assert_called_once()
|
||||
assert mock_dl.call_args.kwargs["num_large_files"] == 2
|
||||
allow_patterns = mock_dl.call_args.kwargs["allow_patterns"]
|
||||
assert f"ggml-{model_name}-encoder.mlmodelc.zip" in allow_patterns
|
||||
|
||||
def test_coreml_zip_extracted_and_existing_dir_removed(self, tmp_path):
|
||||
model = TranscriptionModel(
|
||||
model_type=ModelType.WHISPER_CPP,
|
||||
whisper_model_size=WhisperModelSize.TINY,
|
||||
)
|
||||
downloader = self._make_downloader(model)
|
||||
model_name = WhisperModelSize.TINY.to_whisper_cpp_model_size()
|
||||
|
||||
# Create a fake zip with a single top-level directory inside
|
||||
import zipfile as zf
|
||||
zip_path = tmp_path / f"ggml-{model_name}-encoder.mlmodelc.zip"
|
||||
nested_dir = f"ggml-{model_name}-encoder.mlmodelc"
|
||||
with zf.ZipFile(zip_path, "w") as z:
|
||||
z.writestr(f"{nested_dir}/weights", b"fake weights")
|
||||
|
||||
existing_target = tmp_path / f"ggml-{model_name}-encoder.mlmodelc"
|
||||
existing_target.mkdir()
|
||||
|
||||
with patch("buzz.model_loader.download_from_huggingface", return_value=str(tmp_path)), \
|
||||
patch.object(downloader, "is_coreml_supported", True):
|
||||
downloader.run()
|
||||
|
||||
# Old directory was removed and recreated from zip
|
||||
assert existing_target.exists()
|
||||
downloader.signals.finished.emit.assert_called_once_with(
|
||||
str(tmp_path / f"ggml-{model_name}.bin")
|
||||
)
|
||||
|
||||
|
||||
class TestModelLoaderCertifiImportError:
|
||||
def test_certifi_import_error_path(self):
|
||||
"""Test that module handles certifi ImportError gracefully by reimporting with mock"""
|
||||
import importlib
|
||||
import buzz.model_loader as ml
|
||||
|
||||
# The module already imported; we just verify _certifi_ca_bundle exists
|
||||
# (either as a path or None from ImportError)
|
||||
assert hasattr(ml, '_certifi_ca_bundle')
|
||||
|
||||
def test_configure_http_backend_import_error(self):
|
||||
"""Test configure_http_backend handles ImportError gracefully"""
|
||||
# Simulate the ImportError branch by calling directly
|
||||
import requests
|
||||
# If configure_http_backend was not available, the module would still load
|
||||
import buzz.model_loader as ml
|
||||
assert ml is not None
|
||||
|
|
|
|||
|
|
@ -1,115 +0,0 @@
|
|||
import numpy as np
|
||||
import pytest
|
||||
from unittest.mock import MagicMock, patch
|
||||
|
||||
from buzz.recording import RecordingAmplitudeListener
|
||||
|
||||
|
||||
class TestRecordingAmplitudeListenerInit:
|
||||
def test_initial_buffer_is_empty(self):
|
||||
# np.ndarray([], dtype=np.float32) produces a 0-d array with size 1;
|
||||
# "empty" here means no audio data has been accumulated yet.
|
||||
listener = RecordingAmplitudeListener(input_device_index=None)
|
||||
assert listener.buffer.ndim == 0
|
||||
|
||||
def test_initial_accumulation_size_is_zero(self):
|
||||
listener = RecordingAmplitudeListener(input_device_index=None)
|
||||
assert listener.accumulation_size == 0
|
||||
|
||||
|
||||
class TestRecordingAmplitudeListenerStreamCallback:
|
||||
def _make_listener(self) -> RecordingAmplitudeListener:
|
||||
listener = RecordingAmplitudeListener(input_device_index=None)
|
||||
listener.accumulation_size = 10 # small size for testing
|
||||
return listener
|
||||
|
||||
def test_emits_amplitude_changed(self):
|
||||
listener = self._make_listener()
|
||||
emitted = []
|
||||
listener.amplitude_changed.connect(lambda v: emitted.append(v))
|
||||
|
||||
chunk = np.array([[0.5], [0.5]], dtype=np.float32)
|
||||
listener.stream_callback(chunk, 2, None, None)
|
||||
|
||||
assert len(emitted) == 1
|
||||
assert emitted[0] > 0
|
||||
|
||||
def test_amplitude_is_rms(self):
|
||||
listener = self._make_listener()
|
||||
emitted = []
|
||||
listener.amplitude_changed.connect(lambda v: emitted.append(v))
|
||||
|
||||
chunk = np.array([[1.0], [1.0]], dtype=np.float32)
|
||||
listener.stream_callback(chunk, 2, None, None)
|
||||
|
||||
assert abs(emitted[0] - 1.0) < 1e-6
|
||||
|
||||
def test_accumulates_buffer(self):
|
||||
listener = self._make_listener()
|
||||
size_before = listener.buffer.size
|
||||
chunk = np.array([[0.1]] * 4, dtype=np.float32)
|
||||
listener.stream_callback(chunk, 4, None, None)
|
||||
assert listener.buffer.size == size_before + 4
|
||||
|
||||
def test_emits_average_amplitude_when_buffer_full(self):
|
||||
listener = self._make_listener()
|
||||
# accumulation_size must be <= initial_size + chunk_size to trigger emission
|
||||
chunk = np.array([[0.5]] * 4, dtype=np.float32)
|
||||
listener.accumulation_size = listener.buffer.size + len(chunk)
|
||||
|
||||
averages = []
|
||||
listener.average_amplitude_changed.connect(lambda v: averages.append(v))
|
||||
listener.stream_callback(chunk, len(chunk), None, None)
|
||||
|
||||
assert len(averages) == 1
|
||||
assert averages[0] > 0
|
||||
|
||||
def test_resets_buffer_after_emitting_average(self):
|
||||
listener = self._make_listener()
|
||||
chunk = np.array([[0.5]] * 4, dtype=np.float32)
|
||||
listener.accumulation_size = listener.buffer.size + len(chunk)
|
||||
|
||||
listener.stream_callback(chunk, len(chunk), None, None)
|
||||
|
||||
# Buffer is reset to np.ndarray([], ...) — a 0-d array
|
||||
assert listener.buffer.ndim == 0
|
||||
|
||||
def test_does_not_emit_average_before_buffer_full(self):
|
||||
listener = self._make_listener()
|
||||
chunk = np.array([[0.5]] * 4, dtype=np.float32)
|
||||
# Set accumulation_size larger than initial + chunk so it never triggers
|
||||
listener.accumulation_size = listener.buffer.size + len(chunk) + 1
|
||||
|
||||
averages = []
|
||||
listener.average_amplitude_changed.connect(lambda v: averages.append(v))
|
||||
listener.stream_callback(chunk, len(chunk), None, None)
|
||||
|
||||
assert len(averages) == 0
|
||||
|
||||
def test_average_amplitude_is_rms_of_accumulated_buffer(self):
|
||||
listener = self._make_listener()
|
||||
|
||||
# Two callbacks of 4 samples each; trigger on second callback
|
||||
chunk = np.array([[1.0], [1.0], [1.0], [1.0]], dtype=np.float32)
|
||||
listener.accumulation_size = listener.buffer.size + len(chunk)
|
||||
|
||||
averages = []
|
||||
listener.average_amplitude_changed.connect(lambda v: averages.append(v))
|
||||
listener.stream_callback(chunk, len(chunk), None, None)
|
||||
|
||||
assert len(averages) == 1
|
||||
# All samples are 1.0, so RMS must be 1.0 (initial uninitialized byte is negligible)
|
||||
assert averages[0] > 0
|
||||
|
||||
|
||||
class TestRecordingAmplitudeListenerStart:
|
||||
def test_accumulation_size_set_from_sample_rate(self):
|
||||
listener = RecordingAmplitudeListener(input_device_index=None)
|
||||
|
||||
mock_stream = MagicMock()
|
||||
mock_stream.samplerate = 16000
|
||||
|
||||
with patch("sounddevice.InputStream", return_value=mock_stream):
|
||||
listener.start_recording()
|
||||
|
||||
assert listener.accumulation_size == 16000 * RecordingAmplitudeListener.ACCUMULATION_SECONDS
|
||||
|
|
@ -1,298 +0,0 @@
|
|||
import threading
|
||||
from unittest.mock import MagicMock, patch, PropertyMock
|
||||
|
||||
import numpy as np
|
||||
import pytest
|
||||
from sounddevice import PortAudioError
|
||||
|
||||
from buzz.model_loader import TranscriptionModel, ModelType, WhisperModelSize
|
||||
from buzz.settings.recording_transcriber_mode import RecordingTranscriberMode
|
||||
from buzz.transcriber.recording_transcriber import RecordingTranscriber
|
||||
from buzz.transcriber.transcriber import TranscriptionOptions, Task
|
||||
|
||||
|
||||
def make_transcriber(
|
||||
model_type=ModelType.WHISPER,
|
||||
mode_index=0,
|
||||
silence_threshold=0.0,
|
||||
language=None,
|
||||
) -> RecordingTranscriber:
|
||||
options = TranscriptionOptions(
|
||||
language=language,
|
||||
task=Task.TRANSCRIBE,
|
||||
model=TranscriptionModel(model_type=model_type, whisper_model_size=WhisperModelSize.TINY),
|
||||
silence_threshold=silence_threshold,
|
||||
)
|
||||
mock_sounddevice = MagicMock()
|
||||
|
||||
with patch("buzz.transcriber.recording_transcriber.Settings") as MockSettings:
|
||||
instance = MockSettings.return_value
|
||||
instance.value.return_value = mode_index
|
||||
transcriber = RecordingTranscriber(
|
||||
transcription_options=options,
|
||||
input_device_index=None,
|
||||
sample_rate=16000,
|
||||
model_path="tiny",
|
||||
sounddevice=mock_sounddevice,
|
||||
)
|
||||
return transcriber
|
||||
|
||||
|
||||
class TestRecordingTranscriberInit:
|
||||
def test_default_batch_size_is_5_seconds(self):
|
||||
t = make_transcriber(mode_index=0)
|
||||
assert t.n_batch_samples == 5 * t.sample_rate
|
||||
|
||||
def test_append_and_correct_mode_batch_size_uses_transcription_step(self):
|
||||
mode_index = list(RecordingTranscriberMode).index(RecordingTranscriberMode.APPEND_AND_CORRECT)
|
||||
t = make_transcriber(mode_index=mode_index)
|
||||
assert t.n_batch_samples == int(t.transcription_options.transcription_step * t.sample_rate)
|
||||
|
||||
def test_append_and_correct_mode_keep_sample_seconds(self):
|
||||
mode_index = list(RecordingTranscriberMode).index(RecordingTranscriberMode.APPEND_AND_CORRECT)
|
||||
t = make_transcriber(mode_index=mode_index)
|
||||
assert t.keep_sample_seconds == 1.5
|
||||
|
||||
def test_default_keep_sample_seconds(self):
|
||||
t = make_transcriber(mode_index=0)
|
||||
assert t.keep_sample_seconds == 0.15
|
||||
|
||||
def test_queue_starts_empty(self):
|
||||
t = make_transcriber()
|
||||
assert t.queue.size == 0 or t.queue.ndim == 0
|
||||
|
||||
def test_max_queue_size_is_three_batches(self):
|
||||
t = make_transcriber()
|
||||
assert t.max_queue_size == 3 * t.n_batch_samples
|
||||
|
||||
|
||||
class TestAmplitude:
|
||||
def test_silence_returns_zero(self):
|
||||
arr = np.zeros(100, dtype=np.float32)
|
||||
assert RecordingTranscriber.amplitude(arr) == 0.0
|
||||
|
||||
def test_unit_signal_returns_one(self):
|
||||
arr = np.ones(100, dtype=np.float32)
|
||||
assert abs(RecordingTranscriber.amplitude(arr) - 1.0) < 1e-6
|
||||
|
||||
def test_rms_calculation(self):
|
||||
arr = np.array([0.6, 0.8], dtype=np.float32)
|
||||
expected = float(np.sqrt(np.mean(arr ** 2)))
|
||||
assert abs(RecordingTranscriber.amplitude(arr) - expected) < 1e-6
|
||||
|
||||
|
||||
class TestStreamCallback:
|
||||
def test_emits_amplitude_changed(self):
|
||||
t = make_transcriber()
|
||||
emitted = []
|
||||
t.amplitude_changed.connect(lambda v: emitted.append(v))
|
||||
|
||||
chunk = np.array([[0.5], [0.5]], dtype=np.float32)
|
||||
t.stream_callback(chunk, 2, None, None)
|
||||
|
||||
assert len(emitted) == 1
|
||||
|
||||
def test_appends_to_queue_when_not_full(self):
|
||||
t = make_transcriber()
|
||||
initial_size = t.queue.size
|
||||
chunk = np.ones((100,), dtype=np.float32)
|
||||
t.stream_callback(chunk.reshape(-1, 1), 100, None, None)
|
||||
assert t.queue.size == initial_size + 100
|
||||
|
||||
def test_drops_chunk_when_queue_full(self):
|
||||
t = make_transcriber()
|
||||
# Fill the queue to max capacity
|
||||
t.queue = np.ones(t.max_queue_size, dtype=np.float32)
|
||||
size_before = t.queue.size
|
||||
|
||||
chunk = np.array([[0.5], [0.5]], dtype=np.float32)
|
||||
t.stream_callback(chunk, 2, None, None)
|
||||
|
||||
assert t.queue.size == size_before # chunk was dropped
|
||||
|
||||
def test_thread_safety_with_concurrent_callbacks(self):
|
||||
t = make_transcriber()
|
||||
errors = []
|
||||
|
||||
def callback():
|
||||
try:
|
||||
chunk = np.ones((10, 1), dtype=np.float32)
|
||||
t.stream_callback(chunk, 10, None, None)
|
||||
except Exception as e:
|
||||
errors.append(e)
|
||||
|
||||
threads = [threading.Thread(target=callback) for _ in range(20)]
|
||||
for th in threads:
|
||||
th.start()
|
||||
for th in threads:
|
||||
th.join()
|
||||
|
||||
assert errors == []
|
||||
|
||||
|
||||
class TestGetDeviceSampleRate:
|
||||
def test_returns_whisper_sample_rate_when_supported(self):
|
||||
with patch("sounddevice.check_input_settings"):
|
||||
rate = RecordingTranscriber.get_device_sample_rate(None)
|
||||
assert rate == 16000
|
||||
|
||||
def test_falls_back_to_device_default_sample_rate(self):
|
||||
with patch("sounddevice.check_input_settings", side_effect=PortAudioError()), \
|
||||
patch("sounddevice.query_devices", return_value={"default_samplerate": 44100.0}):
|
||||
rate = RecordingTranscriber.get_device_sample_rate(None)
|
||||
assert rate == 44100
|
||||
|
||||
def test_falls_back_to_whisper_rate_when_query_returns_non_dict(self):
|
||||
with patch("sounddevice.check_input_settings", side_effect=PortAudioError()), \
|
||||
patch("sounddevice.query_devices", return_value=None):
|
||||
rate = RecordingTranscriber.get_device_sample_rate(None)
|
||||
assert rate == 16000
|
||||
|
||||
|
||||
class TestStopRecording:
|
||||
def test_sets_is_running_false(self):
|
||||
t = make_transcriber()
|
||||
t.is_running = True
|
||||
t.stop_recording()
|
||||
assert t.is_running is False
|
||||
|
||||
def test_terminates_running_process(self):
|
||||
t = make_transcriber()
|
||||
mock_process = MagicMock()
|
||||
mock_process.poll.return_value = None # process is running
|
||||
t.process = mock_process
|
||||
|
||||
t.stop_recording()
|
||||
|
||||
mock_process.terminate.assert_called_once()
|
||||
|
||||
def test_kills_process_on_timeout(self):
|
||||
import subprocess
|
||||
t = make_transcriber()
|
||||
mock_process = MagicMock()
|
||||
mock_process.poll.return_value = None
|
||||
mock_process.wait.side_effect = subprocess.TimeoutExpired(cmd="test", timeout=5)
|
||||
t.process = mock_process
|
||||
|
||||
t.stop_recording()
|
||||
|
||||
mock_process.kill.assert_called_once()
|
||||
|
||||
def test_skips_terminate_when_process_already_stopped(self):
|
||||
t = make_transcriber()
|
||||
mock_process = MagicMock()
|
||||
mock_process.poll.return_value = 0 # already exited
|
||||
t.process = mock_process
|
||||
|
||||
t.stop_recording()
|
||||
|
||||
mock_process.terminate.assert_not_called()
|
||||
|
||||
|
||||
class TestStartWithSilence:
|
||||
"""Tests for the main transcription loop with silence threshold."""
|
||||
|
||||
def _run_with_mock_model(self, transcription_options, samples, expected_text):
|
||||
"""Helper to run a single transcription cycle with a mocked whisper model."""
|
||||
mock_model = MagicMock()
|
||||
mock_model.transcribe.return_value = {"text": expected_text}
|
||||
|
||||
transcriber = make_transcriber(
|
||||
model_type=ModelType.WHISPER,
|
||||
silence_threshold=0.0,
|
||||
)
|
||||
transcriber.transcription_options = transcription_options
|
||||
|
||||
received = []
|
||||
transcriber.transcription.connect(lambda t: received.append(t))
|
||||
|
||||
def fake_input_stream(**kwargs):
|
||||
ctx = MagicMock()
|
||||
ctx.__enter__ = MagicMock(return_value=ctx)
|
||||
ctx.__exit__ = MagicMock(return_value=False)
|
||||
return ctx
|
||||
|
||||
transcriber.queue = samples.copy()
|
||||
transcriber.is_running = True
|
||||
|
||||
# After processing one batch, stop.
|
||||
call_count = [0]
|
||||
original_emit = transcriber.transcription.emit
|
||||
|
||||
def stop_after_first(text):
|
||||
original_emit(text)
|
||||
transcriber.is_running = False
|
||||
|
||||
transcriber.transcription.emit = stop_after_first
|
||||
|
||||
with patch("buzz.transcriber.recording_transcriber.whisper") as mock_whisper, \
|
||||
patch("buzz.transcriber.recording_transcriber.torch") as mock_torch:
|
||||
mock_torch.cuda.is_available.return_value = False
|
||||
mock_whisper.load_model.return_value = mock_model
|
||||
mock_whisper.Whisper = type("Whisper", (), {})
|
||||
# make isinstance(model, whisper.Whisper) pass
|
||||
mock_model.__class__ = mock_whisper.Whisper
|
||||
|
||||
with patch.object(transcriber, "sounddevice") as mock_sd:
|
||||
mock_stream_ctx = MagicMock()
|
||||
mock_stream_ctx.__enter__ = MagicMock(return_value=mock_stream_ctx)
|
||||
mock_stream_ctx.__exit__ = MagicMock(return_value=False)
|
||||
mock_sd.InputStream.return_value = mock_stream_ctx
|
||||
|
||||
transcriber.start()
|
||||
|
||||
return received
|
||||
|
||||
def test_silent_audio_skips_transcription(self):
|
||||
t = make_transcriber(silence_threshold=1.0) # very high threshold
|
||||
|
||||
received = []
|
||||
t.transcription.connect(lambda text: received.append(text))
|
||||
|
||||
# Put silent samples in queue (amplitude = 0)
|
||||
t.queue = np.zeros(t.n_batch_samples + 100, dtype=np.float32)
|
||||
t.is_running = True
|
||||
|
||||
stop_event = threading.Event()
|
||||
|
||||
def stop_after_delay():
|
||||
stop_event.wait(timeout=1.5)
|
||||
t.stop_recording()
|
||||
|
||||
stopper = threading.Thread(target=stop_after_delay, daemon=True)
|
||||
|
||||
with patch("buzz.transcriber.recording_transcriber.whisper") as mock_whisper, \
|
||||
patch("buzz.transcriber.recording_transcriber.torch") as mock_torch:
|
||||
mock_torch.cuda.is_available.return_value = False
|
||||
mock_whisper.load_model.return_value = MagicMock()
|
||||
|
||||
with patch.object(t, "sounddevice") as mock_sd:
|
||||
mock_stream_ctx = MagicMock()
|
||||
mock_stream_ctx.__enter__ = MagicMock(return_value=mock_stream_ctx)
|
||||
mock_stream_ctx.__exit__ = MagicMock(return_value=False)
|
||||
mock_sd.InputStream.return_value = mock_stream_ctx
|
||||
|
||||
stopper.start()
|
||||
stop_event.set()
|
||||
t.start()
|
||||
|
||||
# No transcription should have been emitted since audio is silent
|
||||
assert received == []
|
||||
|
||||
|
||||
class TestStartPortAudioError:
|
||||
def test_emits_error_on_portaudio_failure(self):
|
||||
t = make_transcriber()
|
||||
errors = []
|
||||
t.error.connect(lambda e: errors.append(e))
|
||||
|
||||
with patch("buzz.transcriber.recording_transcriber.whisper") as mock_whisper, \
|
||||
patch("buzz.transcriber.recording_transcriber.torch") as mock_torch:
|
||||
mock_torch.cuda.is_available.return_value = False
|
||||
mock_whisper.load_model.return_value = MagicMock()
|
||||
|
||||
with patch.object(t, "sounddevice") as mock_sd:
|
||||
mock_sd.InputStream.side_effect = PortAudioError()
|
||||
t.start()
|
||||
|
||||
assert len(errors) == 1
|
||||
|
|
@ -1,10 +1,9 @@
|
|||
import pytest
|
||||
import unittest.mock
|
||||
import uuid
|
||||
from PyQt6.QtCore import QCoreApplication, QThread
|
||||
from buzz.file_transcriber_queue_worker import FileTranscriberQueueWorker
|
||||
from buzz.model_loader import ModelType, TranscriptionModel, WhisperModelSize
|
||||
from buzz.transcriber.transcriber import FileTranscriptionTask, TranscriptionOptions, FileTranscriptionOptions, Segment
|
||||
from buzz.transcriber.transcriber import FileTranscriptionTask, TranscriptionOptions, FileTranscriptionOptions
|
||||
from buzz.transcriber.whisper_file_transcriber import WhisperFileTranscriber
|
||||
from tests.audio import test_multibyte_utf8_audio_path
|
||||
import time
|
||||
|
|
@ -32,310 +31,6 @@ def worker(qapp):
|
|||
thread.wait()
|
||||
|
||||
|
||||
@pytest.fixture
|
||||
def simple_worker(qapp):
|
||||
"""A non-threaded worker for unit tests that only test individual methods."""
|
||||
worker = FileTranscriberQueueWorker()
|
||||
yield worker
|
||||
|
||||
|
||||
class TestFileTranscriberQueueWorker:
|
||||
def test_cancel_task_adds_to_canceled_set(self, simple_worker):
|
||||
task_id = uuid.uuid4()
|
||||
simple_worker.cancel_task(task_id)
|
||||
assert task_id in simple_worker.canceled_tasks
|
||||
|
||||
def test_add_task_removes_from_canceled(self, simple_worker):
|
||||
options = TranscriptionOptions(
|
||||
model=TranscriptionModel(model_type=ModelType.WHISPER_CPP, whisper_model_size=WhisperModelSize.TINY),
|
||||
extract_speech=False
|
||||
)
|
||||
task = FileTranscriptionTask(
|
||||
file_path=str(test_multibyte_utf8_audio_path),
|
||||
transcription_options=options,
|
||||
file_transcription_options=FileTranscriptionOptions(),
|
||||
model_path="mock_path"
|
||||
)
|
||||
|
||||
# First cancel it
|
||||
simple_worker.cancel_task(task.uid)
|
||||
assert task.uid in simple_worker.canceled_tasks
|
||||
|
||||
# Prevent trigger_run from starting the run loop
|
||||
simple_worker.is_running = True
|
||||
# Then add it back
|
||||
simple_worker.add_task(task)
|
||||
assert task.uid not in simple_worker.canceled_tasks
|
||||
|
||||
def test_on_task_error_with_cancellation(self, simple_worker):
|
||||
options = TranscriptionOptions()
|
||||
task = FileTranscriptionTask(
|
||||
file_path=str(test_multibyte_utf8_audio_path),
|
||||
transcription_options=options,
|
||||
file_transcription_options=FileTranscriptionOptions(),
|
||||
model_path="mock_path"
|
||||
)
|
||||
simple_worker.current_task = task
|
||||
|
||||
error_spy = unittest.mock.Mock()
|
||||
simple_worker.task_error.connect(error_spy)
|
||||
|
||||
simple_worker.on_task_error("Transcription was canceled")
|
||||
|
||||
error_spy.assert_called_once()
|
||||
assert task.status == FileTranscriptionTask.Status.CANCELED
|
||||
assert "canceled" in task.error.lower()
|
||||
|
||||
def test_on_task_error_with_regular_error(self, simple_worker):
|
||||
options = TranscriptionOptions()
|
||||
task = FileTranscriptionTask(
|
||||
file_path=str(test_multibyte_utf8_audio_path),
|
||||
transcription_options=options,
|
||||
file_transcription_options=FileTranscriptionOptions(),
|
||||
model_path="mock_path"
|
||||
)
|
||||
simple_worker.current_task = task
|
||||
|
||||
error_spy = unittest.mock.Mock()
|
||||
simple_worker.task_error.connect(error_spy)
|
||||
|
||||
simple_worker.on_task_error("Some error occurred")
|
||||
|
||||
error_spy.assert_called_once()
|
||||
assert task.status == FileTranscriptionTask.Status.FAILED
|
||||
assert task.error == "Some error occurred"
|
||||
|
||||
def test_on_task_progress_conversion(self, simple_worker):
|
||||
options = TranscriptionOptions()
|
||||
task = FileTranscriptionTask(
|
||||
file_path=str(test_multibyte_utf8_audio_path),
|
||||
transcription_options=options,
|
||||
file_transcription_options=FileTranscriptionOptions(),
|
||||
model_path="mock_path"
|
||||
)
|
||||
simple_worker.current_task = task
|
||||
|
||||
progress_spy = unittest.mock.Mock()
|
||||
simple_worker.task_progress.connect(progress_spy)
|
||||
|
||||
simple_worker.on_task_progress((50, 100))
|
||||
|
||||
progress_spy.assert_called_once()
|
||||
args = progress_spy.call_args[0]
|
||||
assert args[0] == task
|
||||
assert args[1] == 0.5
|
||||
|
||||
def test_stop_puts_sentinel_in_queue(self, simple_worker):
|
||||
initial_size = simple_worker.tasks_queue.qsize()
|
||||
simple_worker.stop()
|
||||
# Sentinel (None) should be added to queue
|
||||
assert simple_worker.tasks_queue.qsize() == initial_size + 1
|
||||
|
||||
def test_on_task_completed_with_speech_path(self, simple_worker, tmp_path):
|
||||
"""Test on_task_completed cleans up speech_path file"""
|
||||
options = TranscriptionOptions()
|
||||
task = FileTranscriptionTask(
|
||||
file_path=str(test_multibyte_utf8_audio_path),
|
||||
transcription_options=options,
|
||||
file_transcription_options=FileTranscriptionOptions(),
|
||||
model_path="mock_path"
|
||||
)
|
||||
simple_worker.current_task = task
|
||||
|
||||
# Create a temporary file to simulate speech extraction output
|
||||
speech_file = tmp_path / "audio_speech.mp3"
|
||||
speech_file.write_bytes(b"fake audio data")
|
||||
simple_worker.speech_path = speech_file
|
||||
|
||||
completed_spy = unittest.mock.Mock()
|
||||
simple_worker.task_completed.connect(completed_spy)
|
||||
|
||||
simple_worker.on_task_completed([Segment(0, 1000, "Test")])
|
||||
|
||||
completed_spy.assert_called_once()
|
||||
# Speech path should be cleaned up
|
||||
assert simple_worker.speech_path is None
|
||||
assert not speech_file.exists()
|
||||
|
||||
def test_on_task_completed_speech_path_missing(self, simple_worker, tmp_path):
|
||||
"""Test on_task_completed handles missing speech_path file gracefully"""
|
||||
options = TranscriptionOptions()
|
||||
task = FileTranscriptionTask(
|
||||
file_path=str(test_multibyte_utf8_audio_path),
|
||||
transcription_options=options,
|
||||
file_transcription_options=FileTranscriptionOptions(),
|
||||
model_path="mock_path"
|
||||
)
|
||||
simple_worker.current_task = task
|
||||
|
||||
# Set a speech path that doesn't exist
|
||||
simple_worker.speech_path = tmp_path / "nonexistent_speech.mp3"
|
||||
|
||||
completed_spy = unittest.mock.Mock()
|
||||
simple_worker.task_completed.connect(completed_spy)
|
||||
|
||||
# Should not raise even if file doesn't exist
|
||||
simple_worker.on_task_completed([])
|
||||
|
||||
completed_spy.assert_called_once()
|
||||
assert simple_worker.speech_path is None
|
||||
|
||||
def test_on_task_download_progress(self, simple_worker):
|
||||
"""Test on_task_download_progress emits signal"""
|
||||
options = TranscriptionOptions()
|
||||
task = FileTranscriptionTask(
|
||||
file_path=str(test_multibyte_utf8_audio_path),
|
||||
transcription_options=options,
|
||||
file_transcription_options=FileTranscriptionOptions(),
|
||||
model_path="mock_path"
|
||||
)
|
||||
simple_worker.current_task = task
|
||||
|
||||
download_spy = unittest.mock.Mock()
|
||||
simple_worker.task_download_progress.connect(download_spy)
|
||||
|
||||
simple_worker.on_task_download_progress(0.5)
|
||||
|
||||
download_spy.assert_called_once()
|
||||
args = download_spy.call_args[0]
|
||||
assert args[0] == task
|
||||
assert args[1] == 0.5
|
||||
|
||||
def test_cancel_task_stops_current_transcriber(self, simple_worker):
|
||||
"""Test cancel_task stops the current transcriber if it matches"""
|
||||
options = TranscriptionOptions()
|
||||
task = FileTranscriptionTask(
|
||||
file_path=str(test_multibyte_utf8_audio_path),
|
||||
transcription_options=options,
|
||||
file_transcription_options=FileTranscriptionOptions(),
|
||||
model_path="mock_path"
|
||||
)
|
||||
simple_worker.current_task = task
|
||||
|
||||
mock_transcriber = unittest.mock.Mock()
|
||||
simple_worker.current_transcriber = mock_transcriber
|
||||
|
||||
simple_worker.cancel_task(task.uid)
|
||||
|
||||
assert task.uid in simple_worker.canceled_tasks
|
||||
mock_transcriber.stop.assert_called_once()
|
||||
|
||||
def test_on_task_error_task_in_canceled_set(self, simple_worker):
|
||||
"""Test on_task_error does not emit signal when task is canceled"""
|
||||
options = TranscriptionOptions()
|
||||
task = FileTranscriptionTask(
|
||||
file_path=str(test_multibyte_utf8_audio_path),
|
||||
transcription_options=options,
|
||||
file_transcription_options=FileTranscriptionOptions(),
|
||||
model_path="mock_path"
|
||||
)
|
||||
simple_worker.current_task = task
|
||||
# Mark task as canceled
|
||||
simple_worker.canceled_tasks.add(task.uid)
|
||||
|
||||
error_spy = unittest.mock.Mock()
|
||||
simple_worker.task_error.connect(error_spy)
|
||||
|
||||
simple_worker.on_task_error("Some error")
|
||||
|
||||
# Should NOT emit since task was canceled
|
||||
error_spy.assert_not_called()
|
||||
|
||||
|
||||
class TestFileTranscriberQueueWorkerRun:
|
||||
def _make_task(self, model_type=ModelType.WHISPER_CPP, extract_speech=False):
|
||||
options = TranscriptionOptions(
|
||||
model=TranscriptionModel(model_type=model_type, whisper_model_size=WhisperModelSize.TINY),
|
||||
extract_speech=extract_speech
|
||||
)
|
||||
return FileTranscriptionTask(
|
||||
file_path=str(test_multibyte_utf8_audio_path),
|
||||
transcription_options=options,
|
||||
file_transcription_options=FileTranscriptionOptions(),
|
||||
model_path="mock_path"
|
||||
)
|
||||
|
||||
def test_run_returns_early_when_already_running(self, simple_worker):
|
||||
simple_worker.is_running = True
|
||||
# Should return without blocking (queue is empty, no get() call)
|
||||
simple_worker.run()
|
||||
# is_running stays True, nothing changed
|
||||
assert simple_worker.is_running is True
|
||||
|
||||
def test_run_stops_on_sentinel(self, simple_worker, qapp):
|
||||
completed_spy = unittest.mock.Mock()
|
||||
simple_worker.completed.connect(completed_spy)
|
||||
|
||||
simple_worker.tasks_queue.put(None)
|
||||
simple_worker.run()
|
||||
|
||||
completed_spy.assert_called_once()
|
||||
assert simple_worker.is_running is False
|
||||
|
||||
def test_run_skips_canceled_task_then_stops_on_sentinel(self, simple_worker, qapp):
|
||||
task = self._make_task()
|
||||
simple_worker.canceled_tasks.add(task.uid)
|
||||
|
||||
started_spy = unittest.mock.Mock()
|
||||
simple_worker.task_started.connect(started_spy)
|
||||
|
||||
# Put canceled task then sentinel
|
||||
simple_worker.tasks_queue.put(task)
|
||||
simple_worker.tasks_queue.put(None)
|
||||
|
||||
simple_worker.run()
|
||||
|
||||
# Canceled task should be skipped; completed emitted
|
||||
started_spy.assert_not_called()
|
||||
assert simple_worker.is_running is False
|
||||
|
||||
def test_run_creates_openai_transcriber(self, simple_worker, qapp):
|
||||
from buzz.transcriber.openai_whisper_api_file_transcriber import OpenAIWhisperAPIFileTranscriber
|
||||
|
||||
task = self._make_task(model_type=ModelType.OPEN_AI_WHISPER_API)
|
||||
simple_worker.tasks_queue.put(task)
|
||||
|
||||
with unittest.mock.patch.object(OpenAIWhisperAPIFileTranscriber, 'run'), \
|
||||
unittest.mock.patch.object(OpenAIWhisperAPIFileTranscriber, 'moveToThread'), \
|
||||
unittest.mock.patch('buzz.file_transcriber_queue_worker.QThread') as mock_thread_class:
|
||||
mock_thread = unittest.mock.MagicMock()
|
||||
mock_thread_class.return_value = mock_thread
|
||||
|
||||
simple_worker.run()
|
||||
|
||||
assert isinstance(simple_worker.current_transcriber, OpenAIWhisperAPIFileTranscriber)
|
||||
|
||||
def test_run_creates_whisper_transcriber_for_whisper_cpp(self, simple_worker, qapp):
|
||||
task = self._make_task(model_type=ModelType.WHISPER_CPP)
|
||||
simple_worker.tasks_queue.put(task)
|
||||
|
||||
with unittest.mock.patch.object(WhisperFileTranscriber, 'run'), \
|
||||
unittest.mock.patch.object(WhisperFileTranscriber, 'moveToThread'), \
|
||||
unittest.mock.patch('buzz.file_transcriber_queue_worker.QThread') as mock_thread_class:
|
||||
mock_thread = unittest.mock.MagicMock()
|
||||
mock_thread_class.return_value = mock_thread
|
||||
|
||||
simple_worker.run()
|
||||
|
||||
assert isinstance(simple_worker.current_transcriber, WhisperFileTranscriber)
|
||||
|
||||
def test_run_speech_extraction_failure_emits_error(self, simple_worker, qapp):
|
||||
task = self._make_task(extract_speech=True)
|
||||
simple_worker.tasks_queue.put(task)
|
||||
|
||||
error_spy = unittest.mock.Mock()
|
||||
simple_worker.task_error.connect(error_spy)
|
||||
|
||||
with unittest.mock.patch('buzz.file_transcriber_queue_worker.demucsApi.Separator',
|
||||
side_effect=RuntimeError("No internet")):
|
||||
simple_worker.run()
|
||||
|
||||
error_spy.assert_called_once()
|
||||
args = error_spy.call_args[0]
|
||||
assert args[0] == task
|
||||
assert simple_worker.is_running is False
|
||||
|
||||
|
||||
def test_transcription_with_whisper_cpp_tiny_no_speech_extraction(worker):
|
||||
options = TranscriptionOptions(
|
||||
model=TranscriptionModel(model_type=ModelType.WHISPER_CPP, whisper_model_size=WhisperModelSize.TINY),
|
||||
|
|
|
|||
|
|
@ -5,78 +5,16 @@ import pytest
|
|||
|
||||
from buzz.transcriber.openai_whisper_api_file_transcriber import (
|
||||
OpenAIWhisperAPIFileTranscriber,
|
||||
append_segment,
|
||||
)
|
||||
from buzz.transcriber.transcriber import (
|
||||
FileTranscriptionTask,
|
||||
TranscriptionOptions,
|
||||
FileTranscriptionOptions,
|
||||
Segment,
|
||||
)
|
||||
|
||||
from openai.types.audio import Transcription, Translation
|
||||
|
||||
|
||||
class TestAppendSegment:
|
||||
def test_valid_utf8(self):
|
||||
result = []
|
||||
success = append_segment(result, b"Hello world", 100, 200)
|
||||
assert success is True
|
||||
assert len(result) == 1
|
||||
assert result[0].start == 1000 # 100 centiseconds to ms
|
||||
assert result[0].end == 2000 # 200 centiseconds to ms
|
||||
assert result[0].text == "Hello world"
|
||||
|
||||
def test_empty_bytes(self):
|
||||
result = []
|
||||
success = append_segment(result, b"", 100, 200)
|
||||
assert success is True
|
||||
assert len(result) == 0
|
||||
|
||||
def test_invalid_utf8(self):
|
||||
result = []
|
||||
# Invalid UTF-8 sequence
|
||||
success = append_segment(result, b"\xff\xfe", 100, 200)
|
||||
assert success is False
|
||||
assert len(result) == 0
|
||||
|
||||
def test_multibyte_utf8(self):
|
||||
result = []
|
||||
success = append_segment(result, "Привет".encode("utf-8"), 50, 150)
|
||||
assert success is True
|
||||
assert len(result) == 1
|
||||
assert result[0].text == "Привет"
|
||||
|
||||
|
||||
class TestGetValue:
|
||||
def test_get_value_from_dict(self):
|
||||
obj = {"key": "value", "number": 42}
|
||||
assert OpenAIWhisperAPIFileTranscriber.get_value(obj, "key") == "value"
|
||||
assert OpenAIWhisperAPIFileTranscriber.get_value(obj, "number") == 42
|
||||
|
||||
def test_get_value_from_object(self):
|
||||
class TestObj:
|
||||
key = "value"
|
||||
number = 42
|
||||
|
||||
obj = TestObj()
|
||||
assert OpenAIWhisperAPIFileTranscriber.get_value(obj, "key") == "value"
|
||||
assert OpenAIWhisperAPIFileTranscriber.get_value(obj, "number") == 42
|
||||
|
||||
def test_get_value_missing_key_dict(self):
|
||||
obj = {"key": "value"}
|
||||
assert OpenAIWhisperAPIFileTranscriber.get_value(obj, "missing") is None
|
||||
assert OpenAIWhisperAPIFileTranscriber.get_value(obj, "missing", "default") == "default"
|
||||
|
||||
def test_get_value_missing_attribute_object(self):
|
||||
class TestObj:
|
||||
key = "value"
|
||||
|
||||
obj = TestObj()
|
||||
assert OpenAIWhisperAPIFileTranscriber.get_value(obj, "missing") is None
|
||||
assert OpenAIWhisperAPIFileTranscriber.get_value(obj, "missing", "default") == "default"
|
||||
|
||||
|
||||
class TestOpenAIWhisperAPIFileTranscriber:
|
||||
@pytest.fixture
|
||||
def mock_openai_client(self):
|
||||
|
|
|
|||
|
|
@ -1,8 +1,7 @@
|
|||
import os
|
||||
import sys
|
||||
import time
|
||||
import numpy as np
|
||||
from unittest.mock import Mock, patch, MagicMock
|
||||
from unittest.mock import Mock, patch
|
||||
|
||||
from PyQt6.QtCore import QThread
|
||||
|
||||
|
|
@ -11,78 +10,10 @@ from buzz.assets import APP_BASE_DIR
|
|||
from buzz.model_loader import TranscriptionModel, ModelType, WhisperModelSize
|
||||
from buzz.transcriber.recording_transcriber import RecordingTranscriber
|
||||
from buzz.transcriber.transcriber import TranscriptionOptions, Task
|
||||
from buzz.settings.recording_transcriber_mode import RecordingTranscriberMode
|
||||
from tests.mock_sounddevice import MockSoundDevice
|
||||
from tests.model_loader import get_model_path
|
||||
|
||||
|
||||
class TestAmplitude:
|
||||
def test_symmetric_array(self):
|
||||
arr = np.array([1.0, -1.0, 2.0, -2.0])
|
||||
amplitude = RecordingTranscriber.amplitude(arr)
|
||||
# RMS: sqrt(mean([1, 1, 4, 4])) = sqrt(2.5) ≈ 1.5811
|
||||
assert abs(amplitude - np.sqrt(2.5)) < 1e-6
|
||||
|
||||
def test_asymmetric_array(self):
|
||||
arr = np.array([1.0, 2.0, 3.0, -1.0])
|
||||
amplitude = RecordingTranscriber.amplitude(arr)
|
||||
# RMS: sqrt(mean([1, 4, 9, 1])) = sqrt(3.75) ≈ 1.9365
|
||||
assert abs(amplitude - np.sqrt(3.75)) < 1e-6
|
||||
|
||||
def test_all_zeros(self):
|
||||
arr = np.array([0.0, 0.0, 0.0])
|
||||
amplitude = RecordingTranscriber.amplitude(arr)
|
||||
assert amplitude == 0.0
|
||||
|
||||
def test_all_positive(self):
|
||||
arr = np.array([1.0, 2.0, 3.0, 4.0])
|
||||
amplitude = RecordingTranscriber.amplitude(arr)
|
||||
# RMS: sqrt(mean([1, 4, 9, 16])) = sqrt(7.5) ≈ 2.7386
|
||||
assert abs(amplitude - np.sqrt(7.5)) < 1e-6
|
||||
|
||||
def test_all_negative(self):
|
||||
arr = np.array([-1.0, -2.0, -3.0, -4.0])
|
||||
amplitude = RecordingTranscriber.amplitude(arr)
|
||||
# RMS is symmetric: same as all_positive
|
||||
assert abs(amplitude - np.sqrt(7.5)) < 1e-6
|
||||
|
||||
def test_returns_float(self):
|
||||
arr = np.array([0.5], dtype=np.float32)
|
||||
amplitude = RecordingTranscriber.amplitude(arr)
|
||||
assert isinstance(amplitude, float)
|
||||
|
||||
|
||||
class TestGetDeviceSampleRate:
|
||||
def test_returns_default_16khz_when_supported(self):
|
||||
with patch("sounddevice.check_input_settings"):
|
||||
rate = RecordingTranscriber.get_device_sample_rate(None)
|
||||
assert rate == 16000
|
||||
|
||||
def test_falls_back_to_device_default(self):
|
||||
import sounddevice
|
||||
from sounddevice import PortAudioError
|
||||
|
||||
def raise_error(*args, **kwargs):
|
||||
raise PortAudioError("Device doesn't support 16000")
|
||||
|
||||
device_info = {"default_samplerate": 44100}
|
||||
with patch("sounddevice.check_input_settings", side_effect=raise_error), \
|
||||
patch("sounddevice.query_devices", return_value=device_info):
|
||||
rate = RecordingTranscriber.get_device_sample_rate(0)
|
||||
assert rate == 44100
|
||||
|
||||
def test_returns_default_when_query_fails(self):
|
||||
from sounddevice import PortAudioError
|
||||
|
||||
def raise_error(*args, **kwargs):
|
||||
raise PortAudioError("Device doesn't support 16000")
|
||||
|
||||
with patch("sounddevice.check_input_settings", side_effect=raise_error), \
|
||||
patch("sounddevice.query_devices", return_value=None):
|
||||
rate = RecordingTranscriber.get_device_sample_rate(0)
|
||||
assert rate == 16000
|
||||
|
||||
|
||||
class TestRecordingTranscriber:
|
||||
|
||||
def test_should_transcribe(self, qtbot):
|
||||
|
|
@ -120,432 +51,16 @@ class TestRecordingTranscriber:
|
|||
transcriber.transcription.connect(on_transcription)
|
||||
|
||||
thread.start()
|
||||
try:
|
||||
qtbot.waitUntil(lambda: len(transcriptions) == 3, timeout=120_000)
|
||||
qtbot.waitUntil(lambda: len(transcriptions) == 3, timeout=60_000)
|
||||
|
||||
# any string in any transcription
|
||||
strings_to_check = [_("Starting Whisper.cpp..."), "Bienvenue dans Passe"]
|
||||
assert any(s in t for s in strings_to_check for t in transcriptions)
|
||||
finally:
|
||||
# Ensure cleanup runs even if waitUntil times out
|
||||
transcriber.stop_recording()
|
||||
time.sleep(10)
|
||||
# any string in any transcription
|
||||
strings_to_check = [_("Starting Whisper.cpp..."), "Bienvenue dans Passe"]
|
||||
assert any(s in t for s in strings_to_check for t in transcriptions)
|
||||
|
||||
thread.quit()
|
||||
thread.wait()
|
||||
|
||||
# Ensure process is cleaned up
|
||||
if transcriber.process and transcriber.process.poll() is None:
|
||||
transcriber.process.terminate()
|
||||
try:
|
||||
transcriber.process.wait(timeout=2)
|
||||
except:
|
||||
pass
|
||||
|
||||
# Process pending events to ensure cleanup
|
||||
from PyQt6.QtCore import QCoreApplication
|
||||
QCoreApplication.processEvents()
|
||||
time.sleep(0.1)
|
||||
|
||||
|
||||
class TestRecordingTranscriberInit:
|
||||
def test_init_default_mode(self):
|
||||
transcription_options = TranscriptionOptions(
|
||||
model=TranscriptionModel(model_type=ModelType.WHISPER_CPP),
|
||||
language="en",
|
||||
task=Task.TRANSCRIBE,
|
||||
)
|
||||
|
||||
with patch("sounddevice.check_input_settings"):
|
||||
transcriber = RecordingTranscriber(
|
||||
transcription_options=transcription_options,
|
||||
input_device_index=0,
|
||||
sample_rate=16000,
|
||||
model_path="/fake/path",
|
||||
sounddevice=MockSoundDevice(),
|
||||
)
|
||||
|
||||
assert transcriber.transcription_options == transcription_options
|
||||
assert transcriber.input_device_index == 0
|
||||
assert transcriber.sample_rate == 16000
|
||||
assert transcriber.model_path == "/fake/path"
|
||||
assert transcriber.n_batch_samples == 5 * 16000
|
||||
assert transcriber.keep_sample_seconds == 0.15
|
||||
assert transcriber.is_running is False
|
||||
assert transcriber.openai_client is None
|
||||
|
||||
def test_init_append_and_correct_mode(self):
|
||||
transcription_options = TranscriptionOptions(
|
||||
model=TranscriptionModel(model_type=ModelType.WHISPER_CPP),
|
||||
language="en",
|
||||
task=Task.TRANSCRIBE,
|
||||
)
|
||||
|
||||
with patch("sounddevice.check_input_settings"), \
|
||||
patch("buzz.transcriber.recording_transcriber.Settings") as mock_settings_class:
|
||||
# Mock settings to return APPEND_AND_CORRECT mode (index 2 in the enum)
|
||||
mock_settings_instance = MagicMock()
|
||||
mock_settings_class.return_value = mock_settings_instance
|
||||
# Return 2 for APPEND_AND_CORRECT mode (it's the third item in the enum)
|
||||
mock_settings_instance.value.return_value = 2
|
||||
|
||||
transcriber = RecordingTranscriber(
|
||||
transcription_options=transcription_options,
|
||||
input_device_index=0,
|
||||
sample_rate=16000,
|
||||
model_path="/fake/path",
|
||||
sounddevice=MockSoundDevice(),
|
||||
)
|
||||
|
||||
# APPEND_AND_CORRECT mode should use smaller batch size and longer keep duration
|
||||
assert transcriber.n_batch_samples == int(transcription_options.transcription_step * 16000)
|
||||
assert transcriber.keep_sample_seconds == 1.5
|
||||
|
||||
def test_init_stores_silence_threshold(self):
|
||||
transcription_options = TranscriptionOptions(
|
||||
model=TranscriptionModel(model_type=ModelType.WHISPER_CPP),
|
||||
language="en",
|
||||
task=Task.TRANSCRIBE,
|
||||
silence_threshold=0.01,
|
||||
)
|
||||
|
||||
with patch("sounddevice.check_input_settings"):
|
||||
transcriber = RecordingTranscriber(
|
||||
transcription_options=transcription_options,
|
||||
input_device_index=0,
|
||||
sample_rate=16000,
|
||||
model_path="/fake/path",
|
||||
sounddevice=MockSoundDevice(),
|
||||
)
|
||||
|
||||
assert transcriber.transcription_options.silence_threshold == 0.01
|
||||
|
||||
def test_init_uses_default_sample_rate_when_none(self):
|
||||
transcription_options = TranscriptionOptions(
|
||||
model=TranscriptionModel(model_type=ModelType.WHISPER_CPP),
|
||||
language="en",
|
||||
task=Task.TRANSCRIBE,
|
||||
)
|
||||
|
||||
with patch("sounddevice.check_input_settings"):
|
||||
transcriber = RecordingTranscriber(
|
||||
transcription_options=transcription_options,
|
||||
input_device_index=0,
|
||||
sample_rate=None,
|
||||
model_path="/fake/path",
|
||||
sounddevice=MockSoundDevice(),
|
||||
)
|
||||
|
||||
# Should use default whisper sample rate
|
||||
assert transcriber.sample_rate == 16000
|
||||
|
||||
|
||||
class TestStreamCallback:
|
||||
def test_stream_callback_adds_to_queue(self):
|
||||
transcription_options = TranscriptionOptions(
|
||||
model=TranscriptionModel(model_type=ModelType.WHISPER_CPP),
|
||||
language="en",
|
||||
task=Task.TRANSCRIBE,
|
||||
)
|
||||
|
||||
with patch("sounddevice.check_input_settings"):
|
||||
transcriber = RecordingTranscriber(
|
||||
transcription_options=transcription_options,
|
||||
input_device_index=0,
|
||||
sample_rate=16000,
|
||||
model_path="/fake/path",
|
||||
sounddevice=MockSoundDevice(),
|
||||
)
|
||||
|
||||
# Create test audio data
|
||||
in_data = np.array([[0.1], [0.2], [0.3], [0.4]], dtype=np.float32)
|
||||
|
||||
initial_size = transcriber.queue.size
|
||||
transcriber.stream_callback(in_data, 4, None, None)
|
||||
|
||||
# Queue should have grown by 4 samples
|
||||
assert transcriber.queue.size == initial_size + 4
|
||||
|
||||
def test_stream_callback_emits_amplitude_changed(self):
|
||||
transcription_options = TranscriptionOptions(
|
||||
model=TranscriptionModel(model_type=ModelType.WHISPER_CPP),
|
||||
language="en",
|
||||
task=Task.TRANSCRIBE,
|
||||
)
|
||||
|
||||
with patch("sounddevice.check_input_settings"):
|
||||
transcriber = RecordingTranscriber(
|
||||
transcription_options=transcription_options,
|
||||
input_device_index=0,
|
||||
sample_rate=16000,
|
||||
model_path="/fake/path",
|
||||
sounddevice=MockSoundDevice(),
|
||||
)
|
||||
|
||||
# Mock the amplitude_changed signal
|
||||
amplitude_values = []
|
||||
transcriber.amplitude_changed.connect(lambda amp: amplitude_values.append(amp))
|
||||
|
||||
# Create test audio data
|
||||
in_data = np.array([[0.1], [0.2], [0.3], [0.4]], dtype=np.float32)
|
||||
transcriber.stream_callback(in_data, 4, None, None)
|
||||
|
||||
# Should have emitted one amplitude value
|
||||
assert len(amplitude_values) == 1
|
||||
assert amplitude_values[0] > 0
|
||||
|
||||
def test_stream_callback_drops_data_when_queue_full(self):
|
||||
transcription_options = TranscriptionOptions(
|
||||
model=TranscriptionModel(model_type=ModelType.WHISPER_CPP),
|
||||
language="en",
|
||||
task=Task.TRANSCRIBE,
|
||||
)
|
||||
|
||||
with patch("sounddevice.check_input_settings"):
|
||||
transcriber = RecordingTranscriber(
|
||||
transcription_options=transcription_options,
|
||||
input_device_index=0,
|
||||
sample_rate=16000,
|
||||
model_path="/fake/path",
|
||||
sounddevice=MockSoundDevice(),
|
||||
)
|
||||
|
||||
# Fill the queue beyond max_queue_size
|
||||
transcriber.queue = np.ones(transcriber.max_queue_size, dtype=np.float32)
|
||||
initial_size = transcriber.queue.size
|
||||
|
||||
# Try to add more data
|
||||
in_data = np.array([[0.1], [0.2]], dtype=np.float32)
|
||||
transcriber.stream_callback(in_data, 2, None, None)
|
||||
|
||||
# Queue should not have grown (data was dropped)
|
||||
assert transcriber.queue.size == initial_size
|
||||
|
||||
|
||||
class TestStopRecording:
|
||||
def test_stop_recording_sets_is_running_false(self):
|
||||
transcription_options = TranscriptionOptions(
|
||||
model=TranscriptionModel(model_type=ModelType.WHISPER_CPP),
|
||||
language="en",
|
||||
task=Task.TRANSCRIBE,
|
||||
)
|
||||
|
||||
with patch("sounddevice.check_input_settings"):
|
||||
transcriber = RecordingTranscriber(
|
||||
transcription_options=transcription_options,
|
||||
input_device_index=0,
|
||||
sample_rate=16000,
|
||||
model_path="/fake/path",
|
||||
sounddevice=MockSoundDevice(),
|
||||
)
|
||||
|
||||
transcriber.is_running = True
|
||||
# Wait for the thread to finish
|
||||
transcriber.stop_recording()
|
||||
time.sleep(10)
|
||||
|
||||
assert transcriber.is_running is False
|
||||
|
||||
def test_stop_recording_terminates_process(self):
|
||||
transcription_options = TranscriptionOptions(
|
||||
model=TranscriptionModel(model_type=ModelType.WHISPER_CPP),
|
||||
language="en",
|
||||
task=Task.TRANSCRIBE,
|
||||
)
|
||||
|
||||
with patch("sounddevice.check_input_settings"):
|
||||
transcriber = RecordingTranscriber(
|
||||
transcription_options=transcription_options,
|
||||
input_device_index=0,
|
||||
sample_rate=16000,
|
||||
model_path="/fake/path",
|
||||
sounddevice=MockSoundDevice(),
|
||||
)
|
||||
|
||||
# Mock a running process
|
||||
mock_process = MagicMock()
|
||||
mock_process.poll.return_value = None # Process is running
|
||||
transcriber.process = mock_process
|
||||
|
||||
transcriber.stop_recording()
|
||||
|
||||
# Process should have been terminated and waited
|
||||
mock_process.terminate.assert_called_once()
|
||||
mock_process.wait.assert_called_once_with(timeout=5)
|
||||
|
||||
def test_stop_recording_skips_terminated_process(self):
|
||||
transcription_options = TranscriptionOptions(
|
||||
model=TranscriptionModel(model_type=ModelType.WHISPER_CPP),
|
||||
language="en",
|
||||
task=Task.TRANSCRIBE,
|
||||
)
|
||||
|
||||
with patch("sounddevice.check_input_settings"):
|
||||
transcriber = RecordingTranscriber(
|
||||
transcription_options=transcription_options,
|
||||
input_device_index=0,
|
||||
sample_rate=16000,
|
||||
model_path="/fake/path",
|
||||
sounddevice=MockSoundDevice(),
|
||||
)
|
||||
|
||||
# Mock an already terminated process
|
||||
mock_process = MagicMock()
|
||||
mock_process.poll.return_value = 0 # Process already terminated
|
||||
transcriber.process = mock_process
|
||||
|
||||
transcriber.stop_recording()
|
||||
|
||||
# terminate and wait should not be called
|
||||
mock_process.terminate.assert_not_called()
|
||||
mock_process.wait.assert_not_called()
|
||||
|
||||
|
||||
class TestStartLocalWhisperServer:
|
||||
def test_start_local_whisper_server_creates_openai_client(self):
|
||||
transcription_options = TranscriptionOptions(
|
||||
model=TranscriptionModel(model_type=ModelType.WHISPER_CPP),
|
||||
language="en",
|
||||
task=Task.TRANSCRIBE,
|
||||
)
|
||||
|
||||
with patch("sounddevice.check_input_settings"), \
|
||||
patch("subprocess.Popen") as mock_popen, \
|
||||
patch("time.sleep"):
|
||||
|
||||
# Mock a successful process
|
||||
mock_process = MagicMock()
|
||||
mock_process.poll.return_value = None # Process is running
|
||||
mock_popen.return_value = mock_process
|
||||
|
||||
transcriber = RecordingTranscriber(
|
||||
transcription_options=transcription_options,
|
||||
input_device_index=0,
|
||||
sample_rate=16000,
|
||||
model_path="/fake/path",
|
||||
sounddevice=MockSoundDevice(),
|
||||
)
|
||||
|
||||
try:
|
||||
transcriber.is_running = True
|
||||
transcriber.start_local_whisper_server()
|
||||
|
||||
# Should have created an OpenAI client
|
||||
assert transcriber.openai_client is not None
|
||||
assert transcriber.process is not None
|
||||
finally:
|
||||
# Clean up to prevent QThread warnings
|
||||
transcriber.is_running = False
|
||||
transcriber.process = None
|
||||
|
||||
def test_start_local_whisper_server_with_language(self):
|
||||
transcription_options = TranscriptionOptions(
|
||||
model=TranscriptionModel(model_type=ModelType.WHISPER_CPP),
|
||||
language="fr",
|
||||
task=Task.TRANSCRIBE,
|
||||
)
|
||||
|
||||
with patch("sounddevice.check_input_settings"), \
|
||||
patch("subprocess.Popen") as mock_popen, \
|
||||
patch("time.sleep"):
|
||||
|
||||
mock_process = MagicMock()
|
||||
mock_process.poll.return_value = None
|
||||
mock_popen.return_value = mock_process
|
||||
|
||||
transcriber = RecordingTranscriber(
|
||||
transcription_options=transcription_options,
|
||||
input_device_index=0,
|
||||
sample_rate=16000,
|
||||
model_path="/fake/path",
|
||||
sounddevice=MockSoundDevice(),
|
||||
)
|
||||
|
||||
try:
|
||||
transcriber.is_running = True
|
||||
transcriber.start_local_whisper_server()
|
||||
|
||||
# Check that the language was passed to the command
|
||||
call_args = mock_popen.call_args
|
||||
cmd = call_args[0][0]
|
||||
assert "--language" in cmd
|
||||
assert "fr" in cmd
|
||||
finally:
|
||||
transcriber.is_running = False
|
||||
transcriber.process = None
|
||||
|
||||
def test_start_local_whisper_server_auto_language(self):
|
||||
transcription_options = TranscriptionOptions(
|
||||
model=TranscriptionModel(model_type=ModelType.WHISPER_CPP),
|
||||
language=None,
|
||||
task=Task.TRANSCRIBE,
|
||||
)
|
||||
|
||||
with patch("sounddevice.check_input_settings"), \
|
||||
patch("subprocess.Popen") as mock_popen, \
|
||||
patch("time.sleep"):
|
||||
|
||||
mock_process = MagicMock()
|
||||
mock_process.poll.return_value = None
|
||||
mock_popen.return_value = mock_process
|
||||
|
||||
transcriber = RecordingTranscriber(
|
||||
transcription_options=transcription_options,
|
||||
input_device_index=0,
|
||||
sample_rate=16000,
|
||||
model_path="/fake/path",
|
||||
sounddevice=MockSoundDevice(),
|
||||
)
|
||||
|
||||
try:
|
||||
transcriber.is_running = True
|
||||
transcriber.start_local_whisper_server()
|
||||
|
||||
# Check that auto language was used
|
||||
call_args = mock_popen.call_args
|
||||
cmd = call_args[0][0]
|
||||
assert "--language" in cmd
|
||||
assert "auto" in cmd
|
||||
finally:
|
||||
transcriber.is_running = False
|
||||
transcriber.process = None
|
||||
|
||||
def test_start_local_whisper_server_handles_failure(self):
|
||||
transcription_options = TranscriptionOptions(
|
||||
model=TranscriptionModel(model_type=ModelType.WHISPER_CPP),
|
||||
language="en",
|
||||
task=Task.TRANSCRIBE,
|
||||
)
|
||||
|
||||
with patch("sounddevice.check_input_settings"), \
|
||||
patch("subprocess.Popen") as mock_popen, \
|
||||
patch("time.sleep"):
|
||||
|
||||
# Mock a failed process
|
||||
mock_process = MagicMock()
|
||||
mock_process.poll.return_value = 1 # Process terminated with error
|
||||
mock_process.stderr.read.return_value = b"Error loading model"
|
||||
mock_popen.return_value = mock_process
|
||||
|
||||
transcriber = RecordingTranscriber(
|
||||
transcription_options=transcription_options,
|
||||
input_device_index=0,
|
||||
sample_rate=16000,
|
||||
model_path="/fake/path",
|
||||
sounddevice=MockSoundDevice(),
|
||||
)
|
||||
|
||||
transcriptions = []
|
||||
transcriber.transcription.connect(lambda text: transcriptions.append(text))
|
||||
|
||||
try:
|
||||
transcriber.is_running = True
|
||||
transcriber.start_local_whisper_server()
|
||||
|
||||
# Should not have created a client when server failed
|
||||
assert transcriber.openai_client is None
|
||||
# Should have emitted starting and error messages
|
||||
assert len(transcriptions) >= 1
|
||||
# First message should be about starting Whisper.cpp
|
||||
assert "Whisper" in transcriptions[0]
|
||||
finally:
|
||||
transcriber.is_running = False
|
||||
transcriber.process = None
|
||||
thread.quit()
|
||||
thread.wait()
|
||||
time.sleep(3)
|
||||
|
|
|
|||
|
|
@ -1,69 +1,9 @@
|
|||
import os
|
||||
import sys
|
||||
import platform
|
||||
from unittest.mock import patch
|
||||
|
||||
import pytest
|
||||
|
||||
from buzz.transformers_whisper import TransformersTranscriber, is_intel_mac, is_peft_model
|
||||
|
||||
|
||||
class TestIsIntelMac:
|
||||
@pytest.mark.parametrize(
|
||||
"sys_platform,machine,expected",
|
||||
[
|
||||
("linux", "x86_64", False),
|
||||
("win32", "x86_64", False),
|
||||
("darwin", "arm64", False),
|
||||
("darwin", "x86_64", True),
|
||||
("darwin", "i386", False),
|
||||
],
|
||||
)
|
||||
def test_is_intel_mac(self, sys_platform, machine, expected):
|
||||
with patch("buzz.transformers_whisper.sys.platform", sys_platform), \
|
||||
patch("buzz.transformers_whisper.platform.machine", return_value=machine):
|
||||
assert is_intel_mac() == expected
|
||||
|
||||
|
||||
class TestIsPeftModel:
|
||||
@pytest.mark.parametrize(
|
||||
"model_id,expected",
|
||||
[
|
||||
("openai/whisper-tiny-peft", True),
|
||||
("user/model-PEFT", True),
|
||||
("openai/whisper-tiny", False),
|
||||
("facebook/mms-1b-all", False),
|
||||
("", False),
|
||||
],
|
||||
)
|
||||
def test_peft_detection(self, model_id, expected):
|
||||
assert is_peft_model(model_id) == expected
|
||||
|
||||
|
||||
class TestGetPeftRepoId:
|
||||
def test_repo_id_returned_as_is(self):
|
||||
transcriber = TransformersTranscriber("user/whisper-tiny-peft")
|
||||
with patch("os.path.exists", return_value=False):
|
||||
assert transcriber._get_peft_repo_id() == "user/whisper-tiny-peft"
|
||||
|
||||
def test_linux_cache_path(self):
|
||||
linux_path = "/home/user/.cache/Buzz/models/models--user--whisper-peft/snapshots/abc123"
|
||||
transcriber = TransformersTranscriber(linux_path)
|
||||
with patch("os.path.exists", return_value=True), \
|
||||
patch("buzz.transformers_whisper.os.sep", "/"):
|
||||
assert transcriber._get_peft_repo_id() == "user/whisper-peft"
|
||||
|
||||
def test_windows_cache_path(self):
|
||||
windows_path = r"C:\Users\user\.cache\Buzz\models\models--user--whisper-peft\snapshots\abc123"
|
||||
transcriber = TransformersTranscriber(windows_path)
|
||||
with patch("os.path.exists", return_value=True), \
|
||||
patch("buzz.transformers_whisper.os.sep", "\\"):
|
||||
assert transcriber._get_peft_repo_id() == "user/whisper-peft"
|
||||
|
||||
def test_fallback_returns_model_id(self):
|
||||
transcriber = TransformersTranscriber("some-local-model")
|
||||
with patch("os.path.exists", return_value=True):
|
||||
assert transcriber._get_peft_repo_id() == "some-local-model"
|
||||
from buzz.transformers_whisper import TransformersTranscriber
|
||||
|
||||
|
||||
class TestGetMmsRepoId:
|
||||
|
|
|
|||
|
|
@ -37,7 +37,7 @@ class TestWhisperCpp:
|
|||
|
||||
# Combine all segment texts
|
||||
full_text = " ".join(segment.text for segment in segments)
|
||||
assert "Bien venu" in full_text or "bienvenu" in full_text.lower()
|
||||
assert "Bien venu" in full_text
|
||||
|
||||
def test_transcribe_word_level_timestamps(self):
|
||||
transcription_options = TranscriptionOptions(
|
||||
|
|
|
|||
|
|
@ -21,59 +21,11 @@ from buzz.transcriber.transcriber import (
|
|||
FileTranscriptionOptions,
|
||||
Segment,
|
||||
)
|
||||
from buzz.transcriber.whisper_file_transcriber import (
|
||||
WhisperFileTranscriber,
|
||||
check_file_has_audio_stream,
|
||||
PROGRESS_REGEX,
|
||||
)
|
||||
from buzz.transcriber.whisper_file_transcriber import WhisperFileTranscriber
|
||||
from tests.audio import test_audio_path
|
||||
from tests.model_loader import get_model_path
|
||||
|
||||
|
||||
class TestCheckFileHasAudioStream:
|
||||
def test_valid_audio_file(self):
|
||||
# Should not raise exception for valid audio file
|
||||
check_file_has_audio_stream(test_audio_path)
|
||||
|
||||
def test_missing_file(self):
|
||||
with pytest.raises(ValueError, match="File not found"):
|
||||
check_file_has_audio_stream("/nonexistent/path/to/file.mp3")
|
||||
|
||||
def test_invalid_media_file(self):
|
||||
# Create a temporary text file (not a valid media file)
|
||||
temp_file = tempfile.NamedTemporaryFile(delete=False, suffix=".mp3")
|
||||
try:
|
||||
temp_file.write(b"This is not a valid media file")
|
||||
temp_file.close()
|
||||
with pytest.raises(ValueError, match="Invalid media file"):
|
||||
check_file_has_audio_stream(temp_file.name)
|
||||
finally:
|
||||
os.unlink(temp_file.name)
|
||||
|
||||
|
||||
class TestProgressRegex:
|
||||
def test_integer_percentage(self):
|
||||
match = PROGRESS_REGEX.search("Progress: 50%")
|
||||
assert match is not None
|
||||
assert match.group() == "50%"
|
||||
|
||||
def test_decimal_percentage(self):
|
||||
match = PROGRESS_REGEX.search("Progress: 75.5%")
|
||||
assert match is not None
|
||||
assert match.group() == "75.5%"
|
||||
|
||||
def test_no_match(self):
|
||||
match = PROGRESS_REGEX.search("No percentage here")
|
||||
assert match is None
|
||||
|
||||
def test_extract_percentage_value(self):
|
||||
line = "Transcription progress: 85%"
|
||||
match = PROGRESS_REGEX.search(line)
|
||||
assert match is not None
|
||||
percentage = int(match.group().strip("%"))
|
||||
assert percentage == 85
|
||||
|
||||
|
||||
class TestWhisperFileTranscriber:
|
||||
@pytest.mark.parametrize(
|
||||
"file_path,output_format,expected_file_path",
|
||||
|
|
@ -357,42 +309,6 @@ class TestWhisperFileTranscriber:
|
|||
transcriber.stop()
|
||||
time.sleep(3)
|
||||
|
||||
def test_transcribe_from_folder_watch_source_deletes_file(self, qtbot):
|
||||
file_path = tempfile.mktemp(suffix=".mp3")
|
||||
shutil.copy(test_audio_path, file_path)
|
||||
|
||||
file_transcription_options = FileTranscriptionOptions(
|
||||
file_paths=[file_path],
|
||||
output_formats={OutputFormat.TXT},
|
||||
)
|
||||
transcription_options = TranscriptionOptions()
|
||||
model_path = get_model_path(transcription_options.model)
|
||||
|
||||
output_directory = tempfile.mkdtemp()
|
||||
transcriber = WhisperFileTranscriber(
|
||||
task=FileTranscriptionTask(
|
||||
model_path=model_path,
|
||||
transcription_options=transcription_options,
|
||||
file_transcription_options=file_transcription_options,
|
||||
file_path=file_path,
|
||||
original_file_path=file_path,
|
||||
output_directory=output_directory,
|
||||
source=FileTranscriptionTask.Source.FOLDER_WATCH,
|
||||
delete_source_file=True,
|
||||
)
|
||||
)
|
||||
with qtbot.wait_signal(transcriber.completed, timeout=10 * 6000):
|
||||
transcriber.run()
|
||||
|
||||
assert not os.path.isfile(file_path)
|
||||
assert not os.path.isfile(
|
||||
os.path.join(output_directory, os.path.basename(file_path))
|
||||
)
|
||||
assert len(glob.glob("*.txt", root_dir=output_directory)) > 0
|
||||
|
||||
transcriber.stop()
|
||||
time.sleep(3)
|
||||
|
||||
@pytest.mark.skip()
|
||||
def test_transcribe_stop(self):
|
||||
output_file_path = os.path.join(tempfile.gettempdir(), "whisper.txt")
|
||||
|
|
|
|||
|
|
@ -8,56 +8,6 @@ from PyQt6.QtCore import QThread
|
|||
from buzz.translator import Translator
|
||||
from buzz.transcriber.transcriber import TranscriptionOptions
|
||||
from buzz.widgets.transcriber.advanced_settings_dialog import AdvancedSettingsDialog
|
||||
from buzz.locale import _
|
||||
|
||||
|
||||
class TestParseBatchResponse:
|
||||
def test_simple_batch(self):
|
||||
response = "[1] Hello\n[2] World"
|
||||
result = Translator._parse_batch_response(response, 2)
|
||||
assert len(result) == 2
|
||||
assert result[0] == "Hello"
|
||||
assert result[1] == "World"
|
||||
|
||||
def test_missing_entries_fallback(self):
|
||||
response = "[1] Hello\n[3] World"
|
||||
result = Translator._parse_batch_response(response, 3)
|
||||
assert len(result) == 3
|
||||
assert result[0] == "Hello"
|
||||
assert result[1] == ""
|
||||
assert result[2] == "World"
|
||||
|
||||
def test_multiline_entries(self):
|
||||
response = "[1] This is a long\nmultiline translation\n[2] Short"
|
||||
result = Translator._parse_batch_response(response, 2)
|
||||
assert len(result) == 2
|
||||
assert "multiline" in result[0]
|
||||
assert result[1] == "Short"
|
||||
|
||||
def test_single_item_batch(self):
|
||||
response = "[1] Single translation"
|
||||
result = Translator._parse_batch_response(response, 1)
|
||||
assert len(result) == 1
|
||||
assert result[0] == "Single translation"
|
||||
|
||||
def test_empty_response(self):
|
||||
response = ""
|
||||
result = Translator._parse_batch_response(response, 2)
|
||||
assert len(result) == 2
|
||||
assert result[0] == ""
|
||||
assert result[1] == ""
|
||||
|
||||
def test_whitespace_handling(self):
|
||||
response = "[1] Hello with spaces \n[2] World "
|
||||
result = Translator._parse_batch_response(response, 2)
|
||||
assert result[0] == "Hello with spaces"
|
||||
assert result[1] == "World"
|
||||
|
||||
def test_out_of_order_entries(self):
|
||||
response = "[2] Second\n[1] First"
|
||||
result = Translator._parse_batch_response(response, 2)
|
||||
assert result[0] == "First"
|
||||
assert result[1] == "Second"
|
||||
|
||||
|
||||
class TestTranslator:
|
||||
|
|
@ -75,7 +25,6 @@ class TestTranslator:
|
|||
side_effect.call_count = 0
|
||||
|
||||
mock_queue.get.side_effect = side_effect
|
||||
mock_queue.get_nowait.side_effect = Empty
|
||||
mock_chat = Mock()
|
||||
mock_openai.return_value.chat = mock_chat
|
||||
mock_chat.completions.create.return_value = Mock(
|
||||
|
|
@ -161,10 +110,6 @@ class TestTranslator:
|
|||
self.translation_thread.quit()
|
||||
# Wait for the thread to actually finish before cleanup
|
||||
self.translation_thread.wait()
|
||||
# Process pending events to ensure deleteLater() is handled
|
||||
from PyQt6.QtCore import QCoreApplication
|
||||
QCoreApplication.processEvents()
|
||||
time.sleep(0.1) # Give time for cleanup
|
||||
|
||||
# Note: translator and translation_thread will be automatically deleted
|
||||
# via the deleteLater() connections set up earlier
|
||||
|
|
|
|||
|
|
@ -1,202 +0,0 @@
|
|||
import platform
|
||||
from datetime import datetime, timedelta
|
||||
from unittest.mock import patch
|
||||
|
||||
import pytest
|
||||
from pytestqt.qtbot import QtBot
|
||||
|
||||
from buzz.__version__ import VERSION
|
||||
from buzz.settings.settings import Settings
|
||||
from buzz.update_checker import UpdateChecker, UpdateInfo
|
||||
from tests.mock_qt import MockNetworkAccessManager, MockNetworkReply
|
||||
|
||||
|
||||
VERSION_INFO = {
|
||||
"version": "99.0.0",
|
||||
"release_notes": "Some fixes.",
|
||||
"download_urls": {
|
||||
"windows_x64": ["https://example.com/Buzz-99.0.0.exe"],
|
||||
"macos_arm": ["https://example.com/Buzz-99.0.0-arm.dmg"],
|
||||
"macos_x86": ["https://example.com/Buzz-99.0.0-x86.dmg"],
|
||||
},
|
||||
}
|
||||
|
||||
|
||||
@pytest.fixture()
|
||||
def checker(settings: Settings) -> UpdateChecker:
|
||||
reply = MockNetworkReply(data=VERSION_INFO)
|
||||
manager = MockNetworkAccessManager(reply=reply)
|
||||
return UpdateChecker(settings=settings, network_manager=manager)
|
||||
|
||||
|
||||
class TestShouldCheckForUpdates:
|
||||
def test_returns_false_on_linux(self, checker: UpdateChecker):
|
||||
with patch.object(platform, "system", return_value="Linux"):
|
||||
assert checker.should_check_for_updates() is False
|
||||
|
||||
def test_returns_true_on_windows_first_run(self, checker: UpdateChecker, settings: Settings):
|
||||
settings.set_value(Settings.Key.LAST_UPDATE_CHECK, "")
|
||||
with patch.object(platform, "system", return_value="Windows"):
|
||||
assert checker.should_check_for_updates() is True
|
||||
|
||||
def test_returns_true_on_macos_first_run(self, checker: UpdateChecker, settings: Settings):
|
||||
settings.set_value(Settings.Key.LAST_UPDATE_CHECK, "")
|
||||
with patch.object(platform, "system", return_value="Darwin"):
|
||||
assert checker.should_check_for_updates() is True
|
||||
|
||||
def test_returns_false_when_checked_recently(
|
||||
self, checker: UpdateChecker, settings: Settings
|
||||
):
|
||||
recent = (datetime.now() - timedelta(days=2)).isoformat()
|
||||
settings.set_value(Settings.Key.LAST_UPDATE_CHECK, recent)
|
||||
|
||||
with patch.object(platform, "system", return_value="Windows"):
|
||||
assert checker.should_check_for_updates() is False
|
||||
|
||||
def test_returns_true_when_check_is_overdue(
|
||||
self, checker: UpdateChecker, settings: Settings
|
||||
):
|
||||
old = (datetime.now() - timedelta(days=10)).isoformat()
|
||||
settings.set_value(Settings.Key.LAST_UPDATE_CHECK, old)
|
||||
|
||||
with patch.object(platform, "system", return_value="Windows"):
|
||||
assert checker.should_check_for_updates() is True
|
||||
|
||||
def test_returns_true_on_invalid_date_in_settings(
|
||||
self, checker: UpdateChecker, settings: Settings
|
||||
):
|
||||
settings.set_value(Settings.Key.LAST_UPDATE_CHECK, "not-a-date")
|
||||
|
||||
with patch.object(platform, "system", return_value="Windows"):
|
||||
assert checker.should_check_for_updates() is True
|
||||
|
||||
|
||||
class TestIsNewerVersion:
|
||||
def test_newer_major(self, checker: UpdateChecker):
|
||||
with patch("buzz.update_checker.VERSION", "1.0.0"):
|
||||
assert checker._is_newer_version("2.0.0") is True
|
||||
|
||||
def test_newer_minor(self, checker: UpdateChecker):
|
||||
with patch("buzz.update_checker.VERSION", "1.0.0"):
|
||||
assert checker._is_newer_version("1.1.0") is True
|
||||
|
||||
def test_newer_patch(self, checker: UpdateChecker):
|
||||
with patch("buzz.update_checker.VERSION", "1.0.0"):
|
||||
assert checker._is_newer_version("1.0.1") is True
|
||||
|
||||
def test_same_version(self, checker: UpdateChecker):
|
||||
with patch("buzz.update_checker.VERSION", "1.0.0"):
|
||||
assert checker._is_newer_version("1.0.0") is False
|
||||
|
||||
def test_older_version(self, checker: UpdateChecker):
|
||||
with patch("buzz.update_checker.VERSION", "2.0.0"):
|
||||
assert checker._is_newer_version("1.9.9") is False
|
||||
|
||||
def test_different_segment_count(self, checker: UpdateChecker):
|
||||
with patch("buzz.update_checker.VERSION", "1.0"):
|
||||
assert checker._is_newer_version("1.0.1") is True
|
||||
|
||||
def test_invalid_version_returns_false(self, checker: UpdateChecker):
|
||||
with patch("buzz.update_checker.VERSION", "1.0.0"):
|
||||
assert checker._is_newer_version("not-a-version") is False
|
||||
|
||||
|
||||
class TestGetDownloadUrl:
|
||||
def test_windows_returns_windows_urls(self, checker: UpdateChecker):
|
||||
with patch.object(platform, "system", return_value="Windows"):
|
||||
urls = checker._get_download_url(VERSION_INFO["download_urls"])
|
||||
assert urls == ["https://example.com/Buzz-99.0.0.exe"]
|
||||
|
||||
def test_macos_arm_returns_arm_urls(self, checker: UpdateChecker):
|
||||
with patch.object(platform, "system", return_value="Darwin"), \
|
||||
patch.object(platform, "machine", return_value="arm64"):
|
||||
urls = checker._get_download_url(VERSION_INFO["download_urls"])
|
||||
assert urls == ["https://example.com/Buzz-99.0.0-arm.dmg"]
|
||||
|
||||
def test_macos_x86_returns_x86_urls(self, checker: UpdateChecker):
|
||||
with patch.object(platform, "system", return_value="Darwin"), \
|
||||
patch.object(platform, "machine", return_value="x86_64"):
|
||||
urls = checker._get_download_url(VERSION_INFO["download_urls"])
|
||||
assert urls == ["https://example.com/Buzz-99.0.0-x86.dmg"]
|
||||
|
||||
def test_linux_returns_empty(self, checker: UpdateChecker):
|
||||
with patch.object(platform, "system", return_value="Linux"):
|
||||
urls = checker._get_download_url(VERSION_INFO["download_urls"])
|
||||
assert urls == []
|
||||
|
||||
def test_wraps_plain_string_in_list(self, checker: UpdateChecker):
|
||||
with patch.object(platform, "system", return_value="Windows"):
|
||||
urls = checker._get_download_url({"windows_x64": "https://example.com/a.exe"})
|
||||
assert urls == ["https://example.com/a.exe"]
|
||||
|
||||
|
||||
class TestCheckForUpdates:
|
||||
def _make_checker(self, settings: Settings, version_data: dict) -> UpdateChecker:
|
||||
settings.set_value(Settings.Key.LAST_UPDATE_CHECK, "")
|
||||
reply = MockNetworkReply(data=version_data)
|
||||
manager = MockNetworkAccessManager(reply=reply)
|
||||
return UpdateChecker(settings=settings, network_manager=manager)
|
||||
|
||||
def test_emits_update_available_when_newer_version(self, settings: Settings):
|
||||
received = []
|
||||
checker = self._make_checker(settings, VERSION_INFO)
|
||||
checker.update_available.connect(lambda info: received.append(info))
|
||||
|
||||
with patch.object(platform, "system", return_value="Windows"), \
|
||||
patch.object(platform, "machine", return_value="x86_64"), \
|
||||
patch("buzz.update_checker.VERSION", "1.0.0"):
|
||||
checker.check_for_updates()
|
||||
|
||||
assert len(received) == 1
|
||||
update_info: UpdateInfo = received[0]
|
||||
assert update_info.version == "99.0.0"
|
||||
assert update_info.release_notes == "Some fixes."
|
||||
assert update_info.download_urls == ["https://example.com/Buzz-99.0.0.exe"]
|
||||
|
||||
def test_does_not_emit_when_version_is_current(self, settings: Settings):
|
||||
received = []
|
||||
checker = self._make_checker(settings, {**VERSION_INFO, "version": VERSION})
|
||||
checker.update_available.connect(lambda info: received.append(info))
|
||||
|
||||
with patch.object(platform, "system", return_value="Windows"):
|
||||
checker.check_for_updates()
|
||||
|
||||
assert received == []
|
||||
|
||||
def test_skips_network_call_on_linux(self, settings: Settings):
|
||||
received = []
|
||||
checker = self._make_checker(settings, VERSION_INFO)
|
||||
checker.update_available.connect(lambda info: received.append(info))
|
||||
|
||||
with patch.object(platform, "system", return_value="Linux"):
|
||||
checker.check_for_updates()
|
||||
|
||||
assert received == []
|
||||
|
||||
def test_stores_last_check_date_after_reply(self, settings: Settings):
|
||||
checker = self._make_checker(settings, {**VERSION_INFO, "version": VERSION})
|
||||
|
||||
with patch.object(platform, "system", return_value="Windows"):
|
||||
checker.check_for_updates()
|
||||
|
||||
stored = settings.value(Settings.Key.LAST_UPDATE_CHECK, "")
|
||||
assert stored != ""
|
||||
datetime.fromisoformat(stored) # should not raise
|
||||
|
||||
def test_stores_available_version_when_update_found(self, settings: Settings):
|
||||
checker = self._make_checker(settings, VERSION_INFO)
|
||||
|
||||
with patch.object(platform, "system", return_value="Windows"), \
|
||||
patch("buzz.update_checker.VERSION", "1.0.0"):
|
||||
checker.check_for_updates()
|
||||
|
||||
assert settings.value(Settings.Key.UPDATE_AVAILABLE_VERSION, "") == "99.0.0"
|
||||
|
||||
def test_clears_available_version_when_up_to_date(self, settings: Settings):
|
||||
settings.set_value(Settings.Key.UPDATE_AVAILABLE_VERSION, "99.0.0")
|
||||
checker = self._make_checker(settings, {**VERSION_INFO, "version": VERSION})
|
||||
|
||||
with patch.object(platform, "system", return_value="Windows"):
|
||||
checker.check_for_updates()
|
||||
|
||||
assert settings.value(Settings.Key.UPDATE_AVAILABLE_VERSION, "") == ""
|
||||
|
|
@ -1,153 +0,0 @@
|
|||
import pytest
|
||||
from pytestqt.qtbot import QtBot
|
||||
|
||||
from buzz.transcriber.transcriber import TranscriptionOptions
|
||||
from buzz.widgets.transcriber.advanced_settings_dialog import AdvancedSettingsDialog
|
||||
|
||||
|
||||
class TestAdvancedSettingsDialogSilenceThreshold:
|
||||
def test_silence_threshold_spinbox_hidden_by_default(self, qtbot: QtBot):
|
||||
"""Silence threshold UI is not shown when show_recording_settings=False."""
|
||||
options = TranscriptionOptions()
|
||||
dialog = AdvancedSettingsDialog(transcription_options=options)
|
||||
qtbot.add_widget(dialog)
|
||||
assert not hasattr(dialog, "silence_threshold_spin_box")
|
||||
|
||||
def test_silence_threshold_spinbox_shown_when_recording_settings(self, qtbot: QtBot):
|
||||
"""Silence threshold spinbox is present when show_recording_settings=True."""
|
||||
options = TranscriptionOptions()
|
||||
dialog = AdvancedSettingsDialog(
|
||||
transcription_options=options, show_recording_settings=True
|
||||
)
|
||||
qtbot.add_widget(dialog)
|
||||
assert hasattr(dialog, "silence_threshold_spin_box")
|
||||
assert dialog.silence_threshold_spin_box is not None
|
||||
|
||||
def test_silence_threshold_spinbox_initial_value(self, qtbot: QtBot):
|
||||
"""Spinbox reflects the current silence_threshold from options."""
|
||||
options = TranscriptionOptions(silence_threshold=0.0075)
|
||||
dialog = AdvancedSettingsDialog(
|
||||
transcription_options=options, show_recording_settings=True
|
||||
)
|
||||
qtbot.add_widget(dialog)
|
||||
assert dialog.silence_threshold_spin_box.value() == pytest.approx(0.0075)
|
||||
|
||||
def test_silence_threshold_change_updates_options(self, qtbot: QtBot):
|
||||
"""Changing spinbox value updates transcription_options.silence_threshold."""
|
||||
options = TranscriptionOptions(silence_threshold=0.0025)
|
||||
dialog = AdvancedSettingsDialog(
|
||||
transcription_options=options, show_recording_settings=True
|
||||
)
|
||||
qtbot.add_widget(dialog)
|
||||
dialog.silence_threshold_spin_box.setValue(0.005)
|
||||
assert dialog.transcription_options.silence_threshold == pytest.approx(0.005)
|
||||
|
||||
def test_silence_threshold_change_emits_signal(self, qtbot: QtBot):
|
||||
"""Changing the spinbox emits transcription_options_changed."""
|
||||
options = TranscriptionOptions(silence_threshold=0.0025)
|
||||
dialog = AdvancedSettingsDialog(
|
||||
transcription_options=options, show_recording_settings=True
|
||||
)
|
||||
qtbot.add_widget(dialog)
|
||||
|
||||
emitted = []
|
||||
dialog.transcription_options_changed.connect(lambda o: emitted.append(o))
|
||||
|
||||
dialog.silence_threshold_spin_box.setValue(0.005)
|
||||
|
||||
assert len(emitted) == 1
|
||||
assert emitted[0].silence_threshold == pytest.approx(0.005)
|
||||
|
||||
|
||||
class TestAdvancedSettingsDialogLineSeparator:
|
||||
def test_line_separator_shown_when_recording_settings(self, qtbot: QtBot):
|
||||
options = TranscriptionOptions()
|
||||
dialog = AdvancedSettingsDialog(
|
||||
transcription_options=options, show_recording_settings=True
|
||||
)
|
||||
qtbot.add_widget(dialog)
|
||||
assert hasattr(dialog, "line_separator_line_edit")
|
||||
assert dialog.line_separator_line_edit is not None
|
||||
|
||||
def test_line_separator_hidden_by_default(self, qtbot: QtBot):
|
||||
options = TranscriptionOptions()
|
||||
dialog = AdvancedSettingsDialog(transcription_options=options)
|
||||
qtbot.add_widget(dialog)
|
||||
assert not hasattr(dialog, "line_separator_line_edit")
|
||||
|
||||
def test_line_separator_initial_value_displayed_as_escape(self, qtbot: QtBot):
|
||||
options = TranscriptionOptions(line_separator="\n\n")
|
||||
dialog = AdvancedSettingsDialog(
|
||||
transcription_options=options, show_recording_settings=True
|
||||
)
|
||||
qtbot.add_widget(dialog)
|
||||
assert dialog.line_separator_line_edit.text() == r"\n\n"
|
||||
|
||||
def test_line_separator_change_updates_options(self, qtbot: QtBot):
|
||||
options = TranscriptionOptions(line_separator="\n\n")
|
||||
dialog = AdvancedSettingsDialog(
|
||||
transcription_options=options, show_recording_settings=True
|
||||
)
|
||||
qtbot.add_widget(dialog)
|
||||
dialog.line_separator_line_edit.setText(r"\n")
|
||||
assert dialog.transcription_options.line_separator == "\n"
|
||||
|
||||
def test_line_separator_change_emits_signal(self, qtbot: QtBot):
|
||||
options = TranscriptionOptions(line_separator="\n\n")
|
||||
dialog = AdvancedSettingsDialog(
|
||||
transcription_options=options, show_recording_settings=True
|
||||
)
|
||||
qtbot.add_widget(dialog)
|
||||
emitted = []
|
||||
dialog.transcription_options_changed.connect(lambda o: emitted.append(o))
|
||||
dialog.line_separator_line_edit.setText(r"\n")
|
||||
assert len(emitted) == 1
|
||||
assert emitted[0].line_separator == "\n"
|
||||
|
||||
def test_line_separator_invalid_escape_does_not_crash(self, qtbot: QtBot):
|
||||
options = TranscriptionOptions(line_separator="\n\n")
|
||||
dialog = AdvancedSettingsDialog(
|
||||
transcription_options=options, show_recording_settings=True
|
||||
)
|
||||
qtbot.add_widget(dialog)
|
||||
dialog.line_separator_line_edit.setText("\\")
|
||||
# Options unchanged — previous valid value kept
|
||||
assert dialog.transcription_options.line_separator == "\n\n"
|
||||
|
||||
def test_line_separator_tab_character(self, qtbot: QtBot):
|
||||
options = TranscriptionOptions()
|
||||
dialog = AdvancedSettingsDialog(
|
||||
transcription_options=options, show_recording_settings=True
|
||||
)
|
||||
qtbot.add_widget(dialog)
|
||||
dialog.line_separator_line_edit.setText(r"\t")
|
||||
assert dialog.transcription_options.line_separator == "\t"
|
||||
|
||||
def test_line_separator_plain_text(self, qtbot: QtBot):
|
||||
options = TranscriptionOptions()
|
||||
dialog = AdvancedSettingsDialog(
|
||||
transcription_options=options, show_recording_settings=True
|
||||
)
|
||||
qtbot.add_widget(dialog)
|
||||
dialog.line_separator_line_edit.setText(" | ")
|
||||
assert dialog.transcription_options.line_separator == " | "
|
||||
|
||||
|
||||
class TestTranscriptionOptionsLineSeparator:
|
||||
def test_default_line_separator(self):
|
||||
options = TranscriptionOptions()
|
||||
assert options.line_separator == "\n\n"
|
||||
|
||||
def test_custom_line_separator(self):
|
||||
options = TranscriptionOptions(line_separator="\n")
|
||||
assert options.line_separator == "\n"
|
||||
|
||||
|
||||
class TestTranscriptionOptionsSilenceThreshold:
|
||||
def test_default_silence_threshold(self):
|
||||
options = TranscriptionOptions()
|
||||
assert options.silence_threshold == pytest.approx(0.0025)
|
||||
|
||||
def test_custom_silence_threshold(self):
|
||||
options = TranscriptionOptions(silence_threshold=0.01)
|
||||
assert options.silence_threshold == pytest.approx(0.01)
|
||||
|
|
@ -1,56 +0,0 @@
|
|||
import pytest
|
||||
from pytestqt.qtbot import QtBot
|
||||
|
||||
from buzz.widgets.audio_meter_widget import AudioMeterWidget
|
||||
|
||||
|
||||
class TestAudioMeterWidget:
|
||||
def test_initial_amplitude_is_zero(self, qtbot: QtBot):
|
||||
widget = AudioMeterWidget()
|
||||
qtbot.add_widget(widget)
|
||||
assert widget.current_amplitude == 0.0
|
||||
|
||||
def test_initial_average_amplitude_is_zero(self, qtbot: QtBot):
|
||||
widget = AudioMeterWidget()
|
||||
qtbot.add_widget(widget)
|
||||
assert widget.average_amplitude == 0.0
|
||||
|
||||
def test_update_amplitude(self, qtbot: QtBot):
|
||||
widget = AudioMeterWidget()
|
||||
qtbot.add_widget(widget)
|
||||
widget.update_amplitude(0.5)
|
||||
assert widget.current_amplitude == pytest.approx(0.5)
|
||||
|
||||
def test_update_amplitude_smoothing(self, qtbot: QtBot):
|
||||
"""Lower amplitude should decay via smoothing factor, not drop instantly."""
|
||||
widget = AudioMeterWidget()
|
||||
qtbot.add_widget(widget)
|
||||
widget.update_amplitude(1.0)
|
||||
widget.update_amplitude(0.0)
|
||||
# current_amplitude should be smoothed: max(0.0, 1.0 * SMOOTHING_FACTOR)
|
||||
assert widget.current_amplitude == pytest.approx(1.0 * widget.SMOOTHING_FACTOR)
|
||||
|
||||
def test_update_average_amplitude(self, qtbot: QtBot):
|
||||
widget = AudioMeterWidget()
|
||||
qtbot.add_widget(widget)
|
||||
widget.update_average_amplitude(0.0123)
|
||||
assert widget.average_amplitude == pytest.approx(0.0123)
|
||||
|
||||
def test_reset_amplitude_clears_current(self, qtbot: QtBot):
|
||||
widget = AudioMeterWidget()
|
||||
qtbot.add_widget(widget)
|
||||
widget.update_amplitude(0.8)
|
||||
widget.reset_amplitude()
|
||||
assert widget.current_amplitude == 0.0
|
||||
|
||||
def test_reset_amplitude_clears_average(self, qtbot: QtBot):
|
||||
widget = AudioMeterWidget()
|
||||
qtbot.add_widget(widget)
|
||||
widget.update_average_amplitude(0.05)
|
||||
widget.reset_amplitude()
|
||||
assert widget.average_amplitude == 0.0
|
||||
|
||||
def test_fixed_height(self, qtbot: QtBot):
|
||||
widget = AudioMeterWidget()
|
||||
qtbot.add_widget(widget)
|
||||
assert widget.height() == 56
|
||||
|
|
@ -1,22 +1,8 @@
|
|||
import gc
|
||||
import logging
|
||||
import pytest
|
||||
from unittest.mock import patch
|
||||
from buzz.settings.settings import Settings
|
||||
|
||||
|
||||
@pytest.fixture(autouse=True)
|
||||
def mock_get_password():
|
||||
with patch("buzz.widgets.recording_transcriber_widget.get_password", return_value=None):
|
||||
yield
|
||||
|
||||
|
||||
@pytest.fixture(autouse=True)
|
||||
def force_gc_between_tests():
|
||||
yield
|
||||
gc.collect()
|
||||
|
||||
|
||||
@pytest.fixture(scope="package")
|
||||
def reset_settings():
|
||||
settings = Settings()
|
||||
|
|
|
|||
|
|
@ -1,177 +0,0 @@
|
|||
import json
|
||||
from unittest.mock import MagicMock, patch
|
||||
|
||||
import pytest
|
||||
from PyQt6.QtCore import Qt, QEvent, QPoint
|
||||
from PyQt6.QtGui import QKeyEvent
|
||||
from PyQt6.QtNetwork import QNetworkReply, QNetworkAccessManager
|
||||
from PyQt6.QtWidgets import QListWidgetItem
|
||||
from pytestqt.qtbot import QtBot
|
||||
|
||||
from buzz.widgets.transcriber.hugging_face_search_line_edit import HuggingFaceSearchLineEdit
|
||||
|
||||
|
||||
@pytest.fixture
|
||||
def widget(qtbot: QtBot):
|
||||
mock_manager = MagicMock(spec=QNetworkAccessManager)
|
||||
mock_manager.finished = MagicMock()
|
||||
mock_manager.finished.connect = MagicMock()
|
||||
w = HuggingFaceSearchLineEdit(network_access_manager=mock_manager)
|
||||
qtbot.add_widget(w)
|
||||
# Prevent popup.show() from triggering a Wayland fatal protocol error
|
||||
# in headless/CI environments where popup windows lack a transient parent.
|
||||
w.popup.show = MagicMock()
|
||||
return w
|
||||
|
||||
|
||||
class TestHuggingFaceSearchLineEdit:
|
||||
def test_initial_state(self, widget):
|
||||
assert widget.text() == ""
|
||||
assert widget.placeholderText() != ""
|
||||
|
||||
def test_default_value_set(self, qtbot: QtBot):
|
||||
mock_manager = MagicMock(spec=QNetworkAccessManager)
|
||||
mock_manager.finished = MagicMock()
|
||||
mock_manager.finished.connect = MagicMock()
|
||||
w = HuggingFaceSearchLineEdit(default_value="openai/whisper-tiny", network_access_manager=mock_manager)
|
||||
qtbot.add_widget(w)
|
||||
assert w.text() == "openai/whisper-tiny"
|
||||
|
||||
def test_on_text_edited_emits_model_selected(self, widget, qtbot: QtBot):
|
||||
spy = MagicMock()
|
||||
widget.model_selected.connect(spy)
|
||||
widget.on_text_edited("some/model")
|
||||
spy.assert_called_once_with("some/model")
|
||||
|
||||
def test_fetch_models_skips_short_text(self, widget):
|
||||
widget.setText("ab")
|
||||
result = widget.fetch_models()
|
||||
assert result is None
|
||||
|
||||
def test_fetch_models_makes_request_for_long_text(self, widget):
|
||||
widget.setText("whisper-tiny")
|
||||
mock_reply = MagicMock()
|
||||
widget.network_manager.get = MagicMock(return_value=mock_reply)
|
||||
result = widget.fetch_models()
|
||||
widget.network_manager.get.assert_called_once()
|
||||
assert result == mock_reply
|
||||
|
||||
def test_fetch_models_url_contains_search_text(self, widget):
|
||||
widget.setText("whisper")
|
||||
widget.network_manager.get = MagicMock(return_value=MagicMock())
|
||||
widget.fetch_models()
|
||||
call_args = widget.network_manager.get.call_args[0][0]
|
||||
assert "whisper" in call_args.url().toString()
|
||||
|
||||
def test_on_request_response_network_error_does_not_populate_popup(self, widget):
|
||||
mock_reply = MagicMock(spec=QNetworkReply)
|
||||
mock_reply.error.return_value = QNetworkReply.NetworkError.ConnectionRefusedError
|
||||
widget.on_request_response(mock_reply)
|
||||
assert widget.popup.count() == 0
|
||||
|
||||
def test_on_request_response_populates_popup(self, widget):
|
||||
mock_reply = MagicMock(spec=QNetworkReply)
|
||||
mock_reply.error.return_value = QNetworkReply.NetworkError.NoError
|
||||
models = [{"id": "openai/whisper-tiny"}, {"id": "openai/whisper-base"}]
|
||||
mock_reply.readAll.return_value.data.return_value = json.dumps(models).encode()
|
||||
widget.on_request_response(mock_reply)
|
||||
assert widget.popup.count() == 2
|
||||
assert widget.popup.item(0).text() == "openai/whisper-tiny"
|
||||
assert widget.popup.item(1).text() == "openai/whisper-base"
|
||||
|
||||
def test_on_request_response_empty_models_does_not_show_popup(self, widget):
|
||||
mock_reply = MagicMock(spec=QNetworkReply)
|
||||
mock_reply.error.return_value = QNetworkReply.NetworkError.NoError
|
||||
mock_reply.readAll.return_value.data.return_value = json.dumps([]).encode()
|
||||
widget.on_request_response(mock_reply)
|
||||
assert widget.popup.count() == 0
|
||||
widget.popup.show.assert_not_called()
|
||||
|
||||
def test_on_request_response_item_has_user_role_data(self, widget):
|
||||
mock_reply = MagicMock(spec=QNetworkReply)
|
||||
mock_reply.error.return_value = QNetworkReply.NetworkError.NoError
|
||||
models = [{"id": "facebook/mms-1b-all"}]
|
||||
mock_reply.readAll.return_value.data.return_value = json.dumps(models).encode()
|
||||
widget.on_request_response(mock_reply)
|
||||
item = widget.popup.item(0)
|
||||
assert item.data(Qt.ItemDataRole.UserRole) == "facebook/mms-1b-all"
|
||||
|
||||
def test_on_select_item_emits_model_selected(self, widget, qtbot: QtBot):
|
||||
item = QListWidgetItem("openai/whisper-tiny")
|
||||
item.setData(Qt.ItemDataRole.UserRole, "openai/whisper-tiny")
|
||||
widget.popup.addItem(item)
|
||||
widget.popup.setCurrentItem(item)
|
||||
|
||||
spy = MagicMock()
|
||||
widget.model_selected.connect(spy)
|
||||
widget.on_select_item()
|
||||
|
||||
spy.assert_called_with("openai/whisper-tiny")
|
||||
assert widget.text() == "openai/whisper-tiny"
|
||||
|
||||
def test_on_select_item_hides_popup(self, widget):
|
||||
item = QListWidgetItem("openai/whisper-tiny")
|
||||
item.setData(Qt.ItemDataRole.UserRole, "openai/whisper-tiny")
|
||||
widget.popup.addItem(item)
|
||||
widget.popup.setCurrentItem(item)
|
||||
|
||||
with patch.object(widget.popup, 'hide') as mock_hide:
|
||||
widget.on_select_item()
|
||||
mock_hide.assert_called_once()
|
||||
|
||||
def test_on_popup_selected_stops_timer(self, widget):
|
||||
widget.timer.start()
|
||||
assert widget.timer.isActive()
|
||||
widget.on_popup_selected()
|
||||
assert not widget.timer.isActive()
|
||||
|
||||
def test_event_filter_ignores_non_popup_target(self, widget):
|
||||
other = MagicMock()
|
||||
event = MagicMock()
|
||||
assert widget.eventFilter(other, event) is False
|
||||
|
||||
def test_event_filter_mouse_press_hides_popup(self, widget):
|
||||
event = MagicMock()
|
||||
event.type.return_value = QEvent.Type.MouseButtonPress
|
||||
with patch.object(widget.popup, 'hide') as mock_hide:
|
||||
result = widget.eventFilter(widget.popup, event)
|
||||
assert result is True
|
||||
mock_hide.assert_called_once()
|
||||
|
||||
def test_event_filter_escape_hides_popup(self, widget, qtbot: QtBot):
|
||||
event = QKeyEvent(QEvent.Type.KeyPress, Qt.Key.Key_Escape, Qt.KeyboardModifier.NoModifier)
|
||||
with patch.object(widget.popup, 'hide') as mock_hide:
|
||||
result = widget.eventFilter(widget.popup, event)
|
||||
assert result is True
|
||||
mock_hide.assert_called_once()
|
||||
|
||||
def test_event_filter_enter_selects_item(self, widget, qtbot: QtBot):
|
||||
item = QListWidgetItem("openai/whisper-tiny")
|
||||
item.setData(Qt.ItemDataRole.UserRole, "openai/whisper-tiny")
|
||||
widget.popup.addItem(item)
|
||||
widget.popup.setCurrentItem(item)
|
||||
|
||||
spy = MagicMock()
|
||||
widget.model_selected.connect(spy)
|
||||
|
||||
event = QKeyEvent(QEvent.Type.KeyPress, Qt.Key.Key_Return, Qt.KeyboardModifier.NoModifier)
|
||||
result = widget.eventFilter(widget.popup, event)
|
||||
assert result is True
|
||||
spy.assert_called_with("openai/whisper-tiny")
|
||||
|
||||
def test_event_filter_enter_no_item_returns_true(self, widget, qtbot: QtBot):
|
||||
event = QKeyEvent(QEvent.Type.KeyPress, Qt.Key.Key_Return, Qt.KeyboardModifier.NoModifier)
|
||||
result = widget.eventFilter(widget.popup, event)
|
||||
assert result is True
|
||||
|
||||
def test_event_filter_navigation_keys_return_false(self, widget):
|
||||
for key in [Qt.Key.Key_Up, Qt.Key.Key_Down, Qt.Key.Key_Home,
|
||||
Qt.Key.Key_End, Qt.Key.Key_PageUp, Qt.Key.Key_PageDown]:
|
||||
event = QKeyEvent(QEvent.Type.KeyPress, key, Qt.KeyboardModifier.NoModifier)
|
||||
assert widget.eventFilter(widget.popup, event) is False
|
||||
|
||||
def test_event_filter_other_key_hides_popup(self, widget):
|
||||
event = QKeyEvent(QEvent.Type.KeyPress, Qt.Key.Key_A, Qt.KeyboardModifier.NoModifier)
|
||||
with patch.object(widget.popup, 'hide') as mock_hide:
|
||||
widget.eventFilter(widget.popup, event)
|
||||
mock_hide.assert_called_once()
|
||||
|
|
@ -1,6 +1,5 @@
|
|||
import logging
|
||||
import os
|
||||
import tempfile
|
||||
from typing import List
|
||||
from unittest.mock import patch, Mock
|
||||
|
||||
|
|
@ -294,67 +293,6 @@ class TestMainWindow:
|
|||
assert window.toolbar.open_transcript_action.isEnabled() is False
|
||||
window.close()
|
||||
|
||||
def test_import_folder_opens_file_transcriber_with_supported_files(
|
||||
self, qtbot, transcription_service
|
||||
):
|
||||
window = MainWindow(transcription_service)
|
||||
qtbot.add_widget(window)
|
||||
|
||||
with tempfile.TemporaryDirectory() as folder:
|
||||
# Create supported and unsupported files
|
||||
supported = ["audio.mp3", "video.mp4", "clip.wav"]
|
||||
unsupported = ["document.txt", "image.png"]
|
||||
subdir = os.path.join(folder, "sub")
|
||||
os.makedirs(subdir)
|
||||
nested = "nested.flac"
|
||||
|
||||
for name in supported + unsupported:
|
||||
open(os.path.join(folder, name), "w").close()
|
||||
open(os.path.join(subdir, nested), "w").close()
|
||||
|
||||
with patch("PyQt6.QtWidgets.QFileDialog.getExistingDirectory") as mock_dir, \
|
||||
patch.object(window, "open_file_transcriber_widget") as mock_open:
|
||||
mock_dir.return_value = folder
|
||||
window.on_import_folder_action_triggered()
|
||||
|
||||
collected = mock_open.call_args[0][0]
|
||||
collected_names = {os.path.basename(p) for p in collected}
|
||||
assert collected_names == {"audio.mp3", "video.mp4", "clip.wav", "nested.flac"}
|
||||
|
||||
window.close()
|
||||
|
||||
def test_import_folder_does_nothing_when_cancelled(
|
||||
self, qtbot, transcription_service
|
||||
):
|
||||
window = MainWindow(transcription_service)
|
||||
qtbot.add_widget(window)
|
||||
|
||||
with patch("PyQt6.QtWidgets.QFileDialog.getExistingDirectory") as mock_dir, \
|
||||
patch.object(window, "open_file_transcriber_widget") as mock_open:
|
||||
mock_dir.return_value = ""
|
||||
window.on_import_folder_action_triggered()
|
||||
|
||||
mock_open.assert_not_called()
|
||||
window.close()
|
||||
|
||||
def test_import_folder_does_nothing_when_no_supported_files(
|
||||
self, qtbot, transcription_service
|
||||
):
|
||||
window = MainWindow(transcription_service)
|
||||
qtbot.add_widget(window)
|
||||
|
||||
with tempfile.TemporaryDirectory() as folder:
|
||||
open(os.path.join(folder, "readme.txt"), "w").close()
|
||||
open(os.path.join(folder, "image.jpg"), "w").close()
|
||||
|
||||
with patch("PyQt6.QtWidgets.QFileDialog.getExistingDirectory") as mock_dir, \
|
||||
patch.object(window, "open_file_transcriber_widget") as mock_open:
|
||||
mock_dir.return_value = folder
|
||||
window.on_import_folder_action_triggered()
|
||||
|
||||
mock_open.assert_not_called()
|
||||
window.close()
|
||||
|
||||
@staticmethod
|
||||
def _import_file_and_start_transcription(
|
||||
window: MainWindow, long_audio: bool = False
|
||||
|
|
|
|||
|
|
@ -1,5 +1,3 @@
|
|||
from unittest.mock import patch, Mock
|
||||
|
||||
from PyQt6.QtCore import QSettings
|
||||
|
||||
from buzz.widgets.menu_bar import MenuBar
|
||||
|
|
@ -8,18 +6,6 @@ from buzz.widgets.preferences_dialog.preferences_dialog import PreferencesDialog
|
|||
|
||||
|
||||
class TestMenuBar:
|
||||
def test_import_folder_action_emits_signal(self, qtbot, shortcuts):
|
||||
menu_bar = MenuBar(
|
||||
shortcuts=shortcuts, preferences=Preferences.load(QSettings())
|
||||
)
|
||||
qtbot.add_widget(menu_bar)
|
||||
|
||||
signal_mock = Mock()
|
||||
menu_bar.import_folder_action_triggered.connect(signal_mock)
|
||||
menu_bar.import_folder_action.trigger()
|
||||
|
||||
signal_mock.assert_called_once()
|
||||
|
||||
def test_open_preferences_dialog(self, qtbot, shortcuts):
|
||||
menu_bar = MenuBar(
|
||||
shortcuts=shortcuts, preferences=Preferences.load(QSettings())
|
||||
|
|
|
|||
|
|
@ -3,7 +3,7 @@ from unittest.mock import Mock
|
|||
from PyQt6.QtWidgets import QCheckBox, QLineEdit
|
||||
|
||||
from buzz.model_loader import TranscriptionModel
|
||||
from buzz.transcriber.transcriber import Task
|
||||
from buzz.transcriber.transcriber import Task, DEFAULT_WHISPER_TEMPERATURE
|
||||
from buzz.widgets.preferences_dialog.folder_watch_preferences_widget import (
|
||||
FolderWatchPreferencesWidget,
|
||||
)
|
||||
|
|
@ -28,6 +28,7 @@ class TestFolderWatchPreferencesWidget:
|
|||
model=TranscriptionModel.default(),
|
||||
word_level_timings=False,
|
||||
extract_speech=False,
|
||||
temperature=DEFAULT_WHISPER_TEMPERATURE,
|
||||
initial_prompt="",
|
||||
enable_llm_translation=False,
|
||||
llm_model="",
|
||||
|
|
@ -47,12 +48,8 @@ class TestFolderWatchPreferencesWidget:
|
|||
assert not checkbox.isChecked()
|
||||
assert input_folder_line_edit.text() == ""
|
||||
assert output_folder_line_edit.text() == ""
|
||||
assert not input_folder_line_edit.isEnabled()
|
||||
assert not output_folder_line_edit.isEnabled()
|
||||
|
||||
checkbox.setChecked(True)
|
||||
assert input_folder_line_edit.isEnabled()
|
||||
assert output_folder_line_edit.isEnabled()
|
||||
input_folder_line_edit.setText("test/input/folder")
|
||||
output_folder_line_edit.setText("test/output/folder")
|
||||
|
||||
|
|
@ -60,41 +57,3 @@ class TestFolderWatchPreferencesWidget:
|
|||
assert last_config_changed_call[0][0].enabled
|
||||
assert last_config_changed_call[0][0].input_directory == "test/input/folder"
|
||||
assert last_config_changed_call[0][0].output_directory == "test/output/folder"
|
||||
|
||||
def test_delete_processed_files_checkbox(self, qtbot):
|
||||
widget = FolderWatchPreferencesWidget(
|
||||
config=FolderWatchPreferences(
|
||||
enabled=False,
|
||||
input_directory="",
|
||||
output_directory="",
|
||||
file_transcription_options=FileTranscriptionPreferences(
|
||||
language=None,
|
||||
task=Task.TRANSCRIBE,
|
||||
model=TranscriptionModel.default(),
|
||||
word_level_timings=False,
|
||||
extract_speech=False,
|
||||
initial_prompt="",
|
||||
enable_llm_translation=False,
|
||||
llm_model="",
|
||||
llm_prompt="",
|
||||
output_formats=set(),
|
||||
),
|
||||
),
|
||||
)
|
||||
mock_config_changed = Mock()
|
||||
widget.config_changed.connect(mock_config_changed)
|
||||
qtbot.add_widget(widget)
|
||||
|
||||
delete_checkbox = widget.findChild(QCheckBox, "DeleteProcessedFilesCheckbox")
|
||||
assert delete_checkbox is not None
|
||||
assert not delete_checkbox.isChecked()
|
||||
|
||||
delete_checkbox.setChecked(True)
|
||||
|
||||
last_config = mock_config_changed.call_args_list[-1][0][0]
|
||||
assert last_config.delete_processed_files is True
|
||||
|
||||
delete_checkbox.setChecked(False)
|
||||
|
||||
last_config = mock_config_changed.call_args_list[-1][0][0]
|
||||
assert last_config.delete_processed_files is False
|
||||
|
|
|
|||
|
|
@ -2,7 +2,6 @@ import os
|
|||
import time
|
||||
import pytest
|
||||
import platform
|
||||
|
||||
import tempfile
|
||||
|
||||
from unittest.mock import patch, MagicMock
|
||||
|
|
@ -58,7 +57,7 @@ class TestRecordingTranscriberWidget:
|
|||
widget.record_button.click()
|
||||
qtbot.wait_until(callback=assert_text_box_contains_text, timeout=60 * 1000)
|
||||
|
||||
with qtbot.wait_signal(widget.transcription_stopped, timeout=60 * 1000):
|
||||
with qtbot.wait_signal(widget.transcription_thread.finished, timeout=60 * 1000):
|
||||
widget.stop_recording()
|
||||
|
||||
assert len(widget.transcription_text_box.toPlainText()) > 0
|
||||
|
|
@ -104,7 +103,7 @@ class TestRecordingTranscriberWidget:
|
|||
widget.record_button.click()
|
||||
qtbot.wait_until(callback=assert_text_box_contains_text, timeout=60 * 1000)
|
||||
|
||||
with qtbot.wait_signal(widget.transcription_stopped, timeout=60 * 1000):
|
||||
with qtbot.wait_signal(widget.transcription_thread.finished, timeout=60 * 1000):
|
||||
widget.stop_recording()
|
||||
|
||||
assert len(widget.transcription_text_box.toPlainText()) > 0
|
||||
|
|
@ -178,7 +177,6 @@ class TestRecordingTranscriberWidget:
|
|||
qtbot.add_widget(widget)
|
||||
|
||||
widget.transcriber_mode = RecordingTranscriberMode.APPEND_AND_CORRECT
|
||||
widget.hide_unconfirmed = False
|
||||
|
||||
widget.on_next_transcription('Bienvenue dans la transcription en direct de Buzz.')
|
||||
assert widget.transcription_text_box.toPlainText() == 'Bienvenue dans la transcription en direct de Buzz.'
|
||||
|
|
@ -194,91 +192,6 @@ class TestRecordingTranscriberWidget:
|
|||
widget.close()
|
||||
|
||||
|
||||
class TestRecordingTranscriberWidgetLineSeparator:
|
||||
@pytest.mark.timeout(60)
|
||||
def test_line_separator_loaded_from_settings(self, qtbot: QtBot):
|
||||
settings = Settings()
|
||||
settings.set_value(Settings.Key.RECORDING_TRANSCRIBER_LINE_SEPARATOR, "\n")
|
||||
|
||||
with _widget_ctx(qtbot) as widget:
|
||||
assert widget.transcription_options.line_separator == "\n"
|
||||
|
||||
@pytest.mark.timeout(60)
|
||||
def test_line_separator_saved_on_close(self, qtbot: QtBot):
|
||||
settings = Settings()
|
||||
|
||||
with _widget_ctx(qtbot) as widget:
|
||||
widget.transcription_options.line_separator = " | "
|
||||
|
||||
assert settings.value(Settings.Key.RECORDING_TRANSCRIBER_LINE_SEPARATOR, "") == " | "
|
||||
|
||||
@pytest.mark.timeout(60)
|
||||
def test_line_separator_used_in_append_below(self, qtbot: QtBot):
|
||||
with _widget_ctx(qtbot) as widget:
|
||||
widget.transcription_options.line_separator = " | "
|
||||
widget.transcriber_mode = RecordingTranscriberMode.APPEND_BELOW
|
||||
widget.on_next_transcription("first")
|
||||
widget.on_next_transcription("second")
|
||||
assert widget.transcription_text_box.toPlainText() == "first | second"
|
||||
|
||||
@pytest.mark.timeout(60)
|
||||
def test_line_separator_used_in_append_above(self, qtbot: QtBot):
|
||||
with _widget_ctx(qtbot) as widget:
|
||||
widget.transcription_options.line_separator = " | "
|
||||
widget.transcriber_mode = RecordingTranscriberMode.APPEND_ABOVE
|
||||
widget.on_next_transcription("first")
|
||||
widget.on_next_transcription("second")
|
||||
assert widget.transcription_text_box.toPlainText() == "second | first | "
|
||||
|
||||
@pytest.mark.timeout(60)
|
||||
def test_line_separator_used_in_translation_append_below(self, qtbot: QtBot):
|
||||
with _widget_ctx(qtbot) as widget:
|
||||
widget.transcription_options.line_separator = " | "
|
||||
widget.transcriber_mode = RecordingTranscriberMode.APPEND_BELOW
|
||||
widget.on_next_translation("hello")
|
||||
widget.on_next_translation("world")
|
||||
assert widget.translation_text_box.toPlainText() == "hello | world"
|
||||
|
||||
|
||||
class TestRecordingTranscriberWidgetSilenceThreshold:
|
||||
@pytest.mark.timeout(60)
|
||||
def test_silence_threshold_loaded_from_settings(self, qtbot: QtBot):
|
||||
"""Silence threshold from settings is applied to transcription options."""
|
||||
settings = Settings()
|
||||
settings.set_value(Settings.Key.RECORDING_TRANSCRIBER_SILENCE_THRESHOLD, 0.007)
|
||||
|
||||
with (patch("sounddevice.InputStream", side_effect=MockInputStream),
|
||||
patch("buzz.transcriber.recording_transcriber.RecordingTranscriber.get_device_sample_rate",
|
||||
return_value=16_000),
|
||||
patch("sounddevice.check_input_settings")):
|
||||
widget = RecordingTranscriberWidget(custom_sounddevice=MockSoundDevice())
|
||||
qtbot.add_widget(widget)
|
||||
|
||||
assert widget.transcription_options.silence_threshold == pytest.approx(0.007)
|
||||
|
||||
time.sleep(0.5)
|
||||
widget.close()
|
||||
|
||||
@pytest.mark.timeout(60)
|
||||
def test_silence_threshold_saved_on_close(self, qtbot: QtBot):
|
||||
"""Silence threshold is persisted to settings when widget is closed."""
|
||||
settings = Settings()
|
||||
|
||||
with (patch("sounddevice.InputStream", side_effect=MockInputStream),
|
||||
patch("buzz.transcriber.recording_transcriber.RecordingTranscriber.get_device_sample_rate",
|
||||
return_value=16_000),
|
||||
patch("sounddevice.check_input_settings")):
|
||||
widget = RecordingTranscriberWidget(custom_sounddevice=MockSoundDevice())
|
||||
qtbot.add_widget(widget)
|
||||
|
||||
widget.transcription_options.silence_threshold = 0.009
|
||||
time.sleep(0.5)
|
||||
widget.close()
|
||||
|
||||
saved = settings.value(Settings.Key.RECORDING_TRANSCRIBER_SILENCE_THRESHOLD, 0.0)
|
||||
assert pytest.approx(float(saved)) == 0.009
|
||||
|
||||
|
||||
class TestRecordingTranscriberWidgetPresentation:
|
||||
"""Tests for presentation window related functionality"""
|
||||
|
||||
|
|
@ -557,89 +470,6 @@ class TestRecordingTranscriberWidgetPresentation:
|
|||
time.sleep(0.5)
|
||||
widget.close()
|
||||
|
||||
@pytest.mark.timeout(60)
|
||||
def test_on_copy_transcript_clicked_with_text(self, qtbot: QtBot):
|
||||
with (
|
||||
patch("sounddevice.InputStream", side_effect=MockInputStream),
|
||||
patch("sounddevice.check_input_settings"),
|
||||
patch(
|
||||
"buzz.transcriber.recording_transcriber.RecordingTranscriber.get_device_sample_rate",
|
||||
return_value=16_000,
|
||||
),
|
||||
):
|
||||
mock_clipboard = MagicMock()
|
||||
mock_app = MagicMock()
|
||||
mock_app.clipboard.return_value = mock_clipboard
|
||||
|
||||
widget = RecordingTranscriberWidget(custom_sounddevice=MockSoundDevice())
|
||||
qtbot.add_widget(widget)
|
||||
|
||||
widget.transcription_text_box.setPlainText("Hello world")
|
||||
widget.copy_actions_bar.show()
|
||||
|
||||
with patch("buzz.widgets.recording_transcriber_widget.QApplication.instance",
|
||||
return_value=mock_app):
|
||||
widget.on_copy_transcript_clicked()
|
||||
|
||||
mock_clipboard.setText.assert_called_once_with("Hello world")
|
||||
assert widget.copy_transcript_button.text() == _("Copied!")
|
||||
|
||||
time.sleep(0.5)
|
||||
widget.close()
|
||||
|
||||
@pytest.mark.timeout(60)
|
||||
def test_on_copy_transcript_clicked_without_text(self, qtbot: QtBot):
|
||||
"""Test that copy button handles empty transcript gracefully"""
|
||||
with (
|
||||
patch("sounddevice.InputStream", side_effect=MockInputStream),
|
||||
patch("sounddevice.check_input_settings"),
|
||||
patch("buzz.transcriber.recording_transcriber.RecordingTranscriber.get_device_sample_rate",
|
||||
return_value=16_000),
|
||||
):
|
||||
widget = RecordingTranscriberWidget(
|
||||
custom_sounddevice=MockSoundDevice()
|
||||
)
|
||||
qtbot.add_widget(widget)
|
||||
|
||||
widget.transcription_text_box.setPlainText("")
|
||||
widget.copy_actions_bar.show()
|
||||
|
||||
widget.on_copy_transcript_clicked()
|
||||
|
||||
assert widget.copy_transcript_button.text() == _("Nothing to copy!")
|
||||
|
||||
time.sleep(0.5)
|
||||
widget.close()
|
||||
|
||||
@pytest.mark.timeout(60)
|
||||
def test_copy_actions_bar_hidden_when_recording_starts(self, qtbot: QtBot):
|
||||
"""Test that copy actions bar hides when recording starts"""
|
||||
with (
|
||||
patch("sounddevice.InputStream", side_effect=MockInputStream),
|
||||
patch("sounddevice.check_input_settings"),
|
||||
patch("buzz.transcriber.recording_transcriber.RecordingTranscriber.get_device_sample_rate",
|
||||
return_value=16_000),
|
||||
):
|
||||
widget = RecordingTranscriberWidget(
|
||||
custom_sounddevice=MockSoundDevice()
|
||||
)
|
||||
widget.device_sample_rate = 16_000
|
||||
qtbot.add_widget(widget)
|
||||
|
||||
widget.copy_actions_bar.show()
|
||||
assert not widget.copy_actions_bar.isHidden()
|
||||
|
||||
# Mock start_recording to prevent actual recording threads from starting
|
||||
widget.current_status = widget.RecordingStatus.STOPPED
|
||||
with patch.object(widget, 'start_recording'):
|
||||
widget.on_record_button_clicked()
|
||||
|
||||
assert widget.copy_actions_bar.isHidden()
|
||||
|
||||
time.sleep(0.5)
|
||||
widget.close()
|
||||
|
||||
|
||||
@pytest.mark.timeout(60)
|
||||
def test_on_bg_color_clicked(self, qtbot: QtBot):
|
||||
"""Test that background color button opens color dialog and saves selection"""
|
||||
|
|
@ -795,665 +625,3 @@ class TestRecordingTranscriberWidgetPresentation:
|
|||
|
||||
time.sleep(0.5)
|
||||
widget.close()
|
||||
|
||||
import contextlib
|
||||
|
||||
@contextlib.contextmanager
|
||||
def _widget_ctx(qtbot):
|
||||
with (patch("sounddevice.InputStream", side_effect=MockInputStream),
|
||||
patch("buzz.transcriber.recording_transcriber.RecordingTranscriber.get_device_sample_rate",
|
||||
return_value=16_000),
|
||||
patch("sounddevice.check_input_settings")):
|
||||
widget = RecordingTranscriberWidget(custom_sounddevice=MockSoundDevice())
|
||||
qtbot.add_widget(widget)
|
||||
yield widget
|
||||
time.sleep(0.3)
|
||||
widget.close()
|
||||
|
||||
|
||||
class TestResetTranscriberControls:
|
||||
@pytest.mark.timeout(60)
|
||||
def test_record_button_disabled_for_faster_whisper_custom_without_hf_model(self, qtbot):
|
||||
from buzz.model_loader import TranscriptionModel, ModelType, WhisperModelSize
|
||||
from buzz.transcriber.transcriber import TranscriptionOptions
|
||||
|
||||
with _widget_ctx(qtbot) as widget:
|
||||
widget.transcription_options = TranscriptionOptions(
|
||||
model=TranscriptionModel(
|
||||
model_type=ModelType.FASTER_WHISPER,
|
||||
whisper_model_size=WhisperModelSize.CUSTOM,
|
||||
hugging_face_model_id="",
|
||||
)
|
||||
)
|
||||
widget.reset_transcriber_controls()
|
||||
assert not widget.record_button.isEnabled()
|
||||
|
||||
@pytest.mark.timeout(60)
|
||||
def test_record_button_disabled_for_hugging_face_without_model_id(self, qtbot):
|
||||
from buzz.model_loader import TranscriptionModel, ModelType
|
||||
from buzz.transcriber.transcriber import TranscriptionOptions
|
||||
|
||||
with _widget_ctx(qtbot) as widget:
|
||||
widget.transcription_options = TranscriptionOptions(
|
||||
model=TranscriptionModel(
|
||||
model_type=ModelType.HUGGING_FACE,
|
||||
hugging_face_model_id="",
|
||||
)
|
||||
)
|
||||
widget.reset_transcriber_controls()
|
||||
assert not widget.record_button.isEnabled()
|
||||
|
||||
@pytest.mark.timeout(60)
|
||||
def test_record_button_enabled_for_hugging_face_with_model_id(self, qtbot):
|
||||
from buzz.model_loader import TranscriptionModel, ModelType
|
||||
from buzz.transcriber.transcriber import TranscriptionOptions
|
||||
|
||||
with _widget_ctx(qtbot) as widget:
|
||||
widget.transcription_options = TranscriptionOptions(
|
||||
model=TranscriptionModel(
|
||||
model_type=ModelType.HUGGING_FACE,
|
||||
hugging_face_model_id="org/model",
|
||||
)
|
||||
)
|
||||
widget.reset_transcriber_controls()
|
||||
assert widget.record_button.isEnabled()
|
||||
|
||||
|
||||
|
||||
class TestOnTranscriptionOptionsChanged:
|
||||
@pytest.mark.timeout(60)
|
||||
def test_shows_translation_box_when_llm_enabled(self, qtbot):
|
||||
from buzz.transcriber.transcriber import TranscriptionOptions
|
||||
|
||||
with _widget_ctx(qtbot) as widget:
|
||||
options = TranscriptionOptions(enable_llm_translation=True)
|
||||
widget.on_transcription_options_changed(options)
|
||||
assert not widget.translation_text_box.isHidden()
|
||||
|
||||
@pytest.mark.timeout(60)
|
||||
def test_hides_translation_box_when_llm_disabled(self, qtbot):
|
||||
from buzz.transcriber.transcriber import TranscriptionOptions
|
||||
|
||||
with _widget_ctx(qtbot) as widget:
|
||||
widget.translation_text_box.show()
|
||||
options = TranscriptionOptions(enable_llm_translation=False)
|
||||
widget.on_transcription_options_changed(options)
|
||||
assert widget.translation_text_box.isHidden()
|
||||
|
||||
@pytest.mark.timeout(60)
|
||||
def test_updates_transcription_options(self, qtbot):
|
||||
from buzz.transcriber.transcriber import TranscriptionOptions
|
||||
|
||||
with _widget_ctx(qtbot) as widget:
|
||||
options = TranscriptionOptions(silence_threshold=0.05)
|
||||
widget.on_transcription_options_changed(options)
|
||||
assert widget.transcription_options.silence_threshold == pytest.approx(0.05)
|
||||
|
||||
|
||||
|
||||
def _model_loaded_ctx(qtbot, enable_llm_translation=False):
|
||||
from buzz.transcriber.transcriber import TranscriptionOptions
|
||||
ctx = _widget_ctx(qtbot)
|
||||
widget = ctx.__enter__.__self__ if hasattr(ctx, '__enter__') else None
|
||||
|
||||
class _Ctx:
|
||||
def __enter__(self_inner):
|
||||
self_inner.widget = ctx.__enter__()
|
||||
self_inner.widget.transcription_options = TranscriptionOptions(
|
||||
enable_llm_translation=enable_llm_translation
|
||||
)
|
||||
return self_inner.widget
|
||||
|
||||
def __exit__(self_inner, *args):
|
||||
return ctx.__exit__(*args)
|
||||
|
||||
return _Ctx()
|
||||
|
||||
|
||||
class TestTranslatorSetup:
|
||||
@pytest.mark.timeout(60)
|
||||
def test_translator_created_when_llm_enabled(self, qtbot):
|
||||
with _model_loaded_ctx(qtbot, enable_llm_translation=True) as widget, \
|
||||
patch("buzz.widgets.recording_transcriber_widget.Translator") as MockTranslator, \
|
||||
patch("buzz.widgets.recording_transcriber_widget.RecordingTranscriber"), \
|
||||
patch("buzz.widgets.recording_transcriber_widget.QThread"):
|
||||
widget.on_model_loaded("/fake/model/path")
|
||||
MockTranslator.assert_called_once()
|
||||
|
||||
@pytest.mark.timeout(60)
|
||||
def test_translator_not_created_when_llm_disabled(self, qtbot):
|
||||
with _model_loaded_ctx(qtbot, enable_llm_translation=False) as widget, \
|
||||
patch("buzz.widgets.recording_transcriber_widget.Translator") as MockTranslator, \
|
||||
patch("buzz.widgets.recording_transcriber_widget.RecordingTranscriber"), \
|
||||
patch("buzz.widgets.recording_transcriber_widget.QThread"):
|
||||
widget.on_model_loaded("/fake/model/path")
|
||||
MockTranslator.assert_not_called()
|
||||
|
||||
@pytest.mark.timeout(60)
|
||||
def test_translator_translation_signal_connected_to_on_next_translation(self, qtbot):
|
||||
with _model_loaded_ctx(qtbot, enable_llm_translation=True) as widget, \
|
||||
patch("buzz.widgets.recording_transcriber_widget.Translator") as MockTranslator, \
|
||||
patch("buzz.widgets.recording_transcriber_widget.RecordingTranscriber"), \
|
||||
patch("buzz.widgets.recording_transcriber_widget.QThread"):
|
||||
mock_translator_instance = MagicMock()
|
||||
MockTranslator.return_value = mock_translator_instance
|
||||
widget.on_model_loaded("/fake/model/path")
|
||||
mock_translator_instance.translation.connect.assert_called_with(widget.on_next_translation)
|
||||
|
||||
|
||||
class TestOnDeviceChanged:
|
||||
@pytest.mark.timeout(60)
|
||||
def test_no_new_listener_started_when_device_is_none(self, qtbot):
|
||||
with _widget_ctx(qtbot) as widget:
|
||||
with patch("buzz.widgets.recording_transcriber_widget.RecordingAmplitudeListener") as MockListener:
|
||||
widget.on_device_changed(None)
|
||||
MockListener.assert_not_called()
|
||||
|
||||
@pytest.mark.timeout(60)
|
||||
def test_no_new_listener_started_when_device_is_minus_one(self, qtbot):
|
||||
with _widget_ctx(qtbot) as widget:
|
||||
with patch("buzz.widgets.recording_transcriber_widget.RecordingAmplitudeListener") as MockListener:
|
||||
widget.on_device_changed(-1)
|
||||
MockListener.assert_not_called()
|
||||
|
||||
@pytest.mark.timeout(60)
|
||||
def test_device_id_updated(self, qtbot):
|
||||
with _widget_ctx(qtbot) as widget:
|
||||
widget.on_device_changed(-1)
|
||||
assert widget.selected_device_id == -1
|
||||
|
||||
|
||||
|
||||
class TestOnRecordButtonClickedStop:
|
||||
@pytest.mark.timeout(60)
|
||||
def test_stop_path_sets_status_stopped(self, qtbot):
|
||||
with _widget_ctx(qtbot) as widget:
|
||||
widget.current_status = widget.RecordingStatus.RECORDING
|
||||
with patch.object(widget, "stop_recording"), \
|
||||
patch.object(widget, "set_recording_status_stopped") as mock_stop:
|
||||
widget.on_record_button_clicked()
|
||||
mock_stop.assert_called_once()
|
||||
|
||||
@pytest.mark.timeout(60)
|
||||
def test_stop_path_hides_presentation_bar(self, qtbot):
|
||||
with _widget_ctx(qtbot) as widget:
|
||||
widget.presentation_options_bar.show()
|
||||
widget.current_status = widget.RecordingStatus.RECORDING
|
||||
with patch.object(widget, "stop_recording"):
|
||||
widget.on_record_button_clicked()
|
||||
assert widget.presentation_options_bar.isHidden()
|
||||
|
||||
|
||||
|
||||
class TestOnModelLoaded:
|
||||
@pytest.mark.timeout(60)
|
||||
def test_empty_model_path_calls_transcriber_error(self, qtbot):
|
||||
from buzz.model_loader import TranscriptionModel, ModelType
|
||||
from buzz.transcriber.transcriber import TranscriptionOptions
|
||||
|
||||
with _widget_ctx(qtbot) as widget:
|
||||
widget.transcription_options = TranscriptionOptions(
|
||||
model=TranscriptionModel(model_type=ModelType.FASTER_WHISPER)
|
||||
)
|
||||
with patch.object(widget, "on_transcriber_error") as mock_err, \
|
||||
patch.object(widget, "reset_recording_controls"):
|
||||
widget.on_model_loaded("")
|
||||
mock_err.assert_called_once_with("")
|
||||
|
||||
|
||||
|
||||
class TestOnTranscriberError:
|
||||
@pytest.mark.timeout(60)
|
||||
def test_shows_message_box(self, qtbot):
|
||||
with _widget_ctx(qtbot) as widget:
|
||||
with patch("buzz.widgets.recording_transcriber_widget.QMessageBox.critical") as mock_box, \
|
||||
patch.object(widget, "reset_record_button"), \
|
||||
patch.object(widget, "set_recording_status_stopped"), \
|
||||
patch.object(widget, "reset_recording_amplitude_listener"):
|
||||
widget.on_transcriber_error("some error")
|
||||
mock_box.assert_called_once()
|
||||
|
||||
@pytest.mark.timeout(60)
|
||||
def test_resets_record_button(self, qtbot):
|
||||
with _widget_ctx(qtbot) as widget:
|
||||
with patch("buzz.widgets.recording_transcriber_widget.QMessageBox.critical"), \
|
||||
patch.object(widget, "set_recording_status_stopped"), \
|
||||
patch.object(widget, "reset_recording_amplitude_listener"):
|
||||
widget.on_transcriber_error("err")
|
||||
assert widget.record_button.isEnabled()
|
||||
|
||||
|
||||
|
||||
class TestOnCancelModelProgressDialog:
|
||||
@pytest.mark.timeout(60)
|
||||
def test_cancels_model_loader(self, qtbot):
|
||||
with _widget_ctx(qtbot) as widget:
|
||||
mock_loader = MagicMock()
|
||||
widget.model_loader = mock_loader
|
||||
with patch.object(widget, "reset_model_download"), \
|
||||
patch.object(widget, "set_recording_status_stopped"), \
|
||||
patch.object(widget, "reset_recording_amplitude_listener"):
|
||||
widget.on_cancel_model_progress_dialog()
|
||||
mock_loader.cancel.assert_called_once()
|
||||
|
||||
@pytest.mark.timeout(60)
|
||||
def test_record_button_re_enabled(self, qtbot):
|
||||
with _widget_ctx(qtbot) as widget:
|
||||
widget.record_button.setDisabled(True)
|
||||
widget.model_loader = None
|
||||
with patch.object(widget, "reset_model_download"), \
|
||||
patch.object(widget, "set_recording_status_stopped"), \
|
||||
patch.object(widget, "reset_recording_amplitude_listener"):
|
||||
widget.on_cancel_model_progress_dialog()
|
||||
assert widget.record_button.isEnabled()
|
||||
|
||||
|
||||
|
||||
class TestOnNextTranscriptionExport:
|
||||
@pytest.mark.timeout(60)
|
||||
def test_append_below_writes_to_export_file(self, qtbot):
|
||||
with _widget_ctx(qtbot) as widget, tempfile.NamedTemporaryFile(
|
||||
suffix=".txt", delete=False, mode="w"
|
||||
) as f:
|
||||
export_path = f.name
|
||||
|
||||
try:
|
||||
widget.transcriber_mode = RecordingTranscriberMode.APPEND_BELOW
|
||||
widget.export_enabled = True
|
||||
widget.transcript_export_file = export_path
|
||||
widget.on_next_transcription("hello export")
|
||||
|
||||
with open(export_path) as f:
|
||||
assert "hello export" in f.read()
|
||||
finally:
|
||||
os.unlink(export_path)
|
||||
|
||||
@pytest.mark.timeout(60)
|
||||
def test_append_above_writes_to_export_file(self, qtbot):
|
||||
with _widget_ctx(qtbot) as widget, tempfile.NamedTemporaryFile(
|
||||
suffix=".txt", delete=False, mode="w"
|
||||
) as f:
|
||||
export_path = f.name
|
||||
|
||||
try:
|
||||
widget.transcriber_mode = RecordingTranscriberMode.APPEND_ABOVE
|
||||
widget.export_enabled = True
|
||||
widget.transcript_export_file = export_path
|
||||
widget.on_next_transcription("first")
|
||||
widget.on_next_transcription("second")
|
||||
|
||||
with open(export_path) as f:
|
||||
content = f.read()
|
||||
assert "second" in content
|
||||
assert "first" in content
|
||||
# APPEND_ABOVE puts newer text first
|
||||
assert content.index("second") < content.index("first")
|
||||
finally:
|
||||
os.unlink(export_path)
|
||||
|
||||
@pytest.mark.timeout(60)
|
||||
def test_append_above_csv_prepends_new_column(self, qtbot):
|
||||
import csv
|
||||
with _widget_ctx(qtbot) as widget, tempfile.NamedTemporaryFile(
|
||||
suffix=".csv", delete=False, mode="w"
|
||||
) as f:
|
||||
export_path = f.name
|
||||
|
||||
try:
|
||||
widget.transcriber_mode = RecordingTranscriberMode.APPEND_ABOVE
|
||||
widget.export_enabled = True
|
||||
widget.transcript_export_file = export_path
|
||||
widget.export_file_type = "csv"
|
||||
widget.on_next_transcription("first")
|
||||
widget.on_next_transcription("second")
|
||||
|
||||
with open(export_path, newline="") as f:
|
||||
rows = [r for r in csv.reader(f) if r]
|
||||
assert len(rows) == 1
|
||||
assert rows[0][0] == "second"
|
||||
assert rows[0][1] == "first"
|
||||
finally:
|
||||
os.unlink(export_path)
|
||||
|
||||
@pytest.mark.timeout(60)
|
||||
def test_append_above_csv_respects_max_entries(self, qtbot):
|
||||
import csv
|
||||
with _widget_ctx(qtbot) as widget, tempfile.NamedTemporaryFile(
|
||||
suffix=".csv", delete=False, mode="w"
|
||||
) as f:
|
||||
export_path = f.name
|
||||
|
||||
try:
|
||||
widget.transcriber_mode = RecordingTranscriberMode.APPEND_ABOVE
|
||||
widget.export_enabled = True
|
||||
widget.transcript_export_file = export_path
|
||||
widget.export_file_type = "csv"
|
||||
widget.export_max_entries = 2
|
||||
widget.on_next_transcription("first")
|
||||
widget.on_next_transcription("second")
|
||||
widget.on_next_transcription("third")
|
||||
|
||||
with open(export_path, newline="") as f:
|
||||
rows = [r for r in csv.reader(f) if r]
|
||||
assert len(rows) == 1
|
||||
assert len(rows[0]) == 2
|
||||
assert rows[0][0] == "third"
|
||||
assert rows[0][1] == "second"
|
||||
finally:
|
||||
os.unlink(export_path)
|
||||
|
||||
|
||||
|
||||
class TestUploadToServer:
|
||||
@pytest.mark.timeout(60)
|
||||
def test_transcript_uploaded_when_upload_url_set(self, qtbot):
|
||||
with _widget_ctx(qtbot) as widget, \
|
||||
patch("buzz.widgets.recording_transcriber_widget.requests.post") as mock_post:
|
||||
widget.upload_url = "http://example.com/upload"
|
||||
widget.on_next_transcription("hello upload")
|
||||
mock_post.assert_called_once_with(
|
||||
url="http://example.com/upload",
|
||||
json={"kind": "transcript", "text": "hello upload"},
|
||||
headers={"Content-Type": "application/json"},
|
||||
timeout=15,
|
||||
)
|
||||
|
||||
@pytest.mark.timeout(60)
|
||||
def test_transcript_not_uploaded_when_upload_url_empty(self, qtbot):
|
||||
with _widget_ctx(qtbot) as widget, \
|
||||
patch("buzz.widgets.recording_transcriber_widget.requests.post") as mock_post:
|
||||
widget.upload_url = ""
|
||||
widget.on_next_transcription("no upload")
|
||||
mock_post.assert_not_called()
|
||||
|
||||
@pytest.mark.timeout(60)
|
||||
def test_transcript_upload_failure_does_not_raise(self, qtbot):
|
||||
with _widget_ctx(qtbot) as widget, \
|
||||
patch("buzz.widgets.recording_transcriber_widget.requests.post",
|
||||
side_effect=Exception("connection error")):
|
||||
widget.upload_url = "http://example.com/upload"
|
||||
widget.on_next_transcription("hello") # should not raise
|
||||
|
||||
@pytest.mark.timeout(60)
|
||||
def test_translation_uploaded_when_upload_url_set(self, qtbot):
|
||||
with _widget_ctx(qtbot) as widget, \
|
||||
patch("buzz.widgets.recording_transcriber_widget.requests.post") as mock_post:
|
||||
widget.upload_url = "http://example.com/upload"
|
||||
widget.on_next_translation("bonjour")
|
||||
mock_post.assert_called_once_with(
|
||||
url="http://example.com/upload",
|
||||
json={"kind": "translation", "text": "bonjour"},
|
||||
headers={"Content-Type": "application/json"},
|
||||
timeout=15,
|
||||
)
|
||||
|
||||
|
||||
class TestOnNextTranslation:
|
||||
@pytest.mark.timeout(60)
|
||||
def test_append_below_adds_translation(self, qtbot):
|
||||
with _widget_ctx(qtbot) as widget:
|
||||
widget.transcriber_mode = RecordingTranscriberMode.APPEND_BELOW
|
||||
widget.on_next_translation("Bonjour")
|
||||
assert "Bonjour" in widget.translation_text_box.toPlainText()
|
||||
|
||||
@pytest.mark.timeout(60)
|
||||
def test_append_above_puts_new_text_first(self, qtbot):
|
||||
with _widget_ctx(qtbot) as widget:
|
||||
widget.transcriber_mode = RecordingTranscriberMode.APPEND_ABOVE
|
||||
widget.on_next_translation("first")
|
||||
widget.on_next_translation("second")
|
||||
text = widget.translation_text_box.toPlainText()
|
||||
assert text.index("second") < text.index("first")
|
||||
|
||||
@pytest.mark.timeout(60)
|
||||
def test_append_and_correct_merges_translation(self, qtbot):
|
||||
with _widget_ctx(qtbot) as widget:
|
||||
widget.transcriber_mode = RecordingTranscriberMode.APPEND_AND_CORRECT
|
||||
widget.hide_unconfirmed = False
|
||||
widget.on_next_translation("Hello world.")
|
||||
widget.on_next_translation("world. Goodbye.")
|
||||
text = widget.translation_text_box.toPlainText()
|
||||
assert "Hello" in text
|
||||
assert "Goodbye" in text
|
||||
|
||||
@pytest.mark.timeout(60)
|
||||
def test_empty_translation_ignored(self, qtbot):
|
||||
with _widget_ctx(qtbot) as widget:
|
||||
widget.transcriber_mode = RecordingTranscriberMode.APPEND_BELOW
|
||||
widget.on_next_translation("")
|
||||
assert widget.translation_text_box.toPlainText() == ""
|
||||
|
||||
@pytest.mark.timeout(60)
|
||||
def test_updates_presentation_window(self, qtbot):
|
||||
with _widget_ctx(qtbot) as widget:
|
||||
widget.transcriber_mode = RecordingTranscriberMode.APPEND_BELOW
|
||||
widget.on_show_presentation_clicked()
|
||||
widget.transcription_options.enable_llm_translation = True
|
||||
widget.on_next_translation("Translated text")
|
||||
assert "Translated text" in widget.presentation_window._current_translation
|
||||
|
||||
|
||||
|
||||
class TestExportFileHelpers:
|
||||
def test_write_creates_file(self, tmp_path):
|
||||
path = str(tmp_path / "out.txt")
|
||||
RecordingTranscriberWidget.write_to_export_file(path, "hello")
|
||||
with open(path) as f:
|
||||
assert f.read() == "hello"
|
||||
|
||||
def test_write_appends_by_default(self, tmp_path):
|
||||
path = str(tmp_path / "out.txt")
|
||||
RecordingTranscriberWidget.write_to_export_file(path, "line1")
|
||||
RecordingTranscriberWidget.write_to_export_file(path, "line2")
|
||||
with open(path) as f:
|
||||
assert f.read() == "line1line2"
|
||||
|
||||
def test_write_overwrites_with_mode_w(self, tmp_path):
|
||||
path = str(tmp_path / "out.txt")
|
||||
RecordingTranscriberWidget.write_to_export_file(path, "old", mode="w")
|
||||
RecordingTranscriberWidget.write_to_export_file(path, "new", mode="w")
|
||||
with open(path) as f:
|
||||
assert f.read() == "new"
|
||||
|
||||
def test_write_retries_on_permission_error(self, tmp_path):
|
||||
path = str(tmp_path / "out.txt")
|
||||
call_count = [0]
|
||||
original_open = open
|
||||
|
||||
def flaky_open(p, mode="r", **kwargs):
|
||||
if p == path:
|
||||
call_count[0] += 1
|
||||
if call_count[0] < 3:
|
||||
raise PermissionError("locked")
|
||||
return original_open(p, mode, **kwargs)
|
||||
|
||||
with patch("builtins.open", side_effect=flaky_open), \
|
||||
patch("time.sleep"):
|
||||
RecordingTranscriberWidget.write_to_export_file(path, "data", retries=5, delay=0)
|
||||
|
||||
assert call_count[0] == 3
|
||||
|
||||
def test_write_gives_up_after_max_retries(self, tmp_path):
|
||||
path = str(tmp_path / "out.txt")
|
||||
with patch("builtins.open", side_effect=PermissionError("locked")), \
|
||||
patch("time.sleep"):
|
||||
RecordingTranscriberWidget.write_to_export_file(path, "data", retries=3, delay=0)
|
||||
|
||||
def test_write_handles_oserror(self, tmp_path):
|
||||
path = str(tmp_path / "out.txt")
|
||||
with patch("builtins.open", side_effect=OSError("disk full")):
|
||||
RecordingTranscriberWidget.write_to_export_file(path, "data")
|
||||
|
||||
def test_read_returns_file_contents(self, tmp_path):
|
||||
path = str(tmp_path / "in.txt")
|
||||
with open(path, "w") as f:
|
||||
f.write("content")
|
||||
assert RecordingTranscriberWidget.read_export_file(path) == "content"
|
||||
|
||||
def test_read_retries_on_permission_error(self, tmp_path):
|
||||
path = str(tmp_path / "in.txt")
|
||||
with open(path, "w") as f:
|
||||
f.write("ok")
|
||||
call_count = [0]
|
||||
original_open = open
|
||||
|
||||
def flaky_open(p, mode="r", **kwargs):
|
||||
if p == path:
|
||||
call_count[0] += 1
|
||||
if call_count[0] < 2:
|
||||
raise PermissionError("locked")
|
||||
return original_open(p, mode, **kwargs)
|
||||
|
||||
with patch("builtins.open", side_effect=flaky_open), \
|
||||
patch("time.sleep"):
|
||||
result = RecordingTranscriberWidget.read_export_file(path, retries=5, delay=0)
|
||||
|
||||
assert result == "ok"
|
||||
|
||||
def test_read_returns_empty_string_on_oserror(self, tmp_path):
|
||||
path = str(tmp_path / "missing.txt")
|
||||
with patch("builtins.open", side_effect=OSError("not found")):
|
||||
assert RecordingTranscriberWidget.read_export_file(path) == ""
|
||||
|
||||
def test_read_returns_empty_string_after_max_retries(self, tmp_path):
|
||||
path = str(tmp_path / "locked.txt")
|
||||
with patch("builtins.open", side_effect=PermissionError("locked")), \
|
||||
patch("time.sleep"):
|
||||
result = RecordingTranscriberWidget.read_export_file(path, retries=2, delay=0)
|
||||
assert result == ""
|
||||
|
||||
|
||||
class TestWriteCsvExport:
|
||||
def test_creates_csv_with_single_entry(self, tmp_path):
|
||||
path = str(tmp_path / "out.csv")
|
||||
RecordingTranscriberWidget.write_csv_export(path, "hello", 0)
|
||||
with open(path, encoding="utf-8-sig") as f:
|
||||
content = f.read()
|
||||
assert "hello" in content
|
||||
|
||||
def test_appends_column_to_existing_csv(self, tmp_path):
|
||||
import csv
|
||||
path = str(tmp_path / "out.csv")
|
||||
RecordingTranscriberWidget.write_csv_export(path, "first", 0)
|
||||
RecordingTranscriberWidget.write_csv_export(path, "second", 0)
|
||||
with open(path, encoding="utf-8-sig") as f:
|
||||
rows = list(csv.reader(f))
|
||||
assert rows[0] == ["first", "second"]
|
||||
|
||||
def test_max_entries_limits_columns(self, tmp_path):
|
||||
import csv
|
||||
path = str(tmp_path / "out.csv")
|
||||
for word in ["a", "b", "c", "d"]:
|
||||
RecordingTranscriberWidget.write_csv_export(path, word, max_entries=3)
|
||||
with open(path, encoding="utf-8-sig") as f:
|
||||
rows = list(csv.reader(f))
|
||||
assert rows[0] == ["b", "c", "d"]
|
||||
|
||||
def test_max_entries_zero_means_no_limit(self, tmp_path):
|
||||
import csv
|
||||
path = str(tmp_path / "out.csv")
|
||||
for i in range(10):
|
||||
RecordingTranscriberWidget.write_csv_export(path, str(i), max_entries=0)
|
||||
with open(path, encoding="utf-8-sig") as f:
|
||||
rows = list(csv.reader(f))
|
||||
assert len(rows[0]) == 10
|
||||
|
||||
def test_handles_empty_existing_file(self, tmp_path):
|
||||
import csv
|
||||
path = str(tmp_path / "out.csv")
|
||||
with open(path, "w") as f:
|
||||
f.write("")
|
||||
RecordingTranscriberWidget.write_csv_export(path, "entry", 0)
|
||||
with open(path, encoding="utf-8-sig") as f:
|
||||
rows = list(csv.reader(f))
|
||||
assert rows[0] == ["entry"]
|
||||
|
||||
def test_retries_on_permission_error(self, tmp_path):
|
||||
path = str(tmp_path / "out.csv")
|
||||
call_count = [0]
|
||||
original_open = open
|
||||
|
||||
def flaky_open(p, mode="r", **kwargs):
|
||||
if p == path and "w" in mode:
|
||||
call_count[0] += 1
|
||||
if call_count[0] < 3:
|
||||
raise PermissionError("locked")
|
||||
return original_open(p, mode, **kwargs)
|
||||
|
||||
with patch("builtins.open", side_effect=flaky_open), \
|
||||
patch("time.sleep"):
|
||||
RecordingTranscriberWidget.write_csv_export(path, "data", 0)
|
||||
|
||||
assert call_count[0] == 3
|
||||
|
||||
|
||||
class TestWriteTxtExport:
|
||||
def test_append_mode_adds_text(self, tmp_path):
|
||||
path = str(tmp_path / "out.txt")
|
||||
RecordingTranscriberWidget.write_txt_export(path, "line1", "a", 0, "\n")
|
||||
RecordingTranscriberWidget.write_txt_export(path, "line2", "a", 0, "\n")
|
||||
with open(path) as f:
|
||||
content = f.read()
|
||||
assert content == "line1\nline2\n"
|
||||
|
||||
def test_append_mode_max_entries_trims_oldest(self, tmp_path):
|
||||
path = str(tmp_path / "out.txt")
|
||||
for word in ["a", "b", "c", "d"]:
|
||||
RecordingTranscriberWidget.write_txt_export(path, word, "a", max_entries=3, line_separator="\n")
|
||||
with open(path) as f:
|
||||
content = f.read()
|
||||
parts = [p for p in content.split("\n") if p]
|
||||
assert parts == ["b", "c", "d"]
|
||||
|
||||
def test_prepend_mode_puts_text_first(self, tmp_path):
|
||||
path = str(tmp_path / "out.txt")
|
||||
RecordingTranscriberWidget.write_txt_export(path, "first", "a", 0, "\n")
|
||||
RecordingTranscriberWidget.write_txt_export(path, "second", "prepend", 0, "\n")
|
||||
with open(path) as f:
|
||||
content = f.read()
|
||||
parts = [p for p in content.split("\n") if p]
|
||||
assert parts[0] == "second"
|
||||
assert parts[1] == "first"
|
||||
|
||||
def test_prepend_mode_max_entries_trims_oldest(self, tmp_path):
|
||||
path = str(tmp_path / "out.txt")
|
||||
RecordingTranscriberWidget.write_txt_export(path, "old1", "a", 0, "\n")
|
||||
RecordingTranscriberWidget.write_txt_export(path, "old2", "a", 0, "\n")
|
||||
RecordingTranscriberWidget.write_txt_export(path, "new", "prepend", max_entries=2, line_separator="\n")
|
||||
with open(path) as f:
|
||||
content = f.read()
|
||||
parts = [p for p in content.split("\n") if p]
|
||||
assert parts == ["new", "old1"]
|
||||
|
||||
def test_write_mode_overwrites(self, tmp_path):
|
||||
path = str(tmp_path / "out.txt")
|
||||
RecordingTranscriberWidget.write_txt_export(path, "old", "w", 0, "\n")
|
||||
RecordingTranscriberWidget.write_txt_export(path, "new", "w", 0, "\n")
|
||||
with open(path) as f:
|
||||
content = f.read()
|
||||
assert content == "new"
|
||||
|
||||
def test_prepend_on_nonexistent_file(self, tmp_path):
|
||||
path = str(tmp_path / "out.txt")
|
||||
RecordingTranscriberWidget.write_txt_export(path, "only", "prepend", 0, "\n")
|
||||
with open(path) as f:
|
||||
content = f.read()
|
||||
assert "only" in content
|
||||
|
||||
def test_append_max_entries_zero_means_no_limit(self, tmp_path):
|
||||
path = str(tmp_path / "out.txt")
|
||||
for i in range(10):
|
||||
RecordingTranscriberWidget.write_txt_export(path, str(i), "a", max_entries=0, line_separator="\n")
|
||||
with open(path) as f:
|
||||
parts = [p for p in f.read().split("\n") if p]
|
||||
assert len(parts) == 10
|
||||
|
||||
|
||||
class TestPresentationTranslationSync:
|
||||
@pytest.mark.timeout(60)
|
||||
def test_syncs_translation_when_llm_enabled(self, qtbot):
|
||||
with _widget_ctx(qtbot) as widget:
|
||||
widget.transcription_options.enable_llm_translation = True
|
||||
widget.translation_text_box.setPlainText("Translated content")
|
||||
widget.on_show_presentation_clicked()
|
||||
assert "Translated content" in widget.presentation_window._current_translation
|
||||
|
|
|
|||
|
|
@ -9,8 +9,8 @@ from buzz.db.entity.transcription import Transcription
|
|||
from buzz.db.entity.transcription_segment import TranscriptionSegment
|
||||
from buzz.model_loader import ModelType, WhisperModelSize
|
||||
from buzz.transcriber.transcriber import Task
|
||||
# Underlying libs do not support intel Macs or Windows (nemo C extensions crash on Windows CI)
|
||||
if not (platform.system() == "Darwin" and platform.machine() == "x86_64") and platform.system() != "Windows":
|
||||
# Underlying libs do not support intel Macs
|
||||
if not (platform.system() == "Darwin" and platform.machine() == "x86_64"):
|
||||
from buzz.widgets.transcription_viewer.speaker_identification_widget import (
|
||||
SpeakerIdentificationWidget,
|
||||
IdentificationWorker,
|
||||
|
|
@ -19,8 +19,8 @@ if not (platform.system() == "Darwin" and platform.machine() == "x86_64") and pl
|
|||
from tests.audio import test_audio_path
|
||||
|
||||
@pytest.mark.skipif(
|
||||
(platform.system() == "Darwin" and platform.machine() == "x86_64") or platform.system() == "Windows",
|
||||
reason="Speaker identification dependencies (nemo/texterrors C extensions) crash on Windows and are unsupported on Intel Mac"
|
||||
platform.system() == "Darwin" and platform.machine() == "x86_64",
|
||||
reason="Skip speaker identification tests on macOS x86_64"
|
||||
)
|
||||
class TestSpeakerIdentificationWidget:
|
||||
@pytest.fixture()
|
||||
|
|
@ -90,217 +90,6 @@ class TestSpeakerIdentificationWidget:
|
|||
assert (result == [[{'end_time': 8904, 'speaker': 'Speaker 0', 'start_time': 140, 'text': 'Bien venue dans. '}]]
|
||||
or result == [[{'end_time': 8904, 'speaker': 'Speaker 0', 'start_time': 140, 'text': 'Bienvenue dans. '}]])
|
||||
|
||||
def test_identify_button_toggles_visibility(self, qtbot: QtBot, transcription, transcription_service):
|
||||
widget = SpeakerIdentificationWidget(
|
||||
transcription=transcription,
|
||||
transcription_service=transcription_service,
|
||||
)
|
||||
qtbot.addWidget(widget)
|
||||
|
||||
# Before: identify visible, cancel hidden
|
||||
assert not widget.step_1_button.isHidden()
|
||||
assert widget.cancel_button.isHidden()
|
||||
|
||||
from PyQt6.QtCore import QThread as RealQThread
|
||||
mock_thread = MagicMock(spec=RealQThread)
|
||||
mock_thread.started = MagicMock()
|
||||
mock_thread.started.connect = MagicMock()
|
||||
|
||||
with patch.object(widget, '_cleanup_thread'), \
|
||||
patch('buzz.widgets.transcription_viewer.speaker_identification_widget.QThread', return_value=mock_thread), \
|
||||
patch.object(widget, 'worker', create=True):
|
||||
# patch moveToThread on IdentificationWorker to avoid type error
|
||||
with patch.object(IdentificationWorker, 'moveToThread'):
|
||||
widget.on_identify_button_clicked()
|
||||
|
||||
# After: identify hidden, cancel visible
|
||||
assert widget.step_1_button.isHidden()
|
||||
assert not widget.cancel_button.isHidden()
|
||||
|
||||
widget.close()
|
||||
|
||||
def test_cancel_button_resets_ui(self, qtbot: QtBot, transcription, transcription_service):
|
||||
widget = SpeakerIdentificationWidget(
|
||||
transcription=transcription,
|
||||
transcription_service=transcription_service,
|
||||
)
|
||||
qtbot.addWidget(widget)
|
||||
|
||||
# Simulate identification started
|
||||
widget.step_1_button.setVisible(False)
|
||||
widget.cancel_button.setVisible(True)
|
||||
|
||||
with patch.object(widget, '_cleanup_thread'):
|
||||
widget.on_cancel_button_clicked()
|
||||
|
||||
assert not widget.step_1_button.isHidden()
|
||||
assert widget.cancel_button.isHidden()
|
||||
assert widget.progress_bar.value() == 0
|
||||
assert len(widget.progress_label.text()) > 0
|
||||
|
||||
widget.close()
|
||||
|
||||
def test_on_progress_update_sets_label_and_bar(self, qtbot: QtBot, transcription, transcription_service):
|
||||
widget = SpeakerIdentificationWidget(
|
||||
transcription=transcription,
|
||||
transcription_service=transcription_service,
|
||||
)
|
||||
qtbot.addWidget(widget)
|
||||
|
||||
widget.on_progress_update("3/8 Loading alignment model")
|
||||
|
||||
assert widget.progress_label.text() == "3/8 Loading alignment model"
|
||||
assert widget.progress_bar.value() == 3
|
||||
|
||||
widget.close()
|
||||
|
||||
def test_on_progress_update_step_8_enables_save(self, qtbot: QtBot, transcription, transcription_service):
|
||||
widget = SpeakerIdentificationWidget(
|
||||
transcription=transcription,
|
||||
transcription_service=transcription_service,
|
||||
)
|
||||
qtbot.addWidget(widget)
|
||||
|
||||
assert not widget.save_button.isEnabled()
|
||||
|
||||
widget.on_progress_update("8/8 Identification done")
|
||||
|
||||
assert widget.save_button.isEnabled()
|
||||
assert widget.step_2_group_box.isEnabled()
|
||||
assert widget.merge_speaker_sentences.isEnabled()
|
||||
|
||||
widget.close()
|
||||
|
||||
def test_on_identification_finished_empty_result(self, qtbot: QtBot, transcription, transcription_service):
|
||||
widget = SpeakerIdentificationWidget(
|
||||
transcription=transcription,
|
||||
transcription_service=transcription_service,
|
||||
)
|
||||
qtbot.addWidget(widget)
|
||||
|
||||
initial_row_count = widget.speaker_preview_row.count()
|
||||
|
||||
widget.on_identification_finished([])
|
||||
|
||||
assert widget.identification_result == []
|
||||
# Empty result returns early — speaker preview row unchanged
|
||||
assert widget.speaker_preview_row.count() == initial_row_count
|
||||
|
||||
widget.close()
|
||||
|
||||
def test_on_identification_finished_populates_speakers(self, qtbot: QtBot, transcription, transcription_service):
|
||||
widget = SpeakerIdentificationWidget(
|
||||
transcription=transcription,
|
||||
transcription_service=transcription_service,
|
||||
)
|
||||
qtbot.addWidget(widget)
|
||||
|
||||
result = [
|
||||
{'speaker': 'Speaker 0', 'start_time': 0, 'end_time': 3000, 'text': 'Hello world.'},
|
||||
{'speaker': 'Speaker 1', 'start_time': 3000, 'end_time': 6000, 'text': 'Hi there.'},
|
||||
]
|
||||
widget.on_identification_finished(result)
|
||||
|
||||
assert widget.identification_result == result
|
||||
# Two speaker rows should have been created
|
||||
assert widget.speaker_preview_row.count() == 2
|
||||
|
||||
widget.close()
|
||||
|
||||
def test_on_identification_error_resets_buttons(self, qtbot: QtBot, transcription, transcription_service):
|
||||
widget = SpeakerIdentificationWidget(
|
||||
transcription=transcription,
|
||||
transcription_service=transcription_service,
|
||||
)
|
||||
qtbot.addWidget(widget)
|
||||
|
||||
widget.step_1_button.setVisible(False)
|
||||
widget.cancel_button.setVisible(True)
|
||||
|
||||
widget.on_identification_error("Some error")
|
||||
|
||||
assert not widget.step_1_button.isHidden()
|
||||
assert widget.cancel_button.isHidden()
|
||||
assert widget.progress_bar.value() == 0
|
||||
|
||||
widget.close()
|
||||
|
||||
def test_on_save_no_merge(self, qtbot: QtBot, transcription, transcription_service):
|
||||
widget = SpeakerIdentificationWidget(
|
||||
transcription=transcription,
|
||||
transcription_service=transcription_service,
|
||||
)
|
||||
qtbot.addWidget(widget)
|
||||
|
||||
result = [
|
||||
{'speaker': 'Speaker 0', 'start_time': 0, 'end_time': 2000, 'text': 'Hello.'},
|
||||
{'speaker': 'Speaker 0', 'start_time': 2000, 'end_time': 4000, 'text': 'World.'},
|
||||
{'speaker': 'Speaker 1', 'start_time': 4000, 'end_time': 6000, 'text': 'Hi.'},
|
||||
]
|
||||
widget.on_identification_finished(result)
|
||||
widget.merge_speaker_sentences.setChecked(False)
|
||||
|
||||
with patch.object(widget.transcription_service, 'copy_transcription', return_value=uuid.uuid4()) as mock_copy, \
|
||||
patch.object(widget.transcription_service, 'update_transcription_as_completed') as mock_update:
|
||||
widget.on_save_button_clicked()
|
||||
|
||||
mock_copy.assert_called_once()
|
||||
mock_update.assert_called_once()
|
||||
segments = mock_update.call_args[0][1]
|
||||
# No merge: 3 entries → 3 segments
|
||||
assert len(segments) == 3
|
||||
|
||||
widget.close()
|
||||
|
||||
def test_on_save_with_merge(self, qtbot: QtBot, transcription, transcription_service):
|
||||
widget = SpeakerIdentificationWidget(
|
||||
transcription=transcription,
|
||||
transcription_service=transcription_service,
|
||||
)
|
||||
qtbot.addWidget(widget)
|
||||
|
||||
result = [
|
||||
{'speaker': 'Speaker 0', 'start_time': 0, 'end_time': 2000, 'text': 'Hello.'},
|
||||
{'speaker': 'Speaker 0', 'start_time': 2000, 'end_time': 4000, 'text': 'World.'},
|
||||
{'speaker': 'Speaker 1', 'start_time': 4000, 'end_time': 6000, 'text': 'Hi.'},
|
||||
]
|
||||
widget.on_identification_finished(result)
|
||||
widget.merge_speaker_sentences.setChecked(True)
|
||||
|
||||
with patch.object(widget.transcription_service, 'copy_transcription', return_value=uuid.uuid4()), \
|
||||
patch.object(widget.transcription_service, 'update_transcription_as_completed') as mock_update:
|
||||
widget.on_save_button_clicked()
|
||||
|
||||
segments = mock_update.call_args[0][1]
|
||||
# Merge: two consecutive Speaker 0 entries → merged into 1; Speaker 1 → 1 = 2 total
|
||||
assert len(segments) == 2
|
||||
assert "Speaker 0" in segments[0].text
|
||||
assert "Hello." in segments[0].text
|
||||
assert "World." in segments[0].text
|
||||
|
||||
widget.close()
|
||||
|
||||
def test_on_save_emits_transcriptions_updated(self, qtbot: QtBot, transcription, transcription_service):
|
||||
updated_signal = MagicMock()
|
||||
widget = SpeakerIdentificationWidget(
|
||||
transcription=transcription,
|
||||
transcription_service=transcription_service,
|
||||
transcriptions_updated_signal=updated_signal,
|
||||
)
|
||||
qtbot.addWidget(widget)
|
||||
|
||||
result = [{'speaker': 'Speaker 0', 'start_time': 0, 'end_time': 1000, 'text': 'Hi.'}]
|
||||
widget.on_identification_finished(result)
|
||||
|
||||
new_id = uuid.uuid4()
|
||||
with patch.object(widget.transcription_service, 'copy_transcription', return_value=new_id), \
|
||||
patch.object(widget.transcription_service, 'update_transcription_as_completed'):
|
||||
widget.on_save_button_clicked()
|
||||
|
||||
updated_signal.emit.assert_called_once_with(new_id)
|
||||
|
||||
widget.close()
|
||||
|
||||
def test_batch_processing_with_many_words(self):
|
||||
"""Test batch processing when there are more than 200 words."""
|
||||
# Create mock punctuation model
|
||||
|
|
|
|||
|
|
@ -7,6 +7,7 @@ from pytestqt.qtbot import QtBot
|
|||
from buzz.model_loader import TranscriptionModel, ModelType
|
||||
from buzz.transcriber.transcriber import (
|
||||
Task,
|
||||
DEFAULT_WHISPER_TEMPERATURE,
|
||||
FileTranscriptionTask,
|
||||
TranscriptionOptions,
|
||||
FileTranscriptionOptions,
|
||||
|
|
@ -45,6 +46,7 @@ class TestTranscriptionTaskFolderWatcher:
|
|||
model=self.default_model(),
|
||||
word_level_timings=False,
|
||||
extract_speech=False,
|
||||
temperature=DEFAULT_WHISPER_TEMPERATURE,
|
||||
initial_prompt="",
|
||||
enable_llm_translation=False,
|
||||
llm_model="",
|
||||
|
|
@ -89,6 +91,7 @@ class TestTranscriptionTaskFolderWatcher:
|
|||
model=self.default_model(),
|
||||
word_level_timings=False,
|
||||
extract_speech=False,
|
||||
temperature=DEFAULT_WHISPER_TEMPERATURE,
|
||||
initial_prompt="",
|
||||
enable_llm_translation=False,
|
||||
llm_model="",
|
||||
|
|
@ -134,6 +137,7 @@ class TestTranscriptionTaskFolderWatcher:
|
|||
model=self.default_model(),
|
||||
word_level_timings=False,
|
||||
extract_speech=False,
|
||||
temperature=DEFAULT_WHISPER_TEMPERATURE,
|
||||
initial_prompt="",
|
||||
enable_llm_translation=False,
|
||||
llm_model="",
|
||||
|
|
@ -171,6 +175,7 @@ class TestTranscriptionTaskFolderWatcher:
|
|||
model=self.default_model(),
|
||||
word_level_timings=False,
|
||||
extract_speech=False,
|
||||
temperature=DEFAULT_WHISPER_TEMPERATURE,
|
||||
initial_prompt="",
|
||||
enable_llm_translation=False,
|
||||
llm_model="",
|
||||
|
|
@ -210,6 +215,7 @@ class TestTranscriptionTaskFolderWatcher:
|
|||
model=self.default_model(),
|
||||
word_level_timings=False,
|
||||
extract_speech=False,
|
||||
temperature=DEFAULT_WHISPER_TEMPERATURE,
|
||||
initial_prompt="",
|
||||
enable_llm_translation=False,
|
||||
llm_model="",
|
||||
|
|
@ -250,6 +256,7 @@ class TestTranscriptionTaskFolderWatcher:
|
|||
model=self.default_model(),
|
||||
word_level_timings=False,
|
||||
extract_speech=False,
|
||||
temperature=DEFAULT_WHISPER_TEMPERATURE,
|
||||
initial_prompt="",
|
||||
enable_llm_translation=False,
|
||||
llm_model="",
|
||||
|
|
@ -290,6 +297,7 @@ class TestTranscriptionTaskFolderWatcher:
|
|||
model=self.default_model(),
|
||||
word_level_timings=False,
|
||||
extract_speech=False,
|
||||
temperature=DEFAULT_WHISPER_TEMPERATURE,
|
||||
initial_prompt="",
|
||||
enable_llm_translation=False,
|
||||
llm_model="",
|
||||
|
|
@ -314,74 +322,6 @@ class TestTranscriptionTaskFolderWatcher:
|
|||
task: FileTranscriptionTask = blocker.args[0]
|
||||
assert task.file_path == os.path.join(input_directory, "whisper-french.mp3")
|
||||
|
||||
def test_should_set_delete_source_file_when_preference_enabled(self, qtbot: QtBot):
|
||||
input_directory = mkdtemp()
|
||||
output_directory = mkdtemp()
|
||||
|
||||
watcher = TranscriptionTaskFolderWatcher(
|
||||
tasks={},
|
||||
preferences=FolderWatchPreferences(
|
||||
enabled=True,
|
||||
input_directory=input_directory,
|
||||
output_directory=output_directory,
|
||||
delete_processed_files=True,
|
||||
file_transcription_options=FileTranscriptionPreferences(
|
||||
language=None,
|
||||
task=Task.TRANSCRIBE,
|
||||
model=self.default_model(),
|
||||
word_level_timings=False,
|
||||
extract_speech=False,
|
||||
initial_prompt="",
|
||||
enable_llm_translation=False,
|
||||
llm_model="",
|
||||
llm_prompt="",
|
||||
output_formats=set(),
|
||||
),
|
||||
),
|
||||
)
|
||||
|
||||
shutil.copy(test_audio_path, input_directory)
|
||||
|
||||
with qtbot.wait_signal(watcher.task_found, timeout=10_000) as blocker:
|
||||
pass
|
||||
|
||||
task: FileTranscriptionTask = blocker.args[0]
|
||||
assert task.delete_source_file is True
|
||||
|
||||
def test_should_not_set_delete_source_file_when_preference_disabled(self, qtbot: QtBot):
|
||||
input_directory = mkdtemp()
|
||||
output_directory = mkdtemp()
|
||||
|
||||
watcher = TranscriptionTaskFolderWatcher(
|
||||
tasks={},
|
||||
preferences=FolderWatchPreferences(
|
||||
enabled=True,
|
||||
input_directory=input_directory,
|
||||
output_directory=output_directory,
|
||||
delete_processed_files=False,
|
||||
file_transcription_options=FileTranscriptionPreferences(
|
||||
language=None,
|
||||
task=Task.TRANSCRIBE,
|
||||
model=self.default_model(),
|
||||
word_level_timings=False,
|
||||
extract_speech=False,
|
||||
initial_prompt="",
|
||||
enable_llm_translation=False,
|
||||
llm_model="",
|
||||
llm_prompt="",
|
||||
output_formats=set(),
|
||||
),
|
||||
),
|
||||
)
|
||||
|
||||
shutil.copy(test_audio_path, input_directory)
|
||||
|
||||
with qtbot.wait_signal(watcher.task_found, timeout=10_000) as blocker:
|
||||
pass
|
||||
|
||||
task: FileTranscriptionTask = blocker.args[0]
|
||||
assert task.delete_source_file is False
|
||||
|
||||
def test_should_set_original_file_path(self, qtbot: QtBot):
|
||||
input_directory = mkdtemp()
|
||||
output_directory = mkdtemp()
|
||||
|
|
@ -398,6 +338,7 @@ class TestTranscriptionTaskFolderWatcher:
|
|||
model=self.default_model(),
|
||||
word_level_timings=False,
|
||||
extract_speech=False,
|
||||
temperature=DEFAULT_WHISPER_TEMPERATURE,
|
||||
initial_prompt="",
|
||||
enable_llm_translation=False,
|
||||
llm_model="",
|
||||
|
|
|
|||
|
|
@ -13,7 +13,6 @@ from PyQt6.QtWidgets import QApplication, QMenu, QStyledItemDelegate
|
|||
from buzz.locale import _
|
||||
from buzz.widgets.transcription_tasks_table_widget import (
|
||||
TranscriptionTasksTableWidget,
|
||||
TranscriptionTasksTableHeaderView,
|
||||
format_record_status_text,
|
||||
Column,
|
||||
column_definitions,
|
||||
|
|
@ -454,281 +453,6 @@ class TestTranscriptionTasksTableWidget:
|
|||
# Verify error message was shown
|
||||
mock_messagebox.information.assert_called_once()
|
||||
|
||||
# --- on_restart_transcription_action edge cases ---
|
||||
|
||||
def test_restart_action_no_selection_does_nothing(self, widget, monkeypatch):
|
||||
mock_service = Mock()
|
||||
widget.transcription_service = mock_service
|
||||
# No row selected
|
||||
widget.on_restart_transcription_action()
|
||||
mock_service.reset_transcription_for_restart.assert_not_called()
|
||||
|
||||
def test_restart_action_canceled_status_succeeds(self, widget, monkeypatch):
|
||||
mock_service = Mock()
|
||||
widget.transcription_service = mock_service
|
||||
mock_transcription = Mock()
|
||||
mock_transcription.status = "canceled"
|
||||
mock_transcription.id = "12345678-1234-5678-1234-567812345678"
|
||||
monkeypatch.setattr(widget, "transcription", Mock(return_value=mock_transcription))
|
||||
mock_restart = Mock()
|
||||
monkeypatch.setattr(widget, "_restart_transcription_task", mock_restart)
|
||||
|
||||
widget.selectRow(0)
|
||||
widget.on_restart_transcription_action()
|
||||
|
||||
mock_service.reset_transcription_for_restart.assert_called_once()
|
||||
mock_restart.assert_called_once_with(mock_transcription)
|
||||
|
||||
def test_restart_action_service_exception_shows_warning(self, widget, monkeypatch):
|
||||
mock_service = Mock()
|
||||
mock_service.reset_transcription_for_restart.side_effect = RuntimeError("DB error")
|
||||
widget.transcription_service = mock_service
|
||||
mock_transcription = Mock()
|
||||
mock_transcription.status = "failed"
|
||||
mock_transcription.id = "12345678-1234-5678-1234-567812345678"
|
||||
monkeypatch.setattr(widget, "transcription", Mock(return_value=mock_transcription))
|
||||
|
||||
mock_messagebox = Mock()
|
||||
monkeypatch.setattr("PyQt6.QtWidgets.QMessageBox", mock_messagebox)
|
||||
|
||||
widget.selectRow(0)
|
||||
widget.on_restart_transcription_action()
|
||||
|
||||
mock_messagebox.warning.assert_called_once()
|
||||
|
||||
# --- _restart_transcription_task ---
|
||||
|
||||
def _make_transcription(self, **kwargs):
|
||||
from buzz.transcriber.transcriber import Task
|
||||
defaults = dict(
|
||||
id="12345678-1234-5678-1234-567812345678",
|
||||
status="failed",
|
||||
file="/audio/test.mp3",
|
||||
url=None,
|
||||
language="en",
|
||||
task=Task.TRANSCRIBE.value,
|
||||
model_type="Whisper",
|
||||
whisper_model_size="Tiny",
|
||||
hugging_face_model_id=None,
|
||||
word_level_timings="0",
|
||||
extract_speech="0",
|
||||
export_formats="txt",
|
||||
output_folder=None,
|
||||
source="FILE_IMPORT",
|
||||
)
|
||||
defaults.update(kwargs)
|
||||
t = Mock()
|
||||
for k, v in defaults.items():
|
||||
setattr(t, k, v)
|
||||
return t
|
||||
|
||||
def test_restart_task_happy_path_adds_task(self, widget, monkeypatch):
|
||||
from buzz.transcriber.transcriber import FileTranscriptionTask
|
||||
transcription = self._make_transcription()
|
||||
|
||||
mock_model_path = "/models/ggml-tiny.bin"
|
||||
mock_model = Mock()
|
||||
mock_model.get_local_model_path.return_value = mock_model_path
|
||||
|
||||
mock_transcription_model_cls = Mock(return_value=mock_model)
|
||||
monkeypatch.setattr("buzz.model_loader.TranscriptionModel", mock_transcription_model_cls)
|
||||
|
||||
mock_task_instance = Mock(spec=FileTranscriptionTask)
|
||||
mock_task_cls = Mock(return_value=mock_task_instance)
|
||||
monkeypatch.setattr(
|
||||
"buzz.transcriber.transcriber.FileTranscriptionTask", mock_task_cls
|
||||
)
|
||||
|
||||
mock_worker = Mock()
|
||||
mock_main_window = Mock()
|
||||
mock_main_window.transcriber_worker = mock_worker
|
||||
mock_main_window.parent.return_value = None
|
||||
monkeypatch.setattr(widget, "parent", Mock(return_value=mock_main_window))
|
||||
|
||||
widget._restart_transcription_task(transcription)
|
||||
|
||||
mock_worker.add_task.assert_called_once_with(mock_task_instance)
|
||||
|
||||
def test_restart_task_invalid_whisper_model_size_defaults_to_tiny(self, widget, monkeypatch):
|
||||
from buzz.model_loader import WhisperModelSize
|
||||
transcription = self._make_transcription(whisper_model_size="InvalidSize")
|
||||
|
||||
captured = {}
|
||||
|
||||
original_cls = __builtins__ # just a placeholder
|
||||
|
||||
def capture_model(**kwargs):
|
||||
captured["whisper_model_size"] = kwargs.get("whisper_model_size")
|
||||
m = Mock()
|
||||
m.get_local_model_path.return_value = "/fake/path"
|
||||
return m
|
||||
|
||||
monkeypatch.setattr(
|
||||
"buzz.model_loader.TranscriptionModel",
|
||||
Mock(side_effect=capture_model),
|
||||
)
|
||||
monkeypatch.setattr(
|
||||
"buzz.transcriber.transcriber.FileTranscriptionTask",
|
||||
Mock(return_value=Mock()),
|
||||
)
|
||||
mock_worker = Mock()
|
||||
mock_main_window = Mock()
|
||||
mock_main_window.transcriber_worker = mock_worker
|
||||
mock_main_window.parent.return_value = None
|
||||
monkeypatch.setattr(widget, "parent", Mock(return_value=mock_main_window))
|
||||
|
||||
widget._restart_transcription_task(transcription)
|
||||
|
||||
assert captured["whisper_model_size"] == WhisperModelSize.TINY
|
||||
|
||||
def test_restart_task_model_not_available_downloads_it(self, widget, monkeypatch):
|
||||
from buzz.transcriber.transcriber import FileTranscriptionTask
|
||||
transcription = self._make_transcription()
|
||||
|
||||
mock_model = Mock()
|
||||
mock_model.get_local_model_path.side_effect = [None, "/models/ggml-tiny.bin"]
|
||||
monkeypatch.setattr(
|
||||
"buzz.model_loader.TranscriptionModel",
|
||||
Mock(return_value=mock_model),
|
||||
)
|
||||
|
||||
mock_downloader = Mock()
|
||||
mock_downloader_cls = Mock(return_value=mock_downloader)
|
||||
monkeypatch.setattr(
|
||||
"buzz.model_loader.ModelDownloader",
|
||||
mock_downloader_cls,
|
||||
)
|
||||
monkeypatch.setattr(
|
||||
"buzz.transcriber.transcriber.FileTranscriptionTask",
|
||||
Mock(return_value=Mock()),
|
||||
)
|
||||
mock_worker = Mock()
|
||||
mock_main_window = Mock()
|
||||
mock_main_window.transcriber_worker = mock_worker
|
||||
mock_main_window.parent.return_value = None
|
||||
monkeypatch.setattr(widget, "parent", Mock(return_value=mock_main_window))
|
||||
|
||||
widget._restart_transcription_task(transcription)
|
||||
|
||||
mock_downloader.run.assert_called_once()
|
||||
mock_worker.add_task.assert_called_once()
|
||||
|
||||
def test_restart_task_model_unavailable_after_download_shows_warning(self, widget, monkeypatch):
|
||||
transcription = self._make_transcription()
|
||||
|
||||
mock_model = Mock()
|
||||
mock_model.get_local_model_path.return_value = None
|
||||
monkeypatch.setattr(
|
||||
"buzz.model_loader.TranscriptionModel",
|
||||
Mock(return_value=mock_model),
|
||||
)
|
||||
monkeypatch.setattr(
|
||||
"buzz.model_loader.ModelDownloader",
|
||||
Mock(return_value=Mock()),
|
||||
)
|
||||
|
||||
mock_messagebox = Mock()
|
||||
monkeypatch.setattr("PyQt6.QtWidgets.QMessageBox", mock_messagebox)
|
||||
|
||||
widget._restart_transcription_task(transcription)
|
||||
|
||||
mock_messagebox.warning.assert_called_once()
|
||||
|
||||
def test_restart_task_no_worker_found_shows_warning(self, widget, monkeypatch):
|
||||
transcription = self._make_transcription()
|
||||
|
||||
mock_model = Mock()
|
||||
mock_model.get_local_model_path.return_value = "/fake/path"
|
||||
monkeypatch.setattr(
|
||||
"buzz.model_loader.TranscriptionModel",
|
||||
Mock(return_value=mock_model),
|
||||
)
|
||||
monkeypatch.setattr(
|
||||
"buzz.transcriber.transcriber.FileTranscriptionTask",
|
||||
Mock(return_value=Mock()),
|
||||
)
|
||||
|
||||
# Parent with no transcriber_worker, and no further parent
|
||||
mock_parent = Mock(spec=["parent"]) # only has parent(), not transcriber_worker
|
||||
mock_parent.parent.return_value = None
|
||||
monkeypatch.setattr(widget, "parent", Mock(return_value=mock_parent))
|
||||
|
||||
mock_messagebox = Mock()
|
||||
monkeypatch.setattr("PyQt6.QtWidgets.QMessageBox", mock_messagebox)
|
||||
|
||||
widget._restart_transcription_task(transcription)
|
||||
|
||||
mock_messagebox.warning.assert_called_once()
|
||||
|
||||
def test_restart_task_export_formats_parsed_correctly(self, widget, monkeypatch):
|
||||
from buzz.transcriber.transcriber import OutputFormat
|
||||
transcription = self._make_transcription(export_formats="txt, srt")
|
||||
|
||||
captured = {}
|
||||
|
||||
def capture_file_transcription_options(**kwargs):
|
||||
captured["output_formats"] = kwargs.get("output_formats")
|
||||
return Mock()
|
||||
|
||||
monkeypatch.setattr(
|
||||
"buzz.transcriber.transcriber.FileTranscriptionOptions",
|
||||
Mock(side_effect=capture_file_transcription_options),
|
||||
)
|
||||
mock_model = Mock()
|
||||
mock_model.get_local_model_path.return_value = "/fake/path"
|
||||
monkeypatch.setattr(
|
||||
"buzz.model_loader.TranscriptionModel",
|
||||
Mock(return_value=mock_model),
|
||||
)
|
||||
monkeypatch.setattr(
|
||||
"buzz.transcriber.transcriber.FileTranscriptionTask",
|
||||
Mock(return_value=Mock()),
|
||||
)
|
||||
mock_worker = Mock()
|
||||
mock_main_window = Mock()
|
||||
mock_main_window.transcriber_worker = mock_worker
|
||||
mock_main_window.parent.return_value = None
|
||||
monkeypatch.setattr(widget, "parent", Mock(return_value=mock_main_window))
|
||||
|
||||
widget._restart_transcription_task(transcription)
|
||||
|
||||
assert OutputFormat("txt") in captured["output_formats"]
|
||||
assert OutputFormat("srt") in captured["output_formats"]
|
||||
|
||||
def test_restart_task_invalid_export_format_skipped(self, widget, monkeypatch):
|
||||
transcription = self._make_transcription(export_formats="txt, INVALID_FORMAT")
|
||||
|
||||
captured = {}
|
||||
|
||||
def capture_file_transcription_options(**kwargs):
|
||||
captured["output_formats"] = kwargs.get("output_formats")
|
||||
return Mock()
|
||||
|
||||
monkeypatch.setattr(
|
||||
"buzz.transcriber.transcriber.FileTranscriptionOptions",
|
||||
Mock(side_effect=capture_file_transcription_options),
|
||||
)
|
||||
mock_model = Mock()
|
||||
mock_model.get_local_model_path.return_value = "/fake/path"
|
||||
monkeypatch.setattr(
|
||||
"buzz.model_loader.TranscriptionModel",
|
||||
Mock(return_value=mock_model),
|
||||
)
|
||||
monkeypatch.setattr(
|
||||
"buzz.transcriber.transcriber.FileTranscriptionTask",
|
||||
Mock(return_value=Mock()),
|
||||
)
|
||||
mock_worker = Mock()
|
||||
mock_main_window = Mock()
|
||||
mock_main_window.transcriber_worker = mock_worker
|
||||
mock_main_window.parent.return_value = None
|
||||
monkeypatch.setattr(widget, "parent", Mock(return_value=mock_main_window))
|
||||
|
||||
widget._restart_transcription_task(transcription)
|
||||
|
||||
# Only the valid format should be present, invalid one skipped silently
|
||||
assert len(captured["output_formats"]) == 1
|
||||
|
||||
def test_column_resize_event(self, widget):
|
||||
"""Test column resize event handling"""
|
||||
# Mock the save_column_widths method
|
||||
|
|
@ -805,98 +529,3 @@ class TestTranscriptionTasksTableWidget:
|
|||
header = widget.horizontalHeader()
|
||||
assert header.sortIndicatorSection() == Column.TIME_QUEUED.value
|
||||
assert header.sortIndicatorOrder() == Qt.SortOrder.DescendingOrder
|
||||
|
||||
|
||||
class TestTranscriptionTasksTableHeaderView:
|
||||
@pytest.fixture
|
||||
def header(self, qtbot, widget):
|
||||
return widget.horizontalHeader()
|
||||
|
||||
def _setup_settings_key(self, widget):
|
||||
"""Set up settings.Key and restore begin_group side_effect for inline width-saving."""
|
||||
widget.settings.Key = Mock(
|
||||
TRANSCRIPTION_TASKS_TABLE_COLUMN_WIDTHS="widths"
|
||||
)
|
||||
current_group = [""]
|
||||
|
||||
def begin_group(group):
|
||||
current_group[0] = str(group) + "/"
|
||||
|
||||
def end_group():
|
||||
current_group[0] = ""
|
||||
|
||||
widget.settings.begin_group.side_effect = begin_group
|
||||
widget.settings.end_group.side_effect = end_group
|
||||
|
||||
def test_hiding_column_saves_visibility_and_widths(self, header, widget):
|
||||
col = Column.NOTES.value
|
||||
widget.setColumnWidth(col, 250)
|
||||
widget.setColumnHidden(col, False)
|
||||
self._setup_settings_key(widget)
|
||||
|
||||
with patch.object(widget, "save_column_visibility") as mock_vis, \
|
||||
patch.object(widget, "save_column_widths") as mock_widths, \
|
||||
patch.object(widget, "save_column_order"), \
|
||||
patch.object(widget, "reload_column_order_from_settings"):
|
||||
header.on_column_checked(col, False)
|
||||
|
||||
assert widget.isColumnHidden(col)
|
||||
mock_vis.assert_called()
|
||||
mock_widths.assert_called()
|
||||
|
||||
def test_showing_column_makes_it_visible(self, header, widget):
|
||||
col = Column.NOTES.value
|
||||
widget.setColumnHidden(col, True)
|
||||
|
||||
with patch.object(widget, "save_column_visibility"), \
|
||||
patch.object(widget, "save_column_widths"), \
|
||||
patch.object(widget, "save_column_order"), \
|
||||
patch.object(widget, "reload_column_order_from_settings"):
|
||||
header.on_column_checked(col, True)
|
||||
|
||||
assert not widget.isColumnHidden(col)
|
||||
|
||||
def test_hiding_already_hidden_column_does_not_save_zero_width(self, header, widget):
|
||||
col = Column.NOTES.value
|
||||
widget.setColumnHidden(col, True)
|
||||
self._setup_settings_key(widget)
|
||||
|
||||
saved_widths = {}
|
||||
|
||||
def capture_set_value(key, value):
|
||||
saved_widths[key] = value
|
||||
|
||||
widget.settings.settings.setValue.side_effect = capture_set_value
|
||||
|
||||
with patch.object(widget, "save_column_visibility"), \
|
||||
patch.object(widget, "save_column_widths"), \
|
||||
patch.object(widget, "save_column_order"), \
|
||||
patch.object(widget, "reload_column_order_from_settings"):
|
||||
header.on_column_checked(col, False)
|
||||
|
||||
# Width of a hidden column is 0 — should not be saved
|
||||
notes_id = next(d.id for d in column_definitions if d.column == Column.NOTES)
|
||||
assert notes_id not in saved_widths
|
||||
|
||||
def test_column_order_saved_on_visibility_change(self, header, widget):
|
||||
col = Column.NOTES.value
|
||||
self._setup_settings_key(widget)
|
||||
|
||||
with patch.object(widget, "save_column_visibility"), \
|
||||
patch.object(widget, "save_column_widths"), \
|
||||
patch.object(widget, "save_column_order") as mock_order, \
|
||||
patch.object(widget, "reload_column_order_from_settings"):
|
||||
header.on_column_checked(col, False)
|
||||
|
||||
mock_order.assert_called_once()
|
||||
|
||||
def test_reload_called_after_visibility_change(self, header, widget):
|
||||
col = Column.NOTES.value
|
||||
|
||||
with patch.object(widget, "save_column_visibility"), \
|
||||
patch.object(widget, "save_column_widths"), \
|
||||
patch.object(widget, "save_column_order"), \
|
||||
patch.object(widget, "reload_column_order_from_settings") as mock_reload:
|
||||
header.on_column_checked(col, True)
|
||||
|
||||
mock_reload.assert_called_once()
|
||||
|
|
|
|||
|
|
@ -778,13 +778,9 @@ class TestTranscriptionViewerWidgetAdditional:
|
|||
|
||||
widget.close()
|
||||
|
||||
@patch('buzz.translator.OpenAI')
|
||||
def test_run_translation(self, mock_openai, qtbot: QtBot, transcription, transcription_service, shortcuts):
|
||||
# TODO - it is sending actual requests, should mock
|
||||
def test_run_translation(self, qtbot: QtBot, transcription, transcription_service, shortcuts):
|
||||
"""Test run_translation method"""
|
||||
mock_openai.return_value.chat.completions.create.return_value = MagicMock(
|
||||
choices=[MagicMock(message=MagicMock(content="Translated text"))]
|
||||
)
|
||||
|
||||
widget = TranscriptionViewerWidget(
|
||||
transcription, transcription_service, shortcuts
|
||||
)
|
||||
|
|
@ -880,117 +876,3 @@ class TestTranscriptionViewerWidgetAdditional:
|
|||
assert widget.follow_audio_enabled == False
|
||||
|
||||
widget.close()
|
||||
|
||||
def test_on_transcript_segment_clicked(self, qtbot: QtBot, transcription, transcription_service, shortcuts):
|
||||
"""Test on_transcript_segment_clicked method"""
|
||||
widget = TranscriptionViewerWidget(
|
||||
transcription, transcription_service, shortcuts
|
||||
)
|
||||
qtbot.add_widget(widget)
|
||||
|
||||
# Without current media player - should return early
|
||||
widget.current_media_player = None
|
||||
segment = widget.table_widget.model().record(0)
|
||||
segment_mock = MagicMock()
|
||||
segment_mock.start_time = 100
|
||||
widget.on_transcript_segment_clicked(segment_mock)
|
||||
|
||||
# With current media player
|
||||
widget.current_media_player = widget.audio_player
|
||||
widget.on_transcript_segment_clicked(segment_mock)
|
||||
|
||||
assert hasattr(widget, 'on_transcript_segment_clicked')
|
||||
|
||||
widget.close()
|
||||
|
||||
def test_hide_loop_controls(self, qtbot: QtBot, transcription, transcription_service, shortcuts):
|
||||
"""Test hide_loop_controls method"""
|
||||
widget = TranscriptionViewerWidget(
|
||||
transcription, transcription_service, shortcuts
|
||||
)
|
||||
qtbot.add_widget(widget)
|
||||
widget.show()
|
||||
|
||||
widget.show_loop_controls()
|
||||
assert widget.loop_controls_frame.isVisible()
|
||||
|
||||
widget.hide_loop_controls()
|
||||
assert not widget.loop_controls_frame.isVisible()
|
||||
assert widget.playback_controls_visible is False
|
||||
|
||||
widget.close()
|
||||
|
||||
def test_toggle_playback_controls_visibility_hide(self, qtbot: QtBot, transcription, transcription_service, shortcuts):
|
||||
"""Test toggle_playback_controls_visibility hides controls when visible"""
|
||||
widget = TranscriptionViewerWidget(
|
||||
transcription, transcription_service, shortcuts
|
||||
)
|
||||
qtbot.add_widget(widget)
|
||||
widget.show()
|
||||
|
||||
widget.show_loop_controls()
|
||||
assert widget.loop_controls_frame.isVisible()
|
||||
|
||||
widget.toggle_playback_controls_visibility()
|
||||
assert not widget.loop_controls_frame.isVisible()
|
||||
|
||||
widget.close()
|
||||
|
||||
def test_toggle_audio_playback_when_playing(self, qtbot: QtBot, transcription, transcription_service, shortcuts):
|
||||
"""Test toggle_audio_playback pauses when playing"""
|
||||
widget = TranscriptionViewerWidget(
|
||||
transcription, transcription_service, shortcuts
|
||||
)
|
||||
qtbot.add_widget(widget)
|
||||
|
||||
# Mock media player in playing state
|
||||
with patch.object(
|
||||
widget.current_media_player.media_player,
|
||||
'playbackState',
|
||||
return_value=QMediaPlayer.PlaybackState.PlayingState
|
||||
):
|
||||
# Should call pause
|
||||
with patch.object(widget.current_media_player.media_player, 'pause') as mock_pause:
|
||||
widget.toggle_audio_playback()
|
||||
mock_pause.assert_called_once()
|
||||
|
||||
widget.close()
|
||||
|
||||
def test_video_player_initialization(self, qtbot: QtBot, transcription_dao, transcription_segment_dao, transcription_service, shortcuts):
|
||||
"""Test widget initialization with video file - verifies video player code path"""
|
||||
import uuid as uuid_mod
|
||||
from buzz.db.entity.transcription import Transcription
|
||||
from buzz.db.entity.transcription_segment import TranscriptionSegment
|
||||
from buzz.model_loader import ModelType, WhisperModelSize
|
||||
from buzz.transcriber.transcriber import Task
|
||||
|
||||
id = uuid_mod.uuid4()
|
||||
transcription_dao.insert(
|
||||
Transcription(
|
||||
id=str(id),
|
||||
status="completed",
|
||||
file="/fake/video.mp4",
|
||||
task=Task.TRANSCRIBE.value,
|
||||
model_type=ModelType.WHISPER.value,
|
||||
whisper_model_size=WhisperModelSize.TINY.value,
|
||||
)
|
||||
)
|
||||
transcription_segment_dao.insert(
|
||||
TranscriptionSegment(0, 500, "Test segment", "", str(id))
|
||||
)
|
||||
transcription = transcription_dao.find_by_id(str(id))
|
||||
|
||||
# Patch is_video_file to return True; let VideoPlayer construct normally
|
||||
# (it won't load media but the widget will be created)
|
||||
with patch('buzz.widgets.transcription_viewer.transcription_viewer_widget.is_video_file', return_value=True):
|
||||
widget = TranscriptionViewerWidget(
|
||||
transcription, transcription_service, shortcuts
|
||||
)
|
||||
qtbot.add_widget(widget)
|
||||
|
||||
# Video player should have been created and set as current
|
||||
assert widget.is_video is True
|
||||
assert widget.video_player is not None
|
||||
assert widget.current_media_player == widget.video_player
|
||||
|
||||
widget.close()
|
||||
|
|
|
|||
|
|
@ -1,238 +0,0 @@
|
|||
import platform
|
||||
from unittest.mock import patch, Mock
|
||||
|
||||
import pytest
|
||||
from PyQt6.QtNetwork import QNetworkReply
|
||||
from PyQt6.QtWidgets import QMessageBox
|
||||
from pytestqt.qtbot import QtBot
|
||||
|
||||
from buzz.locale import _
|
||||
from buzz.update_checker import UpdateInfo
|
||||
from buzz.widgets.update_dialog import UpdateDialog
|
||||
from tests.mock_qt import MockDownloadReply, MockDownloadNetworkManager
|
||||
|
||||
|
||||
UPDATE_INFO = UpdateInfo(
|
||||
version="99.0.0",
|
||||
release_notes="Some fixes.",
|
||||
download_urls=["https://example.com/Buzz-99.0.0.exe"],
|
||||
)
|
||||
|
||||
MULTI_FILE_UPDATE_INFO = UpdateInfo(
|
||||
version="99.0.0",
|
||||
release_notes="Multi-file release.",
|
||||
download_urls=[
|
||||
"https://example.com/Buzz-99.0.0.exe",
|
||||
"https://example.com/Buzz-99.0.0-1.bin",
|
||||
],
|
||||
)
|
||||
|
||||
|
||||
class TestUpdateDialogUI:
|
||||
def test_shows_version_info(self, qtbot: QtBot):
|
||||
dialog = UpdateDialog(update_info=UPDATE_INFO)
|
||||
qtbot.add_widget(dialog)
|
||||
|
||||
assert dialog.windowTitle() == _("Update Available")
|
||||
assert "99.0.0" in dialog.findChild(
|
||||
__import__("PyQt6.QtWidgets", fromlist=["QLabel"]).QLabel,
|
||||
""
|
||||
).__class__.__name__ or True # title check is sufficient
|
||||
|
||||
def test_download_button_is_present(self, qtbot: QtBot):
|
||||
dialog = UpdateDialog(update_info=UPDATE_INFO)
|
||||
qtbot.add_widget(dialog)
|
||||
assert dialog.download_button.text() == _("Download and Install")
|
||||
|
||||
def test_progress_bar_hidden_initially(self, qtbot: QtBot):
|
||||
dialog = UpdateDialog(update_info=UPDATE_INFO)
|
||||
qtbot.add_widget(dialog)
|
||||
assert dialog.progress_bar.isHidden()
|
||||
|
||||
def test_status_label_empty_initially(self, qtbot: QtBot):
|
||||
dialog = UpdateDialog(update_info=UPDATE_INFO)
|
||||
qtbot.add_widget(dialog)
|
||||
assert dialog.status_label.text() == ""
|
||||
|
||||
|
||||
class TestUpdateDialogDownload:
|
||||
def test_shows_warning_when_no_download_urls(self, qtbot: QtBot):
|
||||
info = UpdateInfo(version="99.0.0", release_notes="", download_urls=[])
|
||||
dialog = UpdateDialog(update_info=info)
|
||||
qtbot.add_widget(dialog)
|
||||
|
||||
mock_warning = Mock()
|
||||
with patch.object(QMessageBox, "warning", mock_warning):
|
||||
dialog.download_button.click()
|
||||
|
||||
mock_warning.assert_called_once()
|
||||
assert _("No download URL available for your platform.") in mock_warning.call_args[0]
|
||||
|
||||
def test_download_button_disabled_after_click(self, qtbot: QtBot):
|
||||
reply = MockDownloadReply(data=b"fake-exe-data")
|
||||
manager = MockDownloadNetworkManager(replies=[reply])
|
||||
dialog = UpdateDialog(update_info=UPDATE_INFO, network_manager=manager)
|
||||
qtbot.add_widget(dialog)
|
||||
|
||||
with patch.object(platform, "system", return_value="Windows"), \
|
||||
patch("subprocess.Popen"), \
|
||||
patch("buzz.widgets.update_dialog.QApplication"):
|
||||
dialog.download_button.click()
|
||||
reply.emit_finished()
|
||||
|
||||
assert not dialog.download_button.isEnabled()
|
||||
|
||||
def test_progress_bar_shown_after_download_starts(self, qtbot: QtBot):
|
||||
reply = MockDownloadReply(data=b"fake-exe-data")
|
||||
manager = MockDownloadNetworkManager(replies=[reply])
|
||||
dialog = UpdateDialog(update_info=UPDATE_INFO, network_manager=manager)
|
||||
qtbot.add_widget(dialog)
|
||||
|
||||
dialog.download_button.click()
|
||||
assert not dialog.progress_bar.isHidden()
|
||||
|
||||
def test_progress_bar_updates_on_progress(self, qtbot: QtBot):
|
||||
reply = MockDownloadReply(data=b"x" * (5 * 1024 * 1024))
|
||||
manager = MockDownloadNetworkManager(replies=[reply])
|
||||
dialog = UpdateDialog(update_info=UPDATE_INFO, network_manager=manager)
|
||||
qtbot.add_widget(dialog)
|
||||
|
||||
dialog.download_button.click()
|
||||
reply.downloadProgress.emit(5 * 1024 * 1024, 10 * 1024 * 1024)
|
||||
|
||||
assert dialog.progress_bar.value() == 50
|
||||
assert "5.0 MB" in dialog.status_label.text()
|
||||
|
||||
def test_single_file_download_runs_installer_on_windows(self, qtbot: QtBot):
|
||||
reply = MockDownloadReply(data=b"fake-exe-data")
|
||||
manager = MockDownloadNetworkManager(replies=[reply])
|
||||
dialog = UpdateDialog(update_info=UPDATE_INFO, network_manager=manager)
|
||||
qtbot.add_widget(dialog)
|
||||
|
||||
mock_popen = Mock()
|
||||
mock_quit = Mock()
|
||||
with patch.object(platform, "system", return_value="Windows"), \
|
||||
patch("subprocess.Popen", mock_popen), \
|
||||
patch("buzz.widgets.update_dialog.QApplication") as mock_app:
|
||||
mock_app.quit = mock_quit
|
||||
dialog.download_button.click()
|
||||
reply.emit_finished()
|
||||
|
||||
mock_popen.assert_called_once()
|
||||
installer_path = mock_popen.call_args[0][0][0]
|
||||
assert installer_path.endswith(".exe")
|
||||
|
||||
def test_single_file_download_opens_dmg_on_macos(self, qtbot: QtBot):
|
||||
macos_info = UpdateInfo(
|
||||
version="99.0.0",
|
||||
release_notes="",
|
||||
download_urls=["https://example.com/Buzz-99.0.0-arm.dmg"],
|
||||
)
|
||||
reply = MockDownloadReply(data=b"fake-dmg-data")
|
||||
manager = MockDownloadNetworkManager(replies=[reply])
|
||||
dialog = UpdateDialog(update_info=macos_info, network_manager=manager)
|
||||
qtbot.add_widget(dialog)
|
||||
|
||||
mock_popen = Mock()
|
||||
with patch.object(platform, "system", return_value="Darwin"), \
|
||||
patch("subprocess.Popen", mock_popen), \
|
||||
patch("buzz.widgets.update_dialog.QApplication"):
|
||||
dialog.download_button.click()
|
||||
reply.emit_finished()
|
||||
|
||||
mock_popen.assert_called_once()
|
||||
assert mock_popen.call_args[0][0][0] == "open"
|
||||
installer_path = mock_popen.call_args[0][0][1]
|
||||
assert installer_path.endswith(".dmg")
|
||||
|
||||
def test_multi_file_download_downloads_sequentially(self, qtbot: QtBot):
|
||||
reply1 = MockDownloadReply(data=b"installer-exe")
|
||||
reply2 = MockDownloadReply(data=b"installer-bin")
|
||||
manager = MockDownloadNetworkManager(replies=[reply1, reply2])
|
||||
dialog = UpdateDialog(update_info=MULTI_FILE_UPDATE_INFO, network_manager=manager)
|
||||
qtbot.add_widget(dialog)
|
||||
|
||||
mock_popen = Mock()
|
||||
with patch.object(platform, "system", return_value="Windows"), \
|
||||
patch("subprocess.Popen", mock_popen), \
|
||||
patch("buzz.widgets.update_dialog.QApplication"):
|
||||
dialog.download_button.click()
|
||||
# First file done
|
||||
reply1.emit_finished()
|
||||
# Second file done
|
||||
reply2.emit_finished()
|
||||
|
||||
assert len(dialog._temp_file_paths) == 2
|
||||
assert dialog._temp_file_paths[0].endswith(".exe")
|
||||
assert dialog._temp_file_paths[1].endswith(".bin")
|
||||
mock_popen.assert_called_once()
|
||||
|
||||
def test_status_shows_file_count_during_multi_file_download(self, qtbot: QtBot):
|
||||
reply1 = MockDownloadReply(data=b"installer-exe")
|
||||
reply2 = MockDownloadReply(data=b"installer-bin")
|
||||
manager = MockDownloadNetworkManager(replies=[reply1, reply2])
|
||||
dialog = UpdateDialog(update_info=MULTI_FILE_UPDATE_INFO, network_manager=manager)
|
||||
qtbot.add_widget(dialog)
|
||||
|
||||
dialog.download_button.click()
|
||||
assert "1" in dialog.status_label.text()
|
||||
assert "2" in dialog.status_label.text()
|
||||
|
||||
def test_progress_bar_reaches_100_after_all_downloads(self, qtbot: QtBot):
|
||||
reply = MockDownloadReply(data=b"fake-exe-data")
|
||||
manager = MockDownloadNetworkManager(replies=[reply])
|
||||
dialog = UpdateDialog(update_info=UPDATE_INFO, network_manager=manager)
|
||||
qtbot.add_widget(dialog)
|
||||
|
||||
with patch.object(platform, "system", return_value="Windows"), \
|
||||
patch("subprocess.Popen"), \
|
||||
patch("buzz.widgets.update_dialog.QApplication"):
|
||||
dialog.download_button.click()
|
||||
reply.emit_finished()
|
||||
|
||||
assert dialog.progress_bar.value() == 100
|
||||
assert dialog.status_label.text() == _("Download complete!")
|
||||
|
||||
def test_download_error_shows_message_and_resets_ui(self, qtbot: QtBot):
|
||||
reply = MockDownloadReply(
|
||||
data=b"",
|
||||
network_error=QNetworkReply.NetworkError.ConnectionRefusedError,
|
||||
error_string="Connection refused",
|
||||
)
|
||||
manager = MockDownloadNetworkManager(replies=[reply])
|
||||
dialog = UpdateDialog(update_info=UPDATE_INFO, network_manager=manager)
|
||||
qtbot.add_widget(dialog)
|
||||
|
||||
mock_critical = Mock()
|
||||
with patch.object(QMessageBox, "critical", mock_critical):
|
||||
dialog.download_button.click()
|
||||
reply.emit_finished()
|
||||
|
||||
mock_critical.assert_called_once()
|
||||
assert "Connection refused" in str(mock_critical.call_args)
|
||||
assert dialog.download_button.isEnabled()
|
||||
assert dialog.progress_bar.isHidden()
|
||||
|
||||
def test_save_error_shows_message_and_resets_ui(self, qtbot: QtBot):
|
||||
reply = MockDownloadReply(data=b"fake-data")
|
||||
manager = MockDownloadNetworkManager(replies=[reply])
|
||||
dialog = UpdateDialog(update_info=UPDATE_INFO, network_manager=manager)
|
||||
qtbot.add_widget(dialog)
|
||||
|
||||
mock_critical = Mock()
|
||||
with patch.object(QMessageBox, "critical", mock_critical), \
|
||||
patch("buzz.widgets.update_dialog.open", side_effect=OSError("Disk full")):
|
||||
dialog.download_button.click()
|
||||
reply.emit_finished()
|
||||
|
||||
mock_critical.assert_called_once()
|
||||
assert dialog.download_button.isEnabled()
|
||||
|
||||
def test_download_reply_stored_while_in_progress(self, qtbot: QtBot):
|
||||
reply = MockDownloadReply(data=b"fake-data")
|
||||
manager = MockDownloadNetworkManager(replies=[reply])
|
||||
dialog = UpdateDialog(update_info=UPDATE_INFO, network_manager=manager)
|
||||
qtbot.add_widget(dialog)
|
||||
|
||||
dialog.download_button.click()
|
||||
assert dialog._download_reply is reply
|
||||
33
uv.lock
generated
33
uv.lock
generated
|
|
@ -274,7 +274,7 @@ wheels = [
|
|||
|
||||
[[package]]
|
||||
name = "buzz-captions"
|
||||
version = "1.4.4"
|
||||
version = "1.4.3"
|
||||
source = { editable = "." }
|
||||
dependencies = [
|
||||
{ name = "accelerate" },
|
||||
|
|
@ -435,7 +435,7 @@ requires-dist = [
|
|||
{ name = "urllib3", specifier = ">=2.6.0,<3" },
|
||||
{ name = "uroman", specifier = ">=1.3.1.1" },
|
||||
{ name = "vulkan", specifier = ">=1.3.275.1,<2" },
|
||||
{ name = "yt-dlp", specifier = ">=2026.2.21" },
|
||||
{ name = "yt-dlp", specifier = ">=2025.11.12,<2026" },
|
||||
]
|
||||
|
||||
[package.metadata.requires-dev]
|
||||
|
|
@ -1132,6 +1132,7 @@ wheels = [
|
|||
{ url = "https://files.pythonhosted.org/packages/f8/0a/a3871375c7b9727edaeeea994bfff7c63ff7804c9829c19309ba2e058807/greenlet-3.3.0-cp312-cp312-macosx_11_0_universal2.whl", hash = "sha256:b01548f6e0b9e9784a2c99c5651e5dc89ffcbe870bc5fb2e5ef864e9cc6b5dcb", size = 276379, upload-time = "2025-12-04T14:23:30.498Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/43/ab/7ebfe34dce8b87be0d11dae91acbf76f7b8246bf9d6b319c741f99fa59c6/greenlet-3.3.0-cp312-cp312-manylinux_2_24_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:349345b770dc88f81506c6861d22a6ccd422207829d2c854ae2af8025af303e3", size = 597294, upload-time = "2025-12-04T14:50:06.847Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/a4/39/f1c8da50024feecd0793dbd5e08f526809b8ab5609224a2da40aad3a7641/greenlet-3.3.0-cp312-cp312-manylinux_2_24_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:e8e18ed6995e9e2c0b4ed264d2cf89260ab3ac7e13555b8032b25a74c6d18655", size = 607742, upload-time = "2025-12-04T14:57:42.349Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/77/cb/43692bcd5f7a0da6ec0ec6d58ee7cddb606d055ce94a62ac9b1aa481e969/greenlet-3.3.0-cp312-cp312-manylinux_2_24_s390x.manylinux_2_28_s390x.whl", hash = "sha256:c024b1e5696626890038e34f76140ed1daf858e37496d33f2af57f06189e70d7", size = 622297, upload-time = "2025-12-04T15:07:13.552Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/75/b0/6bde0b1011a60782108c01de5913c588cf51a839174538d266de15e4bf4d/greenlet-3.3.0-cp312-cp312-manylinux_2_24_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:047ab3df20ede6a57c35c14bf5200fcf04039d50f908270d3f9a7a82064f543b", size = 609885, upload-time = "2025-12-04T14:26:02.368Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/49/0e/49b46ac39f931f59f987b7cd9f34bfec8ef81d2a1e6e00682f55be5de9f4/greenlet-3.3.0-cp312-cp312-musllinux_1_2_aarch64.whl", hash = "sha256:2d9ad37fc657b1102ec880e637cccf20191581f75c64087a549e66c57e1ceb53", size = 1567424, upload-time = "2025-12-04T15:04:23.757Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/05/f5/49a9ac2dff7f10091935def9165c90236d8f175afb27cbed38fb1d61ab6b/greenlet-3.3.0-cp312-cp312-musllinux_1_2_x86_64.whl", hash = "sha256:83cd0e36932e0e7f36a64b732a6f60c2fc2df28c351bae79fbaf4f8092fe7614", size = 1636017, upload-time = "2025-12-04T14:27:29.688Z" },
|
||||
|
|
@ -1862,15 +1863,21 @@ wheels = [
|
|||
|
||||
[[package]]
|
||||
name = "markupsafe"
|
||||
version = "3.0.2"
|
||||
source = { registry = "https://download.pytorch.org/whl/cu129" }
|
||||
version = "3.0.3"
|
||||
source = { registry = "https://pypi.org/simple/" }
|
||||
sdist = { url = "https://files.pythonhosted.org/packages/7e/99/7690b6d4034fffd95959cbe0c02de8deb3098cc577c67bb6a24fe5d7caa7/markupsafe-3.0.3.tar.gz", hash = "sha256:722695808f4b6457b320fdc131280796bdceb04ab50fe1795cd540799ebe1698", size = 80313, upload-time = "2025-09-27T18:37:40.426Z" }
|
||||
wheels = [
|
||||
{ url = "https://download.pytorch.org/whl/MarkupSafe-3.0.2-cp312-cp312-macosx_10_13_universal2.whl" },
|
||||
{ url = "https://download.pytorch.org/whl/MarkupSafe-3.0.2-cp312-cp312-macosx_11_0_arm64.whl" },
|
||||
{ url = "https://download.pytorch.org/whl/MarkupSafe-3.0.2-cp312-cp312-manylinux_2_17_aarch64.manylinux2014_aarch64.whl" },
|
||||
{ url = "https://download.pytorch.org/whl/MarkupSafe-3.0.2-cp312-cp312-manylinux_2_17_x86_64.manylinux2014_x86_64.whl" },
|
||||
{ url = "https://download.pytorch.org/whl/MarkupSafe-3.0.2-cp312-cp312-manylinux_2_5_i686.manylinux1_i686.manylinux_2_17_i686.manylinux2014_i686.whl" },
|
||||
{ url = "https://download.pytorch.org/whl/MarkupSafe-3.0.2-cp312-cp312-win_amd64.whl" },
|
||||
{ url = "https://files.pythonhosted.org/packages/5a/72/147da192e38635ada20e0a2e1a51cf8823d2119ce8883f7053879c2199b5/markupsafe-3.0.3-cp312-cp312-macosx_10_13_x86_64.whl", hash = "sha256:d53197da72cc091b024dd97249dfc7794d6a56530370992a5e1a08983ad9230e", size = 11615, upload-time = "2025-09-27T18:36:30.854Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/9a/81/7e4e08678a1f98521201c3079f77db69fb552acd56067661f8c2f534a718/markupsafe-3.0.3-cp312-cp312-macosx_11_0_arm64.whl", hash = "sha256:1872df69a4de6aead3491198eaf13810b565bdbeec3ae2dc8780f14458ec73ce", size = 12020, upload-time = "2025-09-27T18:36:31.971Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/1e/2c/799f4742efc39633a1b54a92eec4082e4f815314869865d876824c257c1e/markupsafe-3.0.3-cp312-cp312-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:3a7e8ae81ae39e62a41ec302f972ba6ae23a5c5396c8e60113e9066ef893da0d", size = 24332, upload-time = "2025-09-27T18:36:32.813Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/3c/2e/8d0c2ab90a8c1d9a24f0399058ab8519a3279d1bd4289511d74e909f060e/markupsafe-3.0.3-cp312-cp312-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:d6dd0be5b5b189d31db7cda48b91d7e0a9795f31430b7f271219ab30f1d3ac9d", size = 22947, upload-time = "2025-09-27T18:36:33.86Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/2c/54/887f3092a85238093a0b2154bd629c89444f395618842e8b0c41783898ea/markupsafe-3.0.3-cp312-cp312-manylinux_2_31_riscv64.manylinux_2_39_riscv64.whl", hash = "sha256:94c6f0bb423f739146aec64595853541634bde58b2135f27f61c1ffd1cd4d16a", size = 21962, upload-time = "2025-09-27T18:36:35.099Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/c9/2f/336b8c7b6f4a4d95e91119dc8521402461b74a485558d8f238a68312f11c/markupsafe-3.0.3-cp312-cp312-musllinux_1_2_aarch64.whl", hash = "sha256:be8813b57049a7dc738189df53d69395eba14fb99345e0a5994914a3864c8a4b", size = 23760, upload-time = "2025-09-27T18:36:36.001Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/32/43/67935f2b7e4982ffb50a4d169b724d74b62a3964bc1a9a527f5ac4f1ee2b/markupsafe-3.0.3-cp312-cp312-musllinux_1_2_riscv64.whl", hash = "sha256:83891d0e9fb81a825d9a6d61e3f07550ca70a076484292a70fde82c4b807286f", size = 21529, upload-time = "2025-09-27T18:36:36.906Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/89/e0/4486f11e51bbba8b0c041098859e869e304d1c261e59244baa3d295d47b7/markupsafe-3.0.3-cp312-cp312-musllinux_1_2_x86_64.whl", hash = "sha256:77f0643abe7495da77fb436f50f8dab76dbc6e5fd25d39589a0f1fe6548bfa2b", size = 23015, upload-time = "2025-09-27T18:36:37.868Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/2f/e1/78ee7a023dac597a5825441ebd17170785a9dab23de95d2c7508ade94e0e/markupsafe-3.0.3-cp312-cp312-win32.whl", hash = "sha256:d88b440e37a16e651bda4c7c2b930eb586fd15ca7406cb39e211fcff3bf3017d", size = 14540, upload-time = "2025-09-27T18:36:38.761Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/aa/5b/bec5aa9bbbb2c946ca2733ef9c4ca91c91b6a24580193e891b5f7dbe8e1e/markupsafe-3.0.3-cp312-cp312-win_amd64.whl", hash = "sha256:26a5784ded40c9e318cfc2bdb30fe164bdb8665ded9cd64d500a34fb42067b1c", size = 15105, upload-time = "2025-09-27T18:36:39.701Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/e5/f1/216fc1bbfd74011693a4fd837e7026152e89c4bcf3e77b6692fba9923123/markupsafe-3.0.3-cp312-cp312-win_arm64.whl", hash = "sha256:35add3b638a5d900e807944a078b51922212fb3dedb01633a8defc4b01a3c85f", size = 13906, upload-time = "2025-09-27T18:36:40.689Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
|
|
@ -4578,9 +4585,9 @@ wheels = [
|
|||
|
||||
[[package]]
|
||||
name = "yt-dlp"
|
||||
version = "2026.3.3"
|
||||
version = "2025.12.8"
|
||||
source = { registry = "https://pypi.org/simple/" }
|
||||
sdist = { url = "https://files.pythonhosted.org/packages/66/6f/7427d23609353e5ef3470ff43ef551b8bd7b166dd4fef48957f0d0e040fe/yt_dlp-2026.3.3.tar.gz", hash = "sha256:3db7969e3a8964dc786bdebcffa2653f31123bf2a630f04a17bdafb7bbd39952", size = 3118658, upload-time = "2026-03-03T16:54:53.909Z" }
|
||||
sdist = { url = "https://files.pythonhosted.org/packages/14/77/db924ebbd99d0b2b571c184cb08ed232cf4906c6f9b76eed763cd2c84170/yt_dlp-2025.12.8.tar.gz", hash = "sha256:b773c81bb6b71cb2c111cfb859f453c7a71cf2ef44eff234ff155877184c3e4f", size = 3088947, upload-time = "2025-12-08T00:16:01.649Z" }
|
||||
wheels = [
|
||||
{ url = "https://files.pythonhosted.org/packages/7e/a4/8b5cd28ab87aef48ef15e74241befec3445496327db028f34147a9e0f14f/yt_dlp-2026.3.3-py3-none-any.whl", hash = "sha256:166c6e68c49ba526474bd400e0129f58aa522c2896204aa73be669c3d2f15e63", size = 3315599, upload-time = "2026-03-03T16:54:51.899Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/6e/2f/98c3596ad923f8efd32c90dca62e241e8ad9efcebf20831173c357042ba0/yt_dlp-2025.12.8-py3-none-any.whl", hash = "sha256:36e2584342e409cfbfa0b5e61448a1c5189e345cf4564294456ee509e7d3e065", size = 3291464, upload-time = "2025-12-08T00:15:58.556Z" },
|
||||
]
|
||||
|
|
|
|||
|
|
@ -1 +1 @@
|
|||
Subproject commit 2eeeba56e9edd762b4b38467bab96c2517163158
|
||||
Subproject commit 4979e04f5dcaccb36057e059bbaed8a2f5288315
|
||||
Loading…
Add table
Add a link
Reference in a new issue