52 lines
2.5 KiB
Markdown
52 lines
2.5 KiB
Markdown
|
|
# Analyser efficacement un fichier CSV
|
||
|
|
* 2020-02-20 15:17:02
|
||
|
|
* Développement
|
||
|
|
|
||
|
|
Je travaille régulièrement sur des traitements de fichiers CSV.
|
||
|
|
J'apprécie beaucoup ce format de fichier car il se génère et se lit
|
||
|
|
facilement, qu'on soit informaticien ou non. J'ai d'ailleur écrit 2
|
||
|
|
librairies PHP pour lire, générer et valider des CSV :
|
||
|
|
[deblan/csv](https://gitnet.fr/deblan/csv) et [deblan/csv-validator](https://gitnet.fr/deblan/csv-validator).
|
||
|
|
|
||
|
|
Lors des mes analyses, je me confronte parfois à des fichiers qui
|
||
|
|
comportent beaucoup de colonnes et c'est un enfer d'utiliser un tableur pour
|
||
|
|
visualiser et filtrer ces tableaux très larges.
|
||
|
|
|
||
|
|
Après quelques recherches, j'ai découvert deux projets qui se complètent à merveille !
|
||
|
|
Le premier est un outil qui transforme un fichier CSV en une base de données SQLite : [csvs-to-sqlite](https://pypi.org/project/csvs-to-sqlite/).
|
||
|
|
Le second génère une interface web (avec un serveur web intégré) pour faire
|
||
|
|
des requêtes SQL sur une base de données SQLite : [datasette](https://pypi.org/project/datasette/).
|
||
|
|
|
||
|
|
Ce sont des outils écrits en Python qui s'installent et s'utilisent en une poignée de secondes.
|
||
|
|
|
||
|
|
```{.language-bash data-title="Installation"}
|
||
|
|
$ sudo pip3 install csvs-to-sqlite datasette
|
||
|
|
```
|
||
|
|
|
||
|
|
Pour illustrer, je vais traiter le fichier CSV de la base officielle des codes postaux
|
||
|
|
disponible sur [data.gouv.fr](https://www.data.gouv.fr/fr/datasets/base-officielle-des-codes-postaux/).
|
||
|
|
|
||
|
|
```{.language-bash data-title="Installation"}
|
||
|
|
$ wget -O codes_postaux.csv https://datanova.legroupe.laposte.fr/explore/dataset/laposte_hexasmal/download/\?format\=csv\&timezone\=Europe/Berlin\&use_labels_for_header\=true
|
||
|
|
$ csvs-to-sqlite -s ";" codes_postaux.csv codes_postaux.db
|
||
|
|
$ datasette serve codes_postaux.db
|
||
|
|
Serve! files=('codes_postaux.db',) (immutables=()) on port 8001
|
||
|
|
INFO: Started server process [8550]
|
||
|
|
INFO: Waiting for application startup.
|
||
|
|
INFO: Application startup complete.
|
||
|
|
INFO: Uvicorn running on http://127.0.0.1:8001 (Press CTRL+C to quit)
|
||
|
|
```
|
||
|
|
|
||
|
|
On peut maintenant accéder à http://127.0.0.1:8001 depuis un navigateur et commencer
|
||
|
|
à analyer et traiter les données :
|
||
|
|
|
||
|
|
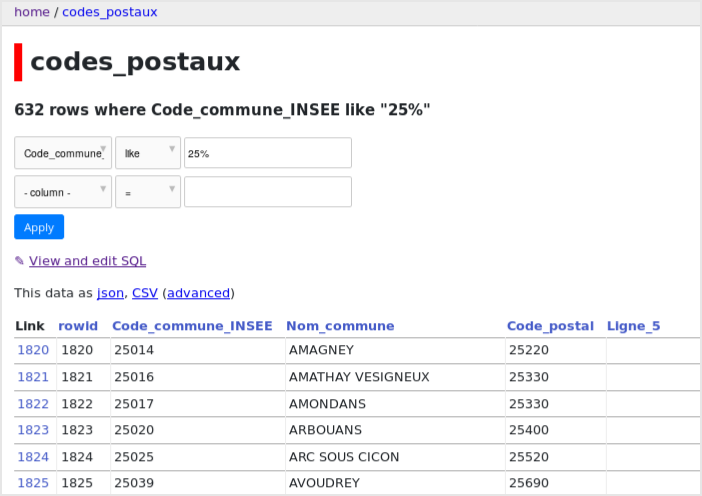
|
||
|
|
|
||
|
|
Et le plus intéressant pour moi, c'est de pouvoir écrire des requêtes SQL affiner
|
||
|
|
vraiment les données affichées :
|
||
|
|
|
||
|
|
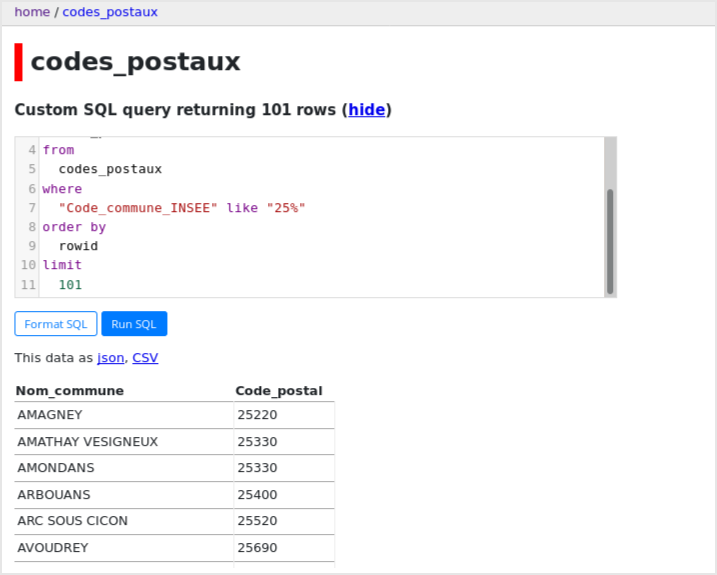
|
||
|
|
|
||
|
|
Enfin, on peut générer un nouveau fichier CSV (ou JSON) avec les données filtrées.
|
||
|
|
|
||
|
|
Simple, rapide et efficace !
|